
Goal: Kable is to extract structured knowledge from semi-structured Web site. Around 25% Web pages are of semi-structured, which contains lots of knowledge and are template generated web pages. Kable can learn the template across web pages and extract the knowledge. E.g. IMDB is a typical semi-structured web sites, which contains knowledge like movie name, director, runtime and so on.
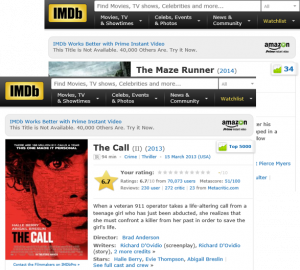
Challenge: large scale, lack training, cross language, frequent update
Solution: scalable unsupervised template learning across pages
Problem Definition:
- Input: semi-structured site
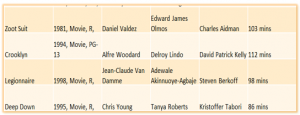
- Output: tabular data
- Basic idea: learning the variant and invariant part of page clusters [CIKM’12]
- Across pages generated by the same template
- The invariant parts are deemed as schema
- The variant parts are deemed as values

Algorithm:
- S1. Using URL pattern and tag path tree for page clustering
- S2. Template learning in each page cluster
- S3. Post processing and schema matching
Achievements:
- Ship to Satori: Http://Kable (opens in new tab)
- Processed all tier 0 and tier 1 sites in RetroIndex, encompassing 9Mil+ sites and 16Bil+ pages. From that, 16Bil+ pages were detected to have semi-structure data, containing 409Bil+ facets