

In recent years, as the shift toward agentic AI has accelerated, automation has advanced to handle increasingly complex tasks, from document and code generation to image creation, visual understanding, and mathematical reasoning. This trend points to the growing need to transform traditional software into intelligent agents. When core productivity platforms like Microsoft Office evolve into next-generation agents with autonomous reasoning and operational abilities, they can connect natural language and office automation in new ways, making work more efficient and precise.
One of the key challenges in this transformation lies in generating documents that are not only accurate in content but also well-structured and visually coherent. While most research has focused on improving text quality, the structural and stylistic dimensions of professional documents—layout, hierarchy, and readability—remain underexplored.
To address this gap, Microsoft Research Asia, in collaboration with The Chinese University of Hong Kong and the University of Chinese Academy of Sciences, has developed DocReward, a reward model that evaluates the structural and stylistic quality of AI-generated documents. By guiding agents to produce outputs that are clear, organized, and well-presented, DocReward provides crucial support for automated document creation.
Deep Research is an agent that gathers, analyzes, and synthesizes information from multiple sources into coherent, well-structured documents. Combined with DocReward, it completes a full workflow—from research and information integration to polished document presentation—laying the groundwork for transforming traditional office software into agent-driven systems.

Task modeling: Evaluating document structure and style
DocReward assigns quality scores to documents based on their layout and visual characteristics. For example, consider a set of documents, {Di}, where each document includes both its text content Dtext, i and corresponding rendered image Dimg, i. The reward model assigns scores to these documents to reflect their quality in terms of structure and stylistic presentation.
For a group of documents with identical content, the goal is for the reward model (Rθ) to predict scores in an order consistent with the true ranking of their structural and stylistic quality (π*). In doing so, the model learns to distinguish differences in layout and design even when the text remains the same, improving the accuracy of its evaluations.
Mathematically, this is expressed as the following:
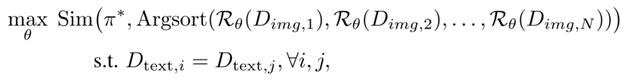
Definition of document structure and style professionalism:
- Structure: Proper use of whitespace and margins; clear section separation; consistent text alignment; paragraph spacing and indentation; standardized headers and footers; and overall logical organization.
- Style: Appropriate fonts (type, size, and color); readable heading hierarchy; effective use of bold and italics for emphasis; clear bullet and numbering formats; and consistent formatting throughout the document.
Constructing DocPair, the foundation for DocReward
To train DocReward, the research team built the DocPair dataset, which contains 117,000 document pairs spanning 32 domains and 267 document types. This diverse dataset enables the model to be optimized through preference learning to accurately assess structural and stylistic quality across a wide range of documents.
As shown in Figure 2, constructing the DocPair dataset involves three steps:
1. Curating high-quality professional documents
The team began by collecting a broad set of Microsoft Word files, ranging from formal institutional documents to routine business correspondence. Data sources include:
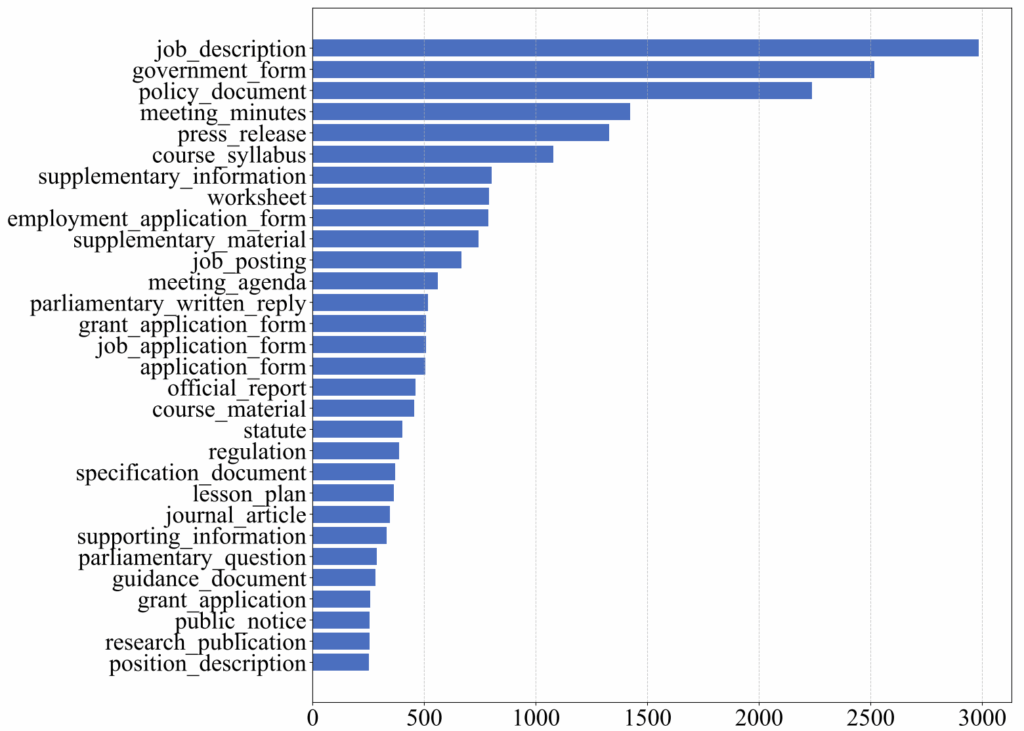
- Government and institutional documents, which make up the GovDocs1 and NapierOne datasets. GovDocs1 contains a wide range of U.S. government materials, including policy reports, administrative forms, statistical reports, meeting minutes, and more. NapierOne features office documents from public institutions, all characterized by strong structural and stylistic standards.
- Web documents, which consist of professionally authored files from the CommonCrawl database, spanning business, education, the nonprofit sector, and medicine. These include proposals, syllabi, newsletters, technical manuals, and policy briefs, contributing to broad diversity in document formats and presentation styles.
To ensure data quality, all documents were converted to .docx format and filtered to remove abnormal or incorrectly formatted files. The large language model (LLM) GPT-5 was then used to automatically score structure and style on a 0–10 scale, retaining only those scoring above 8.
The resulting dataset spans 32 domains and 267 document types and serves as the basis for subsequent document-pair construction. Figures 2 and 3 show the distribution of the top 10 domains and top 30 document types.

2. Expanding source documents via agents
To create document sets with identical text but varying structure and style, the team designed two types of document-generation agents:
- Text-to-document generation agent: Extracts plain text from source documents, removes all structural and stylistic information, and then uses advanced LLMs (GPT-4o, Claude Sonnet 4, GPT-5, etc.) to generate .docx documents through python-docx code.
- Structure and style optimization agent: Further refines the synthetic documents by referencing original human-written examples. This process involves two stages—first generating an optimization plan, then modifying .docx files via python-docx to improve structure and style.
3. Document ranking and annotation
Within each document group, all samples share the same text content. The team constructed two types of comparison pairs:
- Human vs. synthetic documents: When a pair includes a real human-written document, that version is labeled as more professional.
- Synthetic vs. synthetic documents: When both documents are synthetic, a human-written reference document is used as a guide, and GPT-5 annotates which synthetic version exhibits higher structural and stylistic quality.
The final DocPair dataset provides a solid foundation for training DocReward. When multi-page visual renderings are input to the vision encoder, a regression head is added to the language model. A special token is placed at the end of each image sequence, and its hidden state, processed by the regression head, predicts the document’s overall score.
Figure 4 illustrates the overall DocPair data construction process, summarizing the three main stages described above.

Training and evaluation
Training
DocReward is trained using the Bradley-Terry (BT) loss to learn from paired document preferences. Each document’s pages are input into the model, which outputs a score representing its structural and stylistic quality. The BT loss encourages DocReward to assign higher scores to preferred documents, helping it reliably distinguish differences in structure and style.
Mathematically, this is expressed as the following:

Experiments and evaluation
The research team conducted a series of experiments to test DocReward’s effectiveness in evaluating document structural and stylistic quality.
Experiment 1: Preference accuracy evaluation
Researchers randomly sampled high-quality documents to build an evaluation dataset that included both human-written and synthetic documents generated by various LLMs, ensuring diversity in structure and style.
For each group of documents with identical text but differing structure and style, experienced Word users familiar with document design ranked them by quality. These rankings were then converted into 473 document-pair comparisons, with each pair annotated to indicate which document was superior.
As shown in Table 1, DocReward achieved significant improvements over strong baselines, including GPT-4o, Claude Sonnet 4, and GPT-5.
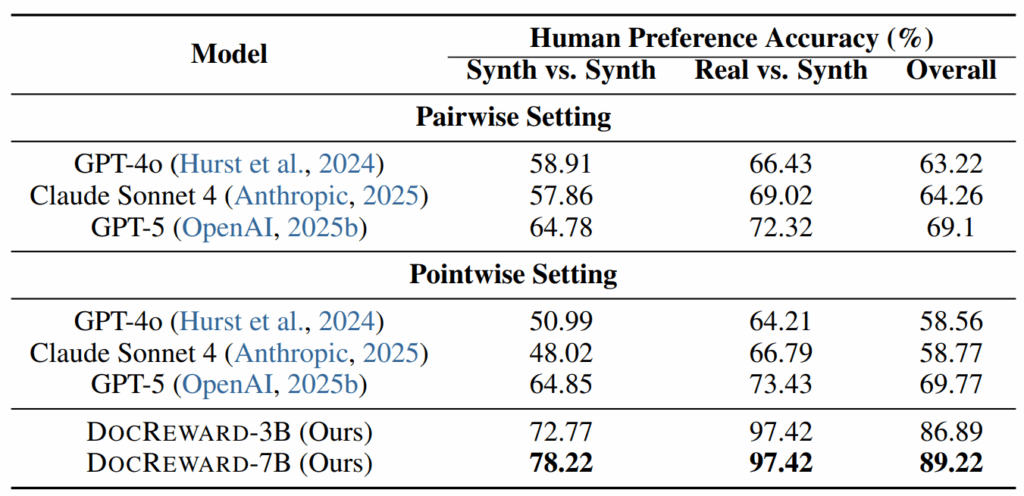
DocReward-7B (with 7 billion parameters) achieved an overall human-preference accuracy of 89.22%, outperforming the best proprietary baseline, GPT-5 (69.77%), by 19.45 percentage points. Even in the more challenging synthetic-vs.-synthetic setting, DocReward-7B maintained 78.22% accuracy, compared with GPT-5’s 64.85%.
These results show that DocReward accurately recognizes differences in document structure and style that existing LLMs often overlook.
Experiment 2: Improving document generation with DocReward
To assess DocReward’s impact on real document-generation tasks, the team ran experiments in which AI agents produced multiple candidate documents from the same text. Different reward models were then used to select the best-structured and best-styled version as the final output.
Three reward strategies were compared: random selection, GPT-5 as the reward model, and DocReward as the reward model. Human evaluators assessed each final document for structure and style, recording win/lose/tie ratios.
As shown in Figure 5, random selection performed the worst (24.6% win rate); GPT-5 improved performance to 37.7%; and DocReward achieved a 60.8% win rate and only a 16.9% loss rate, significantly outperforming both baselines.

To visually demonstrate DocReward’s ability to assess structure and style, the team conducted sample analyses using documents with identical text but differing layouts, as shown in Figure 6.

- Sample (a): The document has poor whitespace allocation: last-name field spacing is too small, and first-name field spacing is too large. This results in an unbalanced layout. Additionally, the key fields (Faculty/Department, Country, Country Code) are misaligned, creating visual clutter. The score is 1.21.
- Sample (b): The table-like layout of the document is more organized than that of Sample (a), but the heading font is too small, lacking a clear distinction from the body text and weakening the visual hierarchy. Additionally, the input fields lack borders, making information harder to interpret. The score is 2.11.
- Sample (c): The document features a clear, standardized structure, with a larger heading font, balanced whitespace, a well-aligned layout, and strong readability. The score is 5.34.
These examples show that DocReward accurately distinguishes differences in structural and stylistic quality, with scores consistent with human evaluations. Together, the experiments and sample analyses confirm that DocReward reliably guides agents to produce documents that aligned with human expectations for accuracy and presentation quality, supporting the agentic transformation of core office software like Microsoft Office.