
ELaTE is a zero-shot text-to-speech (TTS) system that can generate natural laughing speech from any speaker based on a speaker prompt to mimic the voice characteristic, a text prompt to indicate the contents of the generated speech, and an input to control the laughter expression.
ELaTE has the following key features:
- Precise control of laughter timing: A user can specify the timing for laughter, which critically affects the nuance of the generated speech.
- Precise control of laughter expression: A user can guide the laughter expression using an example audio containing laughter.
- Build upon a well-trained zero-shot TTS: ELaTE can generate natural speech without compromising audio quality and with a negligible increase in computational cost compared to the conventional zero-shot TTS model.
Generated laughing speech samples by ELaTE
Speech-to-speech translation

ELaTE can be applied to speech-to-speech translation, transferring not only the voice characteristic but also the precise nuance of the source audio with unprecedented quality.
Original speech (Chinese)
Generated speech (English)
Model overview
We develop ELaTE based on the foundation of conditional flow-matching-based zero-shot TTS, and fine-tune it with frame-level representation from a laughter detector as additional conditioning. With a simple scheme to mix small-scale laughter-conditioned data with large-scale pre-training data, we demonstrate that a pre-trained zero-shot TTS model can be readily fine-tuned to generate natural laughter with precise controllability, without losing any quality of the pre-trained zero-shot TTS model.

Audio samples
Below, we included audio samples demonstrating how ELaTE performs with various laughter instructions. The speech samples were taken from LibriSpeech test-clean and DiariST-AliMeeting dataset. The speech samples below are provided for the sole purpose of illustrating ELaTE.
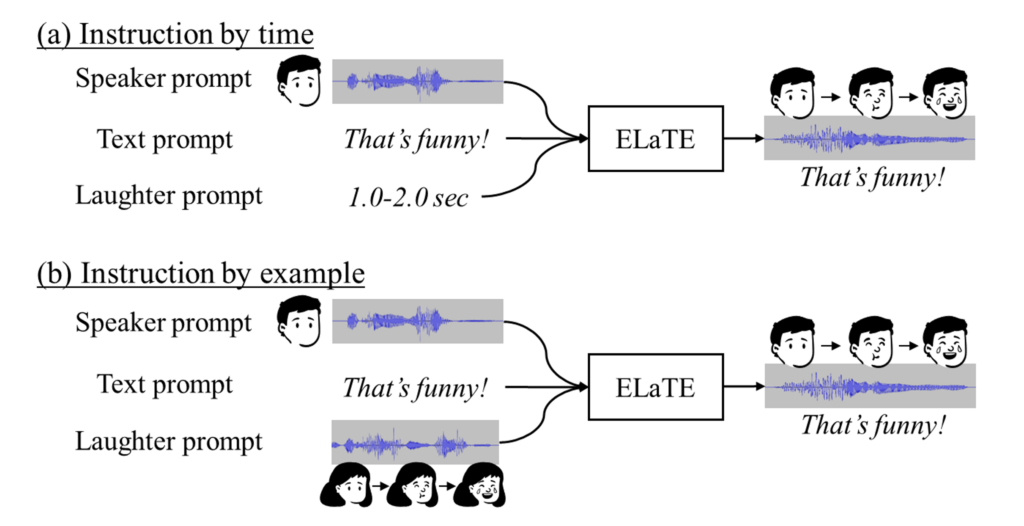
Instruction by time
ELaTE synthesizes speech in the voice characteristic specified by a speaker prompt, adding laughter at the specified timing.
| Text prompt | Speaker prompt | Laughter prompt | Generated speech |
|---|---|---|---|
| That’s funny! | 0.0–1.4 sec (first half of speech) | ||
| 1.4–2.8 sec (last half of speech) | |||
| No laughter | |||
| I didn’t see that one coming! | 0.0–2.0 sec (first half of speech) | ||
| 2.0–4.0 sec (last half of speech) | |||
| No laughter | |||
| I’m not sure whether to laugh or cry! | 0.0–2.2 sec (first half of speech) | ||
| 2.2–4.4 sec (last half of speech) | |||
| No laughter | |||
| You’ve got to be kidding me! | 0.0–1.8 sec (first half of speech) | ||
| 1.8–3.6 sec (last half of speech) | |||
| No laughter | |||
| Who let the dogs out? | 0.0–1.6 sec (first half of speech) | ||
| 1.6–3.2 sec (last half of speech) | |||
| No laughter |
Instruction by example
ELaTE synthesizes speech in the voice characteristic specified by a speaker prompt and incorporates the laughter style specified by a laughter prompt.
| Text prompt | Speaker prompt | Laughter prompt | Generated speech |
|---|---|---|---|
| That’s funny! | |||
| That’s what she said! | |||
| I’ve heard of air guitar, but this is ridiculous! | |||
| Well, that’s a plot twist! | |||
| I guess that’s one way to do it! |
Application for speech-to-speech translation
ELaTE can be applied to speech-to-speech translation, transferring not only the voice characteristic but also the precise nuance of the source audio.
| Source audio (Chinese) | Translated audio (English) | ||
|---|---|---|---|
| Seamless Expressive | Our baseline TTS | ELaTE | |
(*) The list of DiariST-AliMeeting laughter utterances we used for our evaluation, along with their transcription and translation, can be downloaded from https://www.microsoft.com/en-us/research/wp-content/uploads/2024/02/DiariST-AliMeeting-Laughter-Test-Set.txt under CC BY-SA 4.0 license.
(**) We used Seamless Expressive for a pure research purpose. Seamless Expressive was used based on the Seamless Licensing Agreement. Copyright © Meta Platforms, Inc. All Rights Reserved.
Ethics statement
ELaTE could synthesize speech that maintains speaker identity and could be used for educational learning, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chatbot, and so on. While ELaTE can speak in a voice like the voice talent, the similarity, and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.