By Taiwei Shi, Sihao Chen, Longqi Yang, Jaime Teevan
Reinforcement Learning is at the core of building and improving frontier AI models and products. Yet most state-of-the-art RL methods learn primarily from outcomes: a scalar reward signal that says whether an attempt worked, not why it failed. When an agent writes code that doesn’t compile, for example, it may only receive a 0/1 score (“failed” vs. “worked”). Lacking an explanation or a concrete path to correction, the agent must try again, often thousands of times, until incremental parameter updates eventually produce a successful solution. This is particularly problematic for collaborative scenarios that are social, long-horizon, and hard to score.
Humans don’t learn that way. When you get better at collaborating, for example, it’s rarely by seeing success or failure alone; you talk through what went wrong, share context, and adjust together. Teamwork improves through reflection, not just outcomes. Today’s AI agents largely lack this reflective loop. Experiential Reinforcement Learning (ERL) asks: what if an agent could pause, reflect on its mistakes, and use those insights to improve?
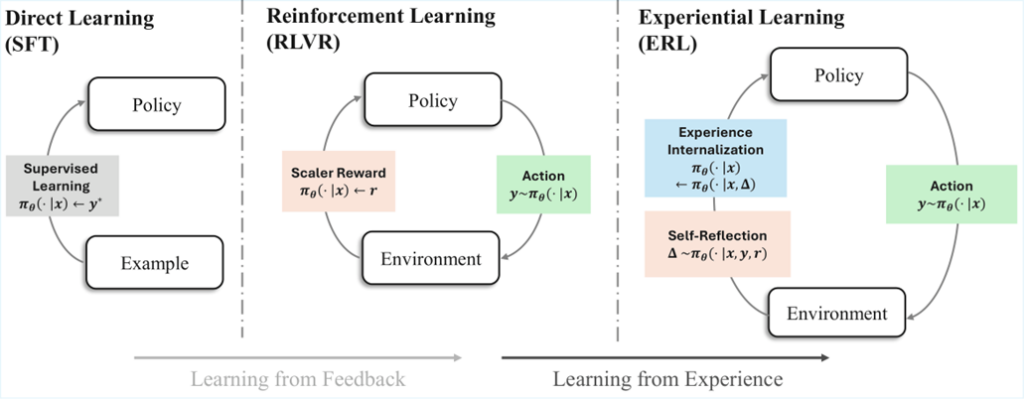
The core idea: learning through experience
Rather than relying on imitation or blind retries, ERL teaches an agent to turn feedback into structured behavioral revision. The method follows five steps:
- Make an initial attempt: Given a task, the model produces a first response and receives feedback from the environment (including text feedback and a scalar reward).
- Get an evaluation: The environment assesses the attempt and returns information about what happened and what should change.
- Reflect on what went wrong: When performance is suboptimal, the model generates a structured reflection describing how to improve. The reflection is conditioned on the task, the initial attempt, the feedback, and cross-episode memory of previously successful reflections.
- Try again using that insight: Guided by its reflection, the model produces a revised second attempt and receives new feedback and reward.
- Internalize what works: Through selective supervised distillation, effective second attempts are absorbed into the base policy. Over time, the model learns to produce improved behavior directly from the original input, without requiring reflection at deployment time.
How ERL mirrors how humans learn from experience
The underlying idea isn’t new; it’s new in this context. In the 1980s, education researcher David Kolb argued that people learn most effectively by cycling through experience and reflection: you have a concrete experience, reflect on what happened, form a revised understanding, and then try again. That cycle (experience, reflect, conceptualize, experiment) helps explain why one student learns from a failed exam while another simply retakes it. ERL can be seen as a computational version of Kolb’s cycle: the first attempt is the concrete experience; the reflection is the reflective observation; the revised second attempt puts a new conceptualization into practice. Finally, the internalization step, where successful corrections are distilled back into the policy, mirrors how people eventually stop needing to consciously work through the cycle because the lesson becomes automatic.
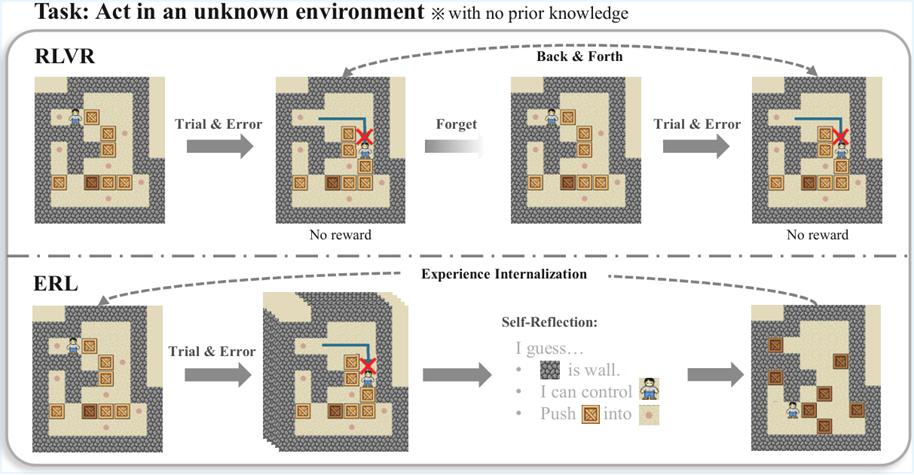
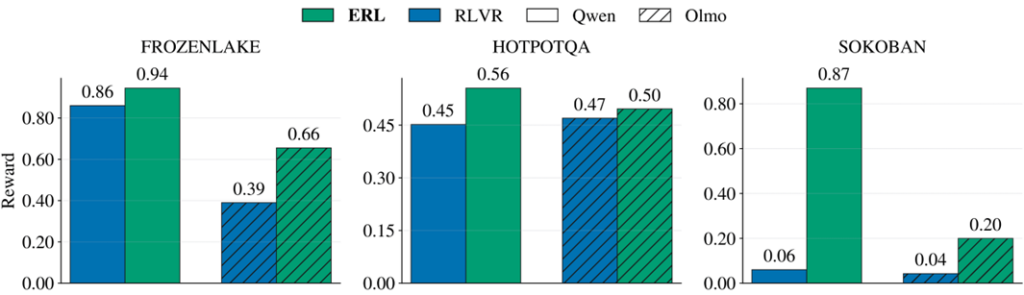
Results
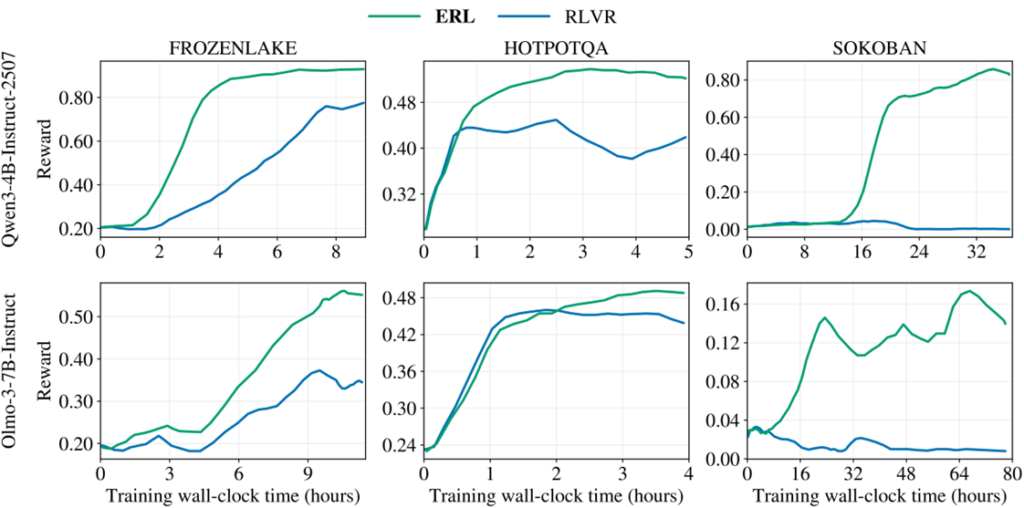
Across agentic reasoning and tool-use tasks, ERL consistently outperforms standard RL. The largest gains appear in settings with minimal upfront instruction, environments where the agent must infer the “rules of the game” through interaction. In these open-ended regimes, reflection and revision become a primary driver of learning, and ERL is most valuable precisely where outcome-only RL tends to struggle.
Looking ahead: learning through interaction in human-AI collaboration
Experience-driven learning could become a core primitive for future intelligent systems shifting AI from optimizing outcomes to accumulating understanding through interaction.
The real promise of ERL points to a future where AI learns to collaborate with people. Human collaboration isn’t a fixed environment with a clean reward signal; it’s fluid, social, and deeply contextual. A good collaborator reads the room, adapts to a partner’s working style, recovers gracefully from misunderstandings, and builds a shared history of what works.
Today’s AI agents don’t do much of that; they often treat each interaction as if it’s the first. With ERL, an agent could reflect on why a conversation went sideways, revise its approach, and internalize the lesson for next time. Over time, it might learn that one user prefers concise answers, while another values detailed reasoning, and it could adapt accordingly. In effect, the agent’s way of working with you could become more personalized and reliable, like a trusted colleague.
ERL offers a concrete mechanism, not just a vision, for how AI might get there: not by hard-coding social rules, but by learning them the way people do, through experience.
Learn More
Read the paper: “Experiential Reinforcement Learning” (opens in new tab)