

Editor’s note: AI programming is one of the great expectations that people have for artificial intelligence. Although current AI programming technology has benefitted many ordinary users who do not know how to program, it still has a long way to go to reach human-level. One weakness is that existing AI can only memorize, copy and paste mechanically, which renders it difficult to flexibly deal with people’s needs. The new neural model LANE (Learning Analytical Expressions) proposed by Microsoft Research Asia can simulate humans’ abstract way of thinking, thereby achieving compositional generalization capability in AI programming.
Let’s begin with AI Programming
Allowing AI to learn to write programs is a common hope that people have, where you can describe what you want using natural language, and AI would be able to automatically generate the corresponding program. Existing AI programming technology is not yet able to do this, but related technology, in more general forms, has already benefitted a large number of users without programming abilities in various fields. For example, Microsoft demonstrated a new feature in Excel at its Ignite 2019 Conference that enables Excel to automatically understand and perform intelligent data analysis when a user asks a question, and then to present the results in visual charts (as shown in Figure 1) [1]. The technical support behind this super practical function is a series of AI programming technologies that convert natural language into data analysis programs. Another example is the intelligent dialogue service developed by Microsoft’s Sematic Machines team, built precisely on program synthesis [2].
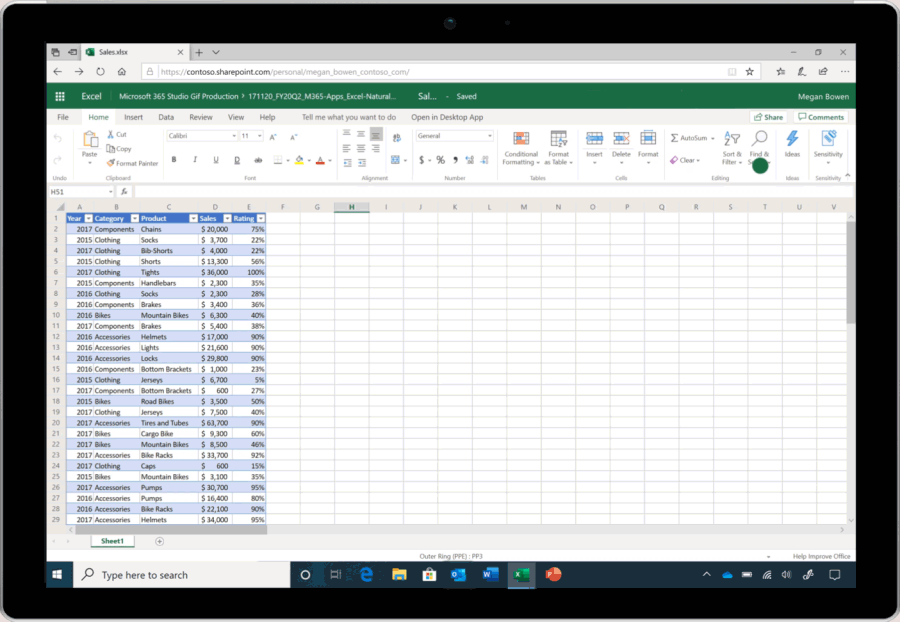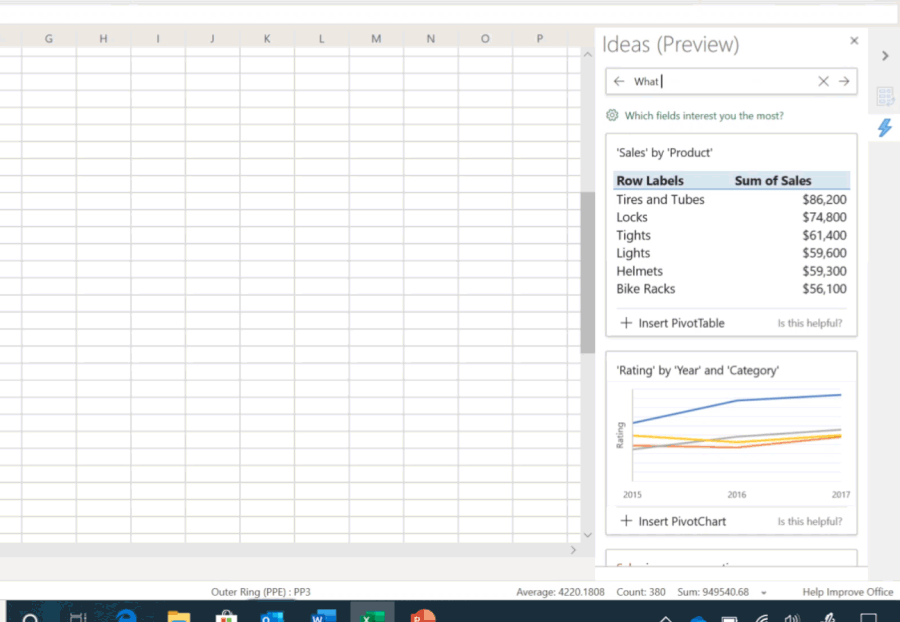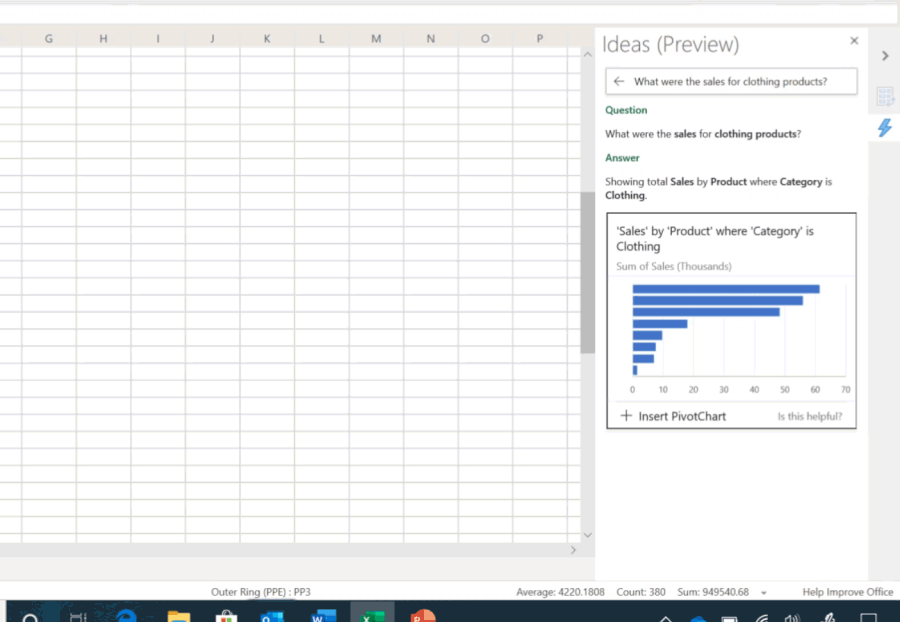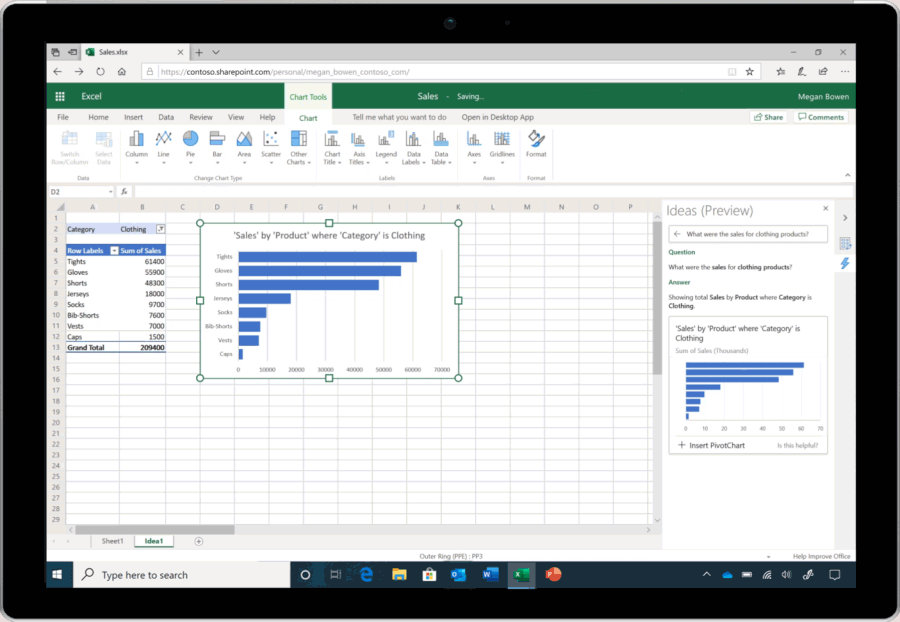
Figure 1: Conversational data analysis in Excel based on AI programming technology
The AI programming technology discussed in this article refers to using a natural language sentence as the input and obtaining a corresponding machine interpretable/executable program as the output. Here program is usually written by a known DSL (Domain Specific Language). Researchers in the field of natural language processing may be more familiar with another term for this task: semantic parsing.
However, even with such restrictions, existing AI programming technology still does not always deliver satisfactory results. One major weakness is that the AI technology seems to have only learned how to memorize, copy and paste mechanically using the known code base but cannot generate truly suitable programs to flexibly serve people’s needs.
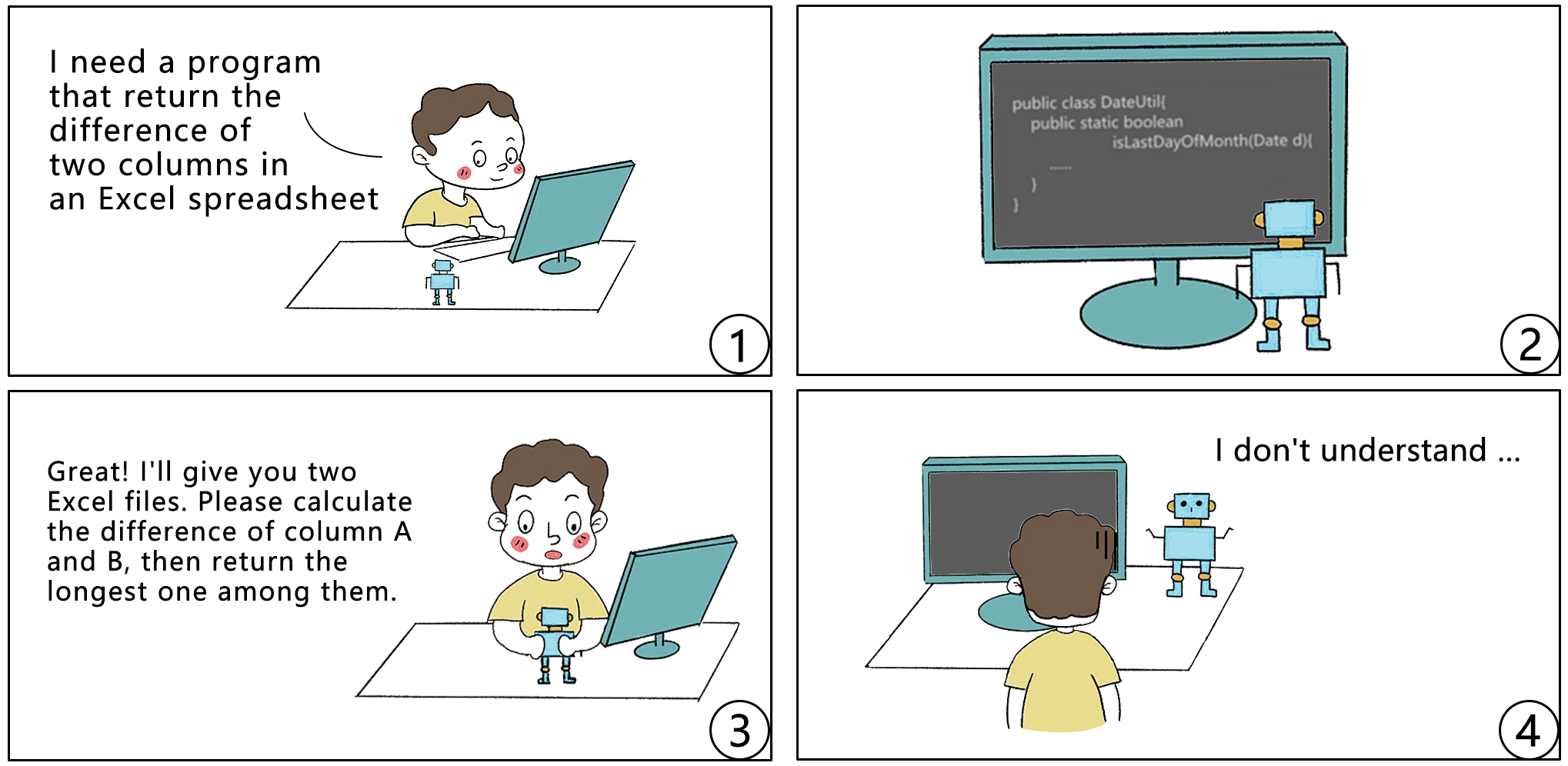
Figure 2: The current state of AI programming
Take the comic in Figure 2 as an example (adapted from [3]). When a user’s requirements are relatively simple and the AI programming robot is able to find a program that can fulfill the requirements in a large code base, the results are generally good. However, if the user’s requirements are relatively complex, the robot needs to have a certain level of reasoning capabilities (i.e., the required program does not exist in known code bases, and composing needs to be carried out on parts of existing programs). In such cases, the results are usually unsatisfactory.
The research work covered in this article uses this as a starting point and aims at exploring how AI programming can be made to go beyond copying and pasting and learn human-like reasoning capabilities, so as to more effective in synthesizing programs.
Compositional generalization is the key to creating humanoid AI
The core to the problem discussed in the previous section of the article can be attributed to the issue of achieving “compositional generalization” capability in AI systems. Put more plainly, the issue is whether the AI system has the ability to draw inferences, where it’s able to decompose known complex objects (i.e. the “program” discussed in this article) into a composition of multiple known simple objects, then understand/generate unknown combination of these known simple objects accordingly.
Humans have a natural ability to carry out compositional generalization. For example, take a person who has never been exposed to the concept of a platypus. He only needs to look at a photo of a platypus to identify it, and afterwards, he would be able to understand certain complex phrases with a picture in mind, such as, “Three platypuses are sitting side by side holding eggs,” or “Two platypuses have started digging by the shore after catching small fish in the river,” and so on. This is very different from deep learning, which requires a great amount of annotated data even just to learn the concept of a platypus, never mind learning various complex combination of the concept.
From a linguistics perspective, the compositional generalization capability of human is mainly reflected in systematicity and productivity. Systematicity can be simply understood as the local replacement of known expressions. For example, if a person understands the word “platypus” and the phrase “a dog in the living room,” then he is also able to understand the phrase “a platypus in the living room.” Productivity can be simply understood as the construction of more complex expressions with relatively simple expressions through potential universal laws. For example, if a person understands the word “platypus” and the clause “a dog in the living room,” then he is also able to understand the phrase “a platypus and a dog in the living room.”
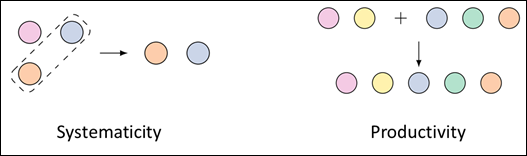
Figure 3: Compositional generalization capability is mainly reflected in systematicity and productivity (image source: https://arxiv.org/pdf/1908.08351.pdf)
Linguist and philosopher Chomsky describes language as a system that makes “infinite use of finite means.” Human intelligence has relied on compositional generalization to gradually create a complex and even infinite world of semantics using the most basic elements. It can be said that compositional generalization is a basic ability that humanoid AI must possess.
Deep learning lacks compositional generalization capability
Programs are compositional. Even a small DSL (limited domain, simple grammar, and limited redefined functions) can produce an exponentially large program space. The programs included in the training data set are only the tip of the iceberg in any program space. Therefore, if an AI programming robot lacks compositional generalization capability, it would inevitably lead to instances of “artificial mental retardation” as reflected in the comic above.
Considering this perspective, an increasing number of research works are beginning to re-examine existing deep learning-base AI programming solutions. Most of current mainstream solutions are based on Neural Encoder-Decoder Architectures. A series of studies conducted by New York University professor Brenden Lake and Facebook AI scientist Marco Baroni have shown that existing deep learning models do not have compositional generalization capability [4]. Figure 4 briefly illustrates their research method. The experimental task is to translate natural language phrases such as “run after walk” into instruction sequences (programs) such as “WALK RUN.”
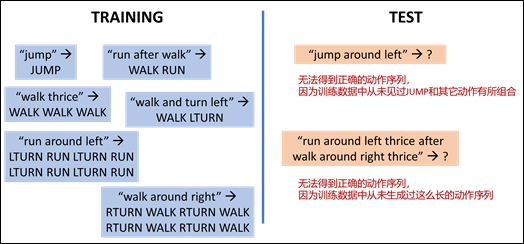
Figure 4: It’s difficult for existing deep learning models to generalize to combinations outside the training set, even for simple tasks.
On the surface, this appears to be a simple sequence-to-sequence generation task. A large number of natural language phrases and their corresponding instruction sequences are collected and randomly divided into a training set and a test set, then an existing deep learning model is used for training, allowing up to 99.8% accuracy on the test set. However, once restrictions are added to the division method between the training set and the test set from a compositional perspective, the deep learning model is no longer effective. For example, in order to verify the systematicity of the model, we can prevent the model from seeing any sample related to “jump” except for “jump -> JUMP”. And then in the testing phase, we can evaluate if the model can perform correctly with phrases including “jump” (e.g. “jump around left”). Experimental results show that under such a setting, the deep learning model can only achieve an accuracy rate of 1.2%.
On the other hand, in order to verify the productivity of the model, we can only expose the model to samples with an instruction sequence length of less than 24 during the training phase, and then in the testing phase, we can see if the model can correctly generate an instruction sequence with a length no less than 24. Experimental results have shown that under such a setting, the deep encoder-decoder network can only achieve an accuracy rate up to 20.8%. A series of similar studies demonstrate that existing deep learning models do not have the ability for compositional generalization in semantic parsing tasks [4][5].
In current industrial practices, practitioners mainly use a hybrid system of deep learning and heuristic rules to alleviate this bottleneck (data augmentation can also be included, since deciding what data needs to be augmented usually requires manual induction.) This article seeks to explore a more interesting idea, which is if it would be possible to introduce appropriate inductive biases in deep learning to get rid of simple memory and imitation without introducing heuristic rules, but rather to automatically explore, discover, and summarize the inherent compositional laws of the dataset, so as to endow the end-to-end deep neural network with compositional generalization capability.
Simulating the abstract thinking of human brains in a deep neural network
Human cognition is capable of compositional generalization in large part because of abstraction, that is, omitting the specific details of things to reduce the amount of information contained in them, which is more conducive to discovering the common ground (laws) between things.
This ability for abstraction is a type of algebraic ability, which is precisely what existing deep neural networks lack. As shown in Figure 5 on the left, existing deep neural networks are more inclined towards memorization for AI programming tasks. Natural language and programming language are regarded as two separate sets, so what’s learned are only simple mapping between specific natural language phrases and specific programs. It would thus be difficult to realize compositional generalization. To tackle this problem, the key idea is to treat natural language and programming as two algebraic structures, and the deep neural network needs to incline towards learning the homomorphism between these two algebraic structures (as shown in Figure 5 on the right).
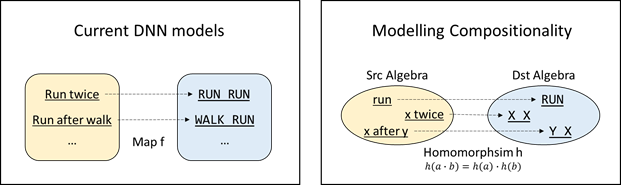
Figure 5: Learning the homomorphism between algebraic structures rather than learning the mapping between sets
Put more expressly, if the training data already contains samples such as “run opposite walk,” “run after left,” and “walk twice,” we are now presented with the following example:
INPUT: “run opposite left after walk twice”
OUTPUT: “WALK WALK LTURN LTURN RUN”
Existing deep learning models are to remember the mapping between such input and output pairs, while human cognition tends to make abstractions as shown in Figure 6.

Figure 6: Compared with the direct memorization and imitation of deep learning, human thinking is more inclined to take concrete objects and abstract them hierarchically into common analytical expressions.
The left side of Figure 6 shows the abstraction process of the natural language sentence used as input from the bottom to up. In steps 1,2, and 4, the specific meanings of the three words “run,” “left,” and “walk” are stripped off respectively and abstracted into variables. In steps 3, 5, and 6, the meanings of the three clauses “$x opposite $y,” “$y twice” and “$x after $y” are stripped off respectively and are also abstracted into variables. What humans remember is not the direct mapping between input and output, but the collection of local mappings (shown in Figure 6 on the right) produced at each step of this abstraction process. For example, in step 1, the word “run” is mapped to the program “RUN”; in step 3, the abstract clause “$x opposite $y” is mapped to the program “$Y $Y $X.” The “$X” here is a variable in a program, referring to the program corresponding to the variable “$x” in natural language.
The above example illustrates that rather than directly remembering relatively complex and specific mappings, humans are more inclined to generalize relatively simple common abstract mappings from them, thereby obtaining compositional generalization capabilities. Therefore, in order to also endow compositional generalization capabilities to deep learning models, it is necessary to design a new neural model that can simulate the abstraction process in human cognition.
Formalizing each specific input/output object is called Source Expression (SrcExp) /Destination Expression (DstExp), which is collectively referred to as Expression (Exp). If one part or some parts of the expression is/are replaced with variables, the expression would be called an Analytical Expression (AE). Similarly, analytical expressions can also be divided into Source Analytical Expressions (SrcAE) and Destination Analytical Expressions (DstAE).
The neural model needs to gradually transform each input SrcExp into a simpler SrcAE through several abstract operations (as shown in Figure 6 on the left). In this abstraction process, every SrcAE that is replaced with a variable is parsed as a DstAE. In the end, these DstAEs are composed into a DstExp as the output (as shown in Figure 6 on the right). The model requires the use of this abstraction process as a type of inductive bias, completing the exploration and study of the specific abstraction process and expression mapping in a fully automated process, without relying on any artificially predefined abstraction/mapping rules.
Model implementation of LANE
The new neural model LANE (Learning Analytical Expressions) can simulate human abstract thinking in semantic parsing tasks, thereby achieving compositional generalization. In previous neural network learning frameworks, the neural network is directly used to learn the mapping function from a Source Token Sequence to a Destination Token Sequence. In LANE, what needs to be learned is a function whose source domain and target domain are respectively derived from the abstraction of the source token sequence and the analytical expression of the destination token sequence.
LANE consists of two neural network modules. One module is called Composer and is implemented by a TreeLSTM model. It is responsible for the latent tree induction of the input SrcExp, thus delivering a gradually abstracted and simplified intermediate SrcAE. The other module is called Solver and is responsible for performing local semantic parsing every time abstraction occurs, stripping the semantic details and storing them in Memory, so that these details are simplified to a variable in subsequent processing.
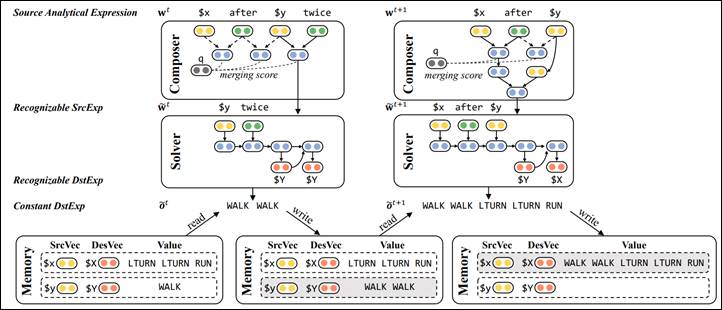
Figure 7: Use neural networks to learn implicit analytical expressions to simulate human abstract thinking
Figure 7 explains the workflow of LANE and also shows how it handles the fifth and sixth steps of abstraction in Figure 6. In the fifth step, Composer outputs the next abstract action based on the LSTM for the current SrcAE “$x after $y twice”; “$y twice” should be abstracted. Solver uses a deep encoder-decoder network to interpret “$y twice” as DstAE “$Y $Y” and compose it with “$Y = WALK” in the original memory to obtain DstExp “WALK WALK” corresponding to the new variable, and update the memory accordingly. After this process, the details of “$y twice” in “$x after $y twice” are stripped off, forming a more abstract SrcAE “$x after $y,” after which the sixth step of abstraction can proceed. This way, Composer and Solver work together, allowing LANE to gradually abstract the input SrcExp into an increasingly simplified SrcAE until it forms the simplest SrcAE composed of a single variable. The corresponding value of this variable in the memory is the final output DstExp.
Since LANE contains operations that not differentiable, the training of the model can be realized based on reinforcement learning. Model training has the following three key points:
- Reward design: Reward is divided into two parts: one part is based on similarity, that is, the degree of sequence similarity between the DstExp generated by the model and the real DstExp. The other part is the reward based on simplicity, which is inspired by Occam’s razor principle and is used to encourage the model to generate more general/concise analytical expressions. Since there was no deliberate introduction of any special task-related knowledge in the design of these two rewards, this shows that LANE likely has great universality.
- Hierarchical Reinforcement Learning: Composer and Solver work together, but they have different positioning. Solver’s decision depends on Composer’s decision. Therefore, regarding Composer and Solver as a high-level agent and a low-level agent respectively, hierarchical reinforcement learning is applied to jointly train these two modules.
- Curriculum Learning: In order to enhance the efficiency of exploration, the data is divided according to the length of input sequence into multiple courses ranging from simple to difficult. The model is first trained on the simplest course, and then more difficult courses are gradually added.
Experimental Results
Lake et al. established a benchmark dataset called SCAN to evaluate the compositional generalization capability of semantic parsing systems. Multiple subtasks are derived from this data set to measure compositional generalization capabilities with regards to different aspects. For example, the ADD_JUMP subtask is used to measure the model’s ability to handle a composition of newly introduced elements; and the LENGTH subtask is used to measure the model’s ability to generate compositions that exceed known lengths in the training data. Research and experimental results show that LANE has reached 100% accuracy on these subtasks.
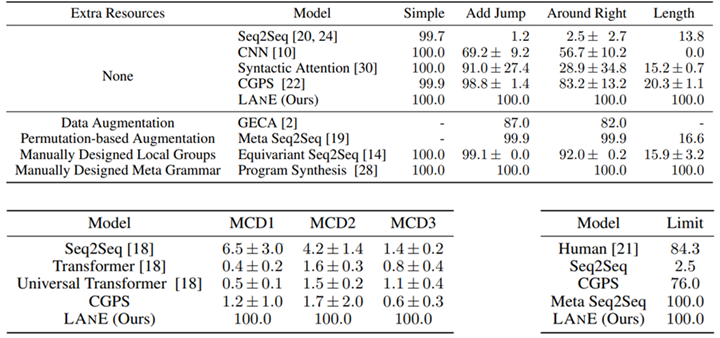
Figure 8: LANE achieves 100% accuracy in all SCAN’s subtasks
Figure 9 shows two implicit tree structures learned by Composer (TreeLSTM) in LANE as an example. TreeLSTM is bifurcated in implementation, and the nodes that perform abstract actions are colored black. It can be seen that even without introducing any predefined abstraction/mapping rules, LANE can automatically explore the abstraction process that conforms to human thinking.

Figure 9: Example: Two implicit tree structures learned by LANE
The new end-to-end neural model LANE can simulate human abstract thinking ability to learn the potential analytical expression mapping in the data, so as to obtain the compositional generalization ability in the AI programming (semantic parsing) task. Researchers at Microsoft Research Asia hope to use this as a starting point to explore how deep learning can go from the “parrot paradigm” (memorization and imitation) to the “crow paradigm” (exploration and induction), thereby expanding the boundaries of its capabilities. However, this is still preliminary theoretical research, and a great amount of follow-up work needs to be done in order to apply it to more complex tasks (such as improving training efficiency, improving fault-tolerant learning ability, combining with unsupervised methods, etc.).
Paper: https://arxiv.org/abs/2006.10627
Code: https://github.com/microsoft/ContextualSP