

By Ben Finkelshtein (opens in new tab) (University of Oxford), Silviu Cucerzan, Sujay Kumar Jauhar, and Ryen W. White (Microsoft)
Think about the last time you opened a shared document at work. Behind that simple action lies a complex network of relationships: the colleagues who edited the file before you, the team site on which it is stored, the related documents those collaborators have touched, and the organizational structure connecting all of it. Such collaborative platforms are built on graphs – rich networks of people, content, and activity. A fundamental challenge in making them intelligent is understanding what each node in that graph represents. Should this document be flagged as sensitive? Which files should surface in a colleague’s feed? Does this sharing pattern look anomalous?
These are all instances of node classification: given an entity embedded in a network of relationships, the goal is to assign it a meaningful label. It’s a problem that extends far beyond human collaboration to applications such as fraud detection in financial networks, product categorization in e‑commerce, and road traffic congestion prediction. And it’s a problem where large language models (LLMs) are increasingly being applied.
The appeal for using LLMs is clear. Graph neural networks (GNNs), the traditional tool for this task, must be trained per dataset, don’t transfer across domains, and struggle with the rich textual information that real-world nodes often carry – lengthy document content, detailed product descriptions, user profiles. By contrast LLMs offer a compelling alternative with their broad world knowledge and flexible reasoning capabilities. Yet despite a surge of interest, the field has lacked a principled understanding of how LLMs should interact with graph data, when different approaches work best, and why.
Our new study, “Actions Speak Louder than Prompts (opens in new tab),” – which will appear as an oral presentation at the upcoming ICLR 2026 conference – aims to fill that gap. We conducted one of the largest controlled evaluations of LLMs for graph inference to date, spanning 14 datasets across four domains, multiple structural regimes, and a range of model sizes and capabilities. The result is a set of practical, actionable insights for people building systems that combine language models with structured data – whether in collaborative platforms, social networks, e-commerce, or beyond.
It’s not just what you ask; it’s how you let the model work
When most people think about applying LLMs to a problem, they think about prompting – crafting the right instructions and feeding the relevant information directly into the model’s context window. This is indeed the most common approach in the LLM-for-graphs literature: serialize a node’s neighborhood into text, describe the labels, and ask the model to classify.
However, prompting is only one way an LLM can interact with a graph. To paint a more complete picture of LLM interaction paradigms, we systematically compared three fundamentally different strategies:
- Prompting, where the graph neighborhood is serialized into text and presented to the model in a single shot.
- GraphTool, a ReAct-style approach where the model iteratively queries the graph through a fixed set of tools by retrieving neighbors, reading features, or checking labels one step at a time.
- Graph-as-Code, where the model writes and executes short programs against a structured API, composing arbitrary queries over the graph’s features, structure, and labels.
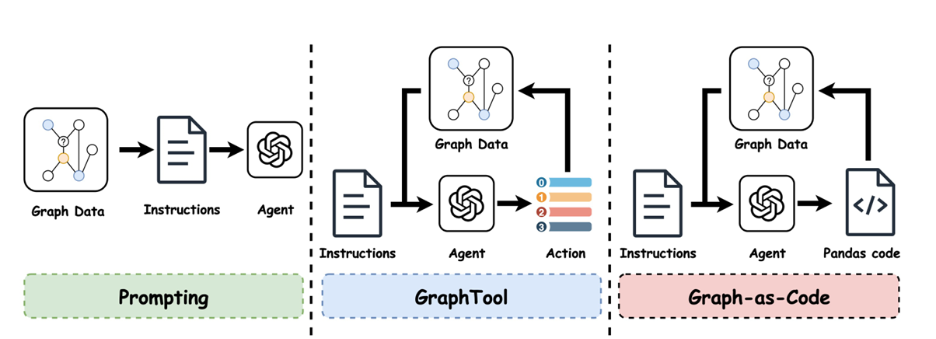
The progression from prompting to tool use to code generation represents a spectrum of increasing agency, from passively consuming information to actively deciding what to look at and how to process it. Our core finding is that this agency matters. As models are given more flexibility in how they interact with the graph, classification accuracy consistently improves.
Letting LLMs write code over graphs
The standout performer across our evaluation was Graph-as-Code. Rather than constraining the model to a fixed set of retrieval actions or requiring all information to be packed into a prompt, this approach lets the LLM compose targeted programs by combining structural queries, feature lookups, and label checks in whatever way it deems most useful for the node at hand. You can see these results in the table below where performance across long-text homophilic datasets highlights the gap between Prompting and Graph-as-Code, especially on high-degree graphs like wiki-cs.
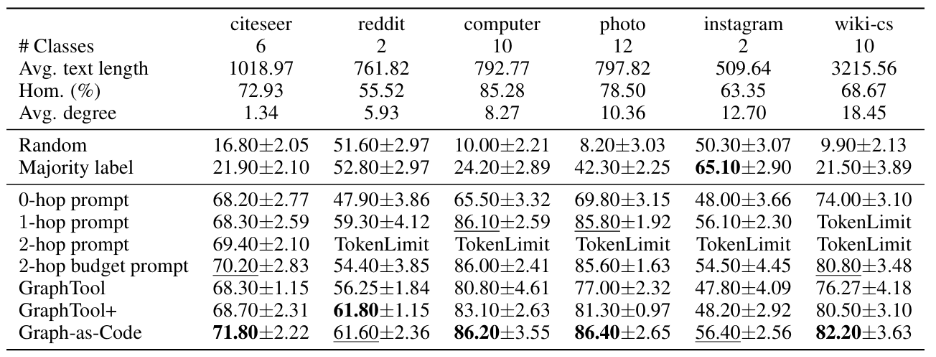
This advantage is especially pronounced in settings that mirror real-world complexity. Consider a collaborative platform where content nodes carry lengthy document text and are densely connected through sharing, co-authorship, and organizational links, or as another example, e-commerce network where product nodes have detailed descriptions and hundreds of connections. A prompting approach quickly hits the LLM’s context window limit because there is simply too much text from too many neighbors to fit. Graph-as-Code sidesteps this issue entirely: the model selectively retrieves only the information it needs, keeping its context focused and efficient.
In practice, the most valuable real-world graph applications tend to involve exactly this kind of dense, text-rich network. Collaborative content graphs, recommendation systems, fraud detection networks, social platforms aren’t small, sparse toy problems, but rather large-scale networks where nodes carry rich information and have many connections. For practitioners building intelligent features over these graphs, our findings suggest that investing in code-generation interfaces for LLMs may yield substantially better outcomes than refining prompts.
Challenging conventional wisdom on graph structure
A common conclusion and conception, cited in many publications in the LLM-for-graphs literature, is that these models struggle on heterophilic graphs – networks where connected nodes tend to have different labels rather than similar ones. The intuition is straightforward: if an LLM relies on neighborhood cues to classify a node, and those cues are misleading (because neighbors belong to different classes), performance should suffer.
In collaborative platforms, people frequently work across organizational boundaries – an engineer collaborates with a designer, a finance team shares documents with marketing. The resulting graphs don’t have the neat clustering that homophily assumes. The same is true of networks of web-page links, interdisciplinary research, and many social networks.
Our results tell a different story. Across four heterophilic datasets all three LLM interaction strategies performed well, consistently outperforming classical baselines like label propagation. Our results challenge the assumption that LLMs are inherently limited to homophilic settings and suggest they can extract useful signal from node features and non-local patterns, rather than relying solely on neighborhood voting.
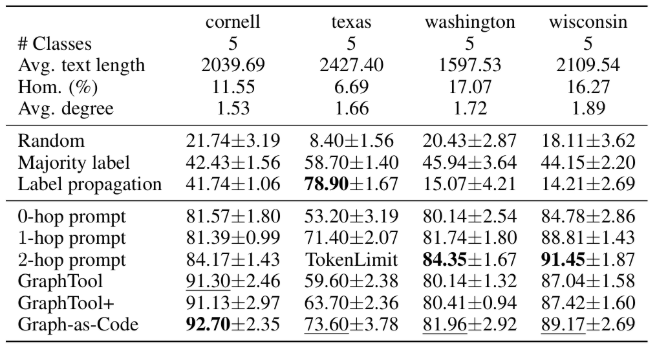
This broadens the applicability of LLM-based graph reasoning to the messy, cross-cutting networks that real-world systems operate on.
Understanding what LLMs rely on
Beyond overall accuracy, we wanted to understand how these models use different types of information. Do they lean on textual features? Graph structure? Known labels? And does this change depending on the interaction strategy?
To answer this, we ran a series of controlled ablations – systematically removing edges, truncating text features, and deleting labels – and tracked how accuracy responded. The results, visualized as 2D heatmaps, revealed a striking contrast.
Prompting degrades predictably: remove edges or labels, and accuracy drops along both axes. The model needs both structure and labels to function, and it has no way to compensate when either is degraded.
Graph-as-Code, by contrast, displays a remarkable adaptability. On homophilic datasets where structure is informative, it relies on edges. On heterophilic datasets where features matter more, it shifts to text. When labels are removed but features and structure remain, it is barely impacted. Performance only suffers when multiple sources of information are simultaneously degraded.
This adaptive behavior is a key property of the code-generation paradigm. Because the model can compose arbitrary queries, it naturally gravitates toward whichever signal is most informative for the task at hand – a kind of emergent robustness that doesn’t need to be explicitly engineered. For systems operating over real-world data, where information is often incomplete or noisy, this resilience is especially valuable.
Design principles for LLM-graph systems
Our study yields several practical guidelines for building systems that combine LLMs with graph-structured data:
Match the interaction mode to the graph’s characteristics. For small, sparse graphs with short text features, prompting may suffice. But as graphs grow denser, features grow longer, or the application demands robustness, code-generation approaches like Graph-as-Code offer clear advantages.
Don’t rule out LLMs for heterophilic graphs. Prior assumptions about LLM limitations in low-homophily settings appear to be an artifact of studying only the prompting paradigm. With the right interaction strategy, LLMs are effective across structural regimes, including the cross-cutting, boundary-spanning networks common in collaborative and organizational settings.
Think beyond prompt engineering. In graph applications, how the model accesses information matters at least as much as what instructions it receives. Investing in richer interaction interfaces – tool use, code execution, structured APIs – can unlock performance that no amount of prompt tuning will achieve.
These principles reflect a broader shift in how we think about LLMs: not as static question-answering systems, but as agents that can plan, explore, and compose actions to solve complex reasoning tasks. Graphs, with their rich relational structure and diverse information types, are a natural proving ground for this agentic paradigm.
Looking ahead
As LLMs continue to grow in capability the advantages of agentic interaction modes are likely to compound. Our results already show that larger models and reasoning-enabled variants consistently improve performance across all interaction strategies. But critically, the gap between prompting and code generation persists at every model scale, suggesting that interaction design is a complementary axis of improvement to model scaling.
For teams building intelligent features on collaborative platforms, knowledge graphs, or any system where entities are connected by rich relationships, this work offers a clear message: the way you let an LLM engage with your data can matter as much as the model itself. As the ecosystems of people, content, and activity that power modern productivity tools continue to grow in scale and complexity, principled approaches to LLM-graph interaction will only become more important.
The title of our paper captures the core insight: when it comes to LLMs and graphs, actions truly do speak louder than prompts.
Learn More
Read the full paper: Actions Speak Louder than Prompts: A Large-Scale Study of LLMs for Graph Inference (opens in new tab)



