Objective Metrics
In our audio/video test calls, video transmission starts few seconds after the beginning of the call. During this initial period, only audio packets and probing packets flow from the sender to the receiver. Consequently, video quality is not defined during this period, which is the reason why the provided objective video quality signal for each test call begins with a sequence of nan values. Another point to keep in mind is that the flow rate of audio packets in this initial period is typically much less than the capacity of the bottleneck link. During this period, different behavior policies adopt different ramp up strategies to estimate the available bandwidth.
Asymmetric RL
In asymmetric RL, the agent has access to extra information during training that is not available at test/deployment time. Because the emulated dataset contains ground truth information (loss rate, capacity) for the bottleneck link, ideas from asymmetric RL and optimization objectives with auxiliary losses can be leveraged to train the policy. Furthermore, ground truth information can be helpful to design and train representation learning architectures to facilitate bandwidth estimation. That said, ground truth information cannot be used as additional inputs to the model since in practice, this information is unknown. Any model which has ground truth information in the inputs will be disqualified from the contest.
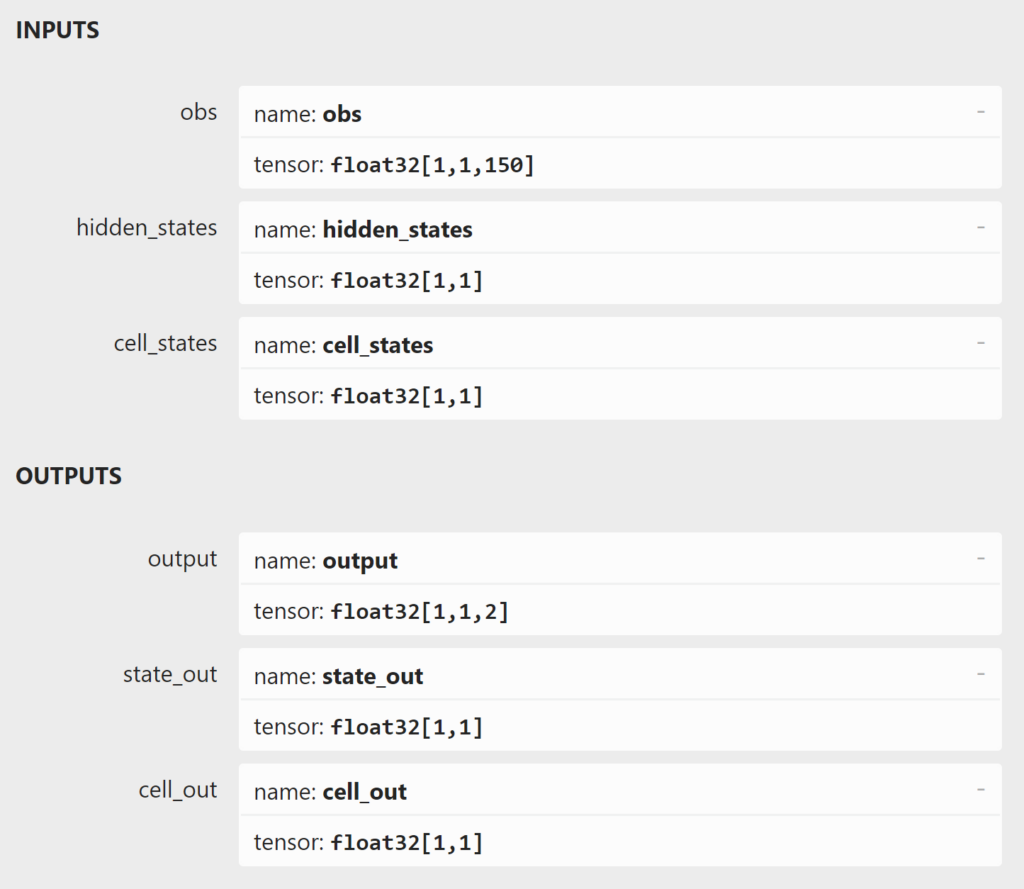
Onnx model Input/Output Shapes
As per the challenge requirements, submitted ONNX models should have the following input shapes:
- obs: float32[1,1,150]
- hidden_states: float32[1,N], N can be any positive integer, e.g. float32[1,128] or float32[1,1]
- cell_states: float32[1,N], N is the same as for the input hidden states dimension
Even if the model does not make use of the hidden/cell states, these inputs should still be passed as inputs to the model and returned as outputs. On the other hand, the outputs should have the following shapes:
- output: float32[1,1,2]
- state_out: float32[1,N], N is the same as for the input hidden states dimension
- cell_out: float32[1,N], N is the same as for the input cell states dimension
Importantly, the output should be the mean predicted bandwidth and the standard deviation of the prediction, hence the shape is [1x1x2]. If the training method does not learn the standard deviation by design, a constant value can be appended to conform to the required shape ([1x1x2]). When the model is evaluated online, only the mean predicted bandwidth in bps is used and the standard deviation is ignored. Furthermore, dynamic axes for the batch and sequence length dimensions are not supported. Hence, batch_size = 1 and seq_len = 1. Input/output shapes of ONNX models can be inspected using a neural network visualizer like Netron (opens in new tab) which for the released baseline model (opens in new tab) look like the following: