
The problem: Confidence and reliability in agentic AI
AI agents are rapidly transforming software, with projections of over a billion agents in operation by 2028. These agents, embedded in products like VS Code and M365 Copilot, perform increasingly complex tasks—writing code, conducting research, and automating workflows. However, as agentic systems grow in complexity, understanding, debugging, and validating their behavior becomes a major challenge.
- Opaque reasoning: Agents operate through multi-step traces, making it hard to know what they were supposed to do and whether they did it correctly.
- Specification drift: Intended behaviors are often only partially specified, both explicitly (in prompts) and implicitly (in tool usage).
- Testing at scale: Manual evaluation is infeasible for thousands of agent traces across diverse domains and models.
Our solution: Agent-Pex
Agent-Pex is an AI-powered tool designed to systematically evaluate agentic traces and generate targeted agent tests. It builds on the insight that agent prompts and system instructions encode checkable rules—partial specifications that can be extracted and used for automated evaluation.
- Specification extraction: Agent-Pex parses agent prompts and traces to extract explicit and implicit behavioral rules (e.g., “When asked for your name, respond with ‘GitHub Copilot’”).
- Automated evaluation: Given a trace and a specification, Agent-Pex determines if any rules were violated, providing detailed reasoning and scoring (e.g., output_spec_eval_score: 95.0).
- Scalable analysis: Agent-Pex supports evaluation across thousands of traces, including those from commercial agents (VS Code) and academic benchmarks (Tau²).
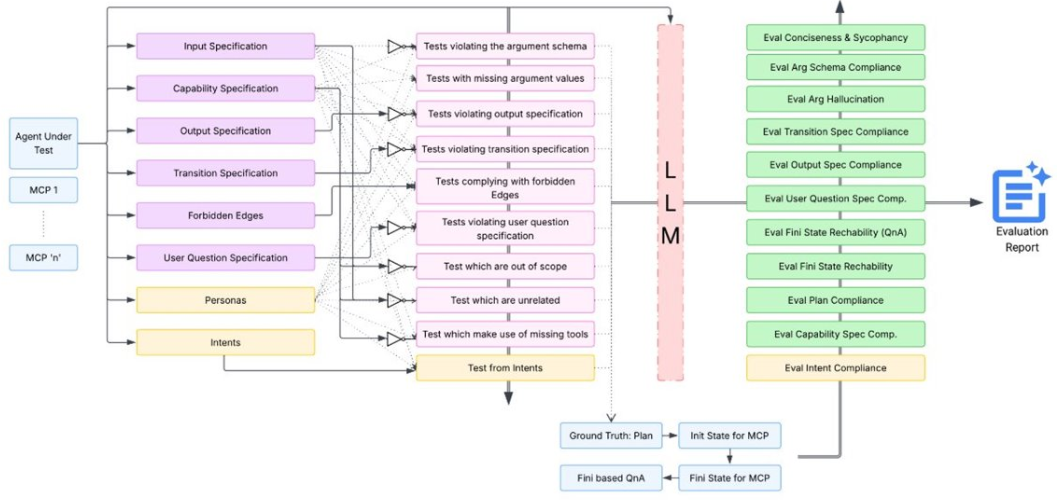
Features:
- Multi-dimensional coverage: Evaluates argument validity, output compliance, plan sufficiency, and more.
- Model comparison: Enables side-by-side analysis of agent traces from different models (e.g., Claude-4, Gemini-Pro, o4-mini).
- Integration with benchmarks: Supports large-scale evaluation using Tau², with over 5,000 traces across multiple domains.
Our contributions
Specification-driven, automated, and scalable
- Specification-driven evaluation: Unlike traditional testing, Agent-Pex leverages the rules embedded in agent prompts and traces, enabling precise, context-aware validation.
- Automated test generation: Building on prior work (PromptPex), Agent-Pex can invert rules to generate adversarial tests, systematically probing agent robustness.
- Scalability: Handles evaluation at enterprise scale, supporting both commercial deployments and academic research.
PromptPex connection: Agent-Pex builds on our prior work, PromptPex, which is an open-source tool for automatic test generation for language model prompts. Agent-Pex extends this approach to agentic traces, using specifications to generate tests that break rules and expose weaknesses.
Tau² benchmark integration: Agent-Pex can be used to evaluate agents on the Tau² benchmark, which simulates realistic multi-turn conversations in domains like telecom, retail, and airline. Tau² introduces dual-control environments, where both agent and user interact with tools, providing a rigorous testbed for agent coordination and reasoning.
Results
- Trace-level evaluation: Agent-Pex produces detailed reports for individual agentic traces, scoring compliance across multiple dimensions.
- Model comparison: Enables quantitative comparison of agent performance across models and tasks, revealing strengths and weaknesses.
- Benchmark-scale analysis: Successfully evaluated 5,000+ traces from Tau², comparing four models across three domains, with fine-grained analysis by domain and metric.
- Automated test generation: Demonstrated that tests generated by Agent-Pex (and PromptPex) are more effective at exposing prompt non-compliance than baseline approaches.
References
- PromptPex: Automatic Test Generation for Language Model Prompts (opens in new tab)
- microsoft/promptpex: Test Generation for Prompts (opens in new tab) – PromptPex repository
- Tau² Benchmark (opens in new tab)
- https://blog.sigplan.org/2024/10/22/prompts-are-programs/Prompts are Programs (opens in new tab)