

By: Ahmed Awadallah, Sahil Gupta, Yash Lara, Yadong Lu, Hussein Mozannar, Akshay Nambi, Zach Nussbaum, Yash Pandya, Aravind Rajeswaran, Corby Rosset, Alexey Taymanov, Luiz do Valle, Vibhav Vineet, Spencer Whitehead, Andrew Zhao

[Update on July 22nd 2026] Fara1.5 weights (opens in new tab) are now publicly available on HuggingFace under the MIT license! This is a major advancement and sets a new SoTA for open-weight web agent models.
We are excited to introduce the Fara1.5 family of computer use agent (CUA) models for the browser: Fara1.5-4B, Fara1.5-9B, and Fara1.5-27B. Building on our work from Fara-7B, the Fara1.5 models represent a major step forward for agentic small language models (SLMs). Across the family, these models are the most capable CUA models for their respective model sizes while remaining practical to deploy on modest hardware.
The Fara1.5 models can complete a wide range of complex tasks in the browser, like comparing products, filling out forms, booking events, and more. Compared to Fara-7B, we see clear improvements both qualitatively through user experiences and quantitatively across all benchmarks. Concretely, Fara1.5 makes several advancements:
- A family of capable CUA models. We are releasing three model sizes: 4B, 9B and 27B, to accommodate different constraints on cost and performance. Across key benchmarks, Fara1.5 outperforms other models of similar sizes. For example, on the Online-Mind2Web benchmark consisting of 300 tasks across 136 popular sites, Fara1.5-9B achieves a task success rate of 63% which nearly doubles the performance of Fara-7B and significantly improves over the performance of GUI-Owl-1.5-8B (49%), the prior best performing model at this scale. Moreover, Fara1.5-4B achieves strong performance at 57% while the larger Fara1.5-27B scores 72%, closing the gap to proprietary models like Yutori’s n1.
- Optimized for realistic interactions. Based on our work with MagenticLite, Fara1.5 is trained to perform tasks that people want to complete in the real world, such as form filling or cross-site comparison shopping. Fara1.5 also respects user preferences and asks for approval and clarifications when needed. By designing Fara1.5’s training with a focus on user experience, users can experience smoother interactions and better control over their tasks.
- Beyond gated domains. Only using trajectory data from live and public websites limits what activities we can train the agent on. For instance, domains that require logins or tasks that require irreversible actions, such as sending an email, cannot be completed on the live web for safety reasons. However, these kinds of tasks are important use cases for CUA models. We complement our training data with synthetic domains that simulate popular online websites/apps to allow our model to act beyond gated domains and, e.g., send the email or book the flight rather than just searching for it.
Fara1.5 Models
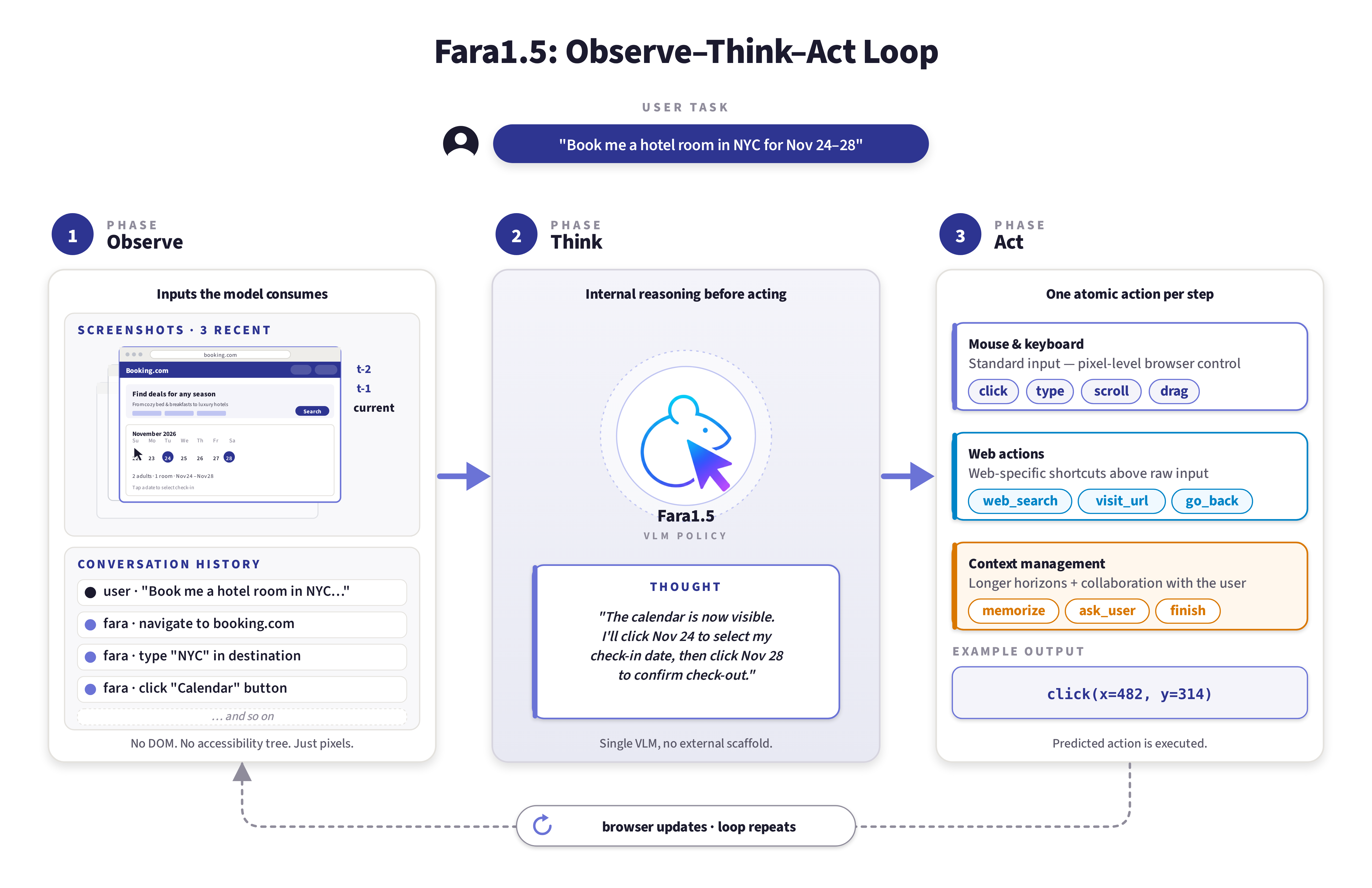
Agent Loop
Given a task from the user, Fara1.5 models follow an observe-think-act loop. At each step of the loop, the Fara1.5 models take in the previous conversation history and the three most recent screenshots from the browser (including the current page). This context is used to output thoughts and predict the next single-step action to take. These actions include standard mouse-and-keyboard inputs, web-specific actions (e.g., web search), and context management actions (e.g., memorizing facts for later use or asking user questions). Our meta-actions, such as context management, allow Fara1.5 models to operate over longer horizons and work collaboratively with users to complete tasks.
Training
We train our models on trajectory data from our FaraGen1.5 system described below. Here, a trajectory is our sequence of user messages interleaved with observe-think-act steps from a task solver agent that demonstrates how to complete tasks.
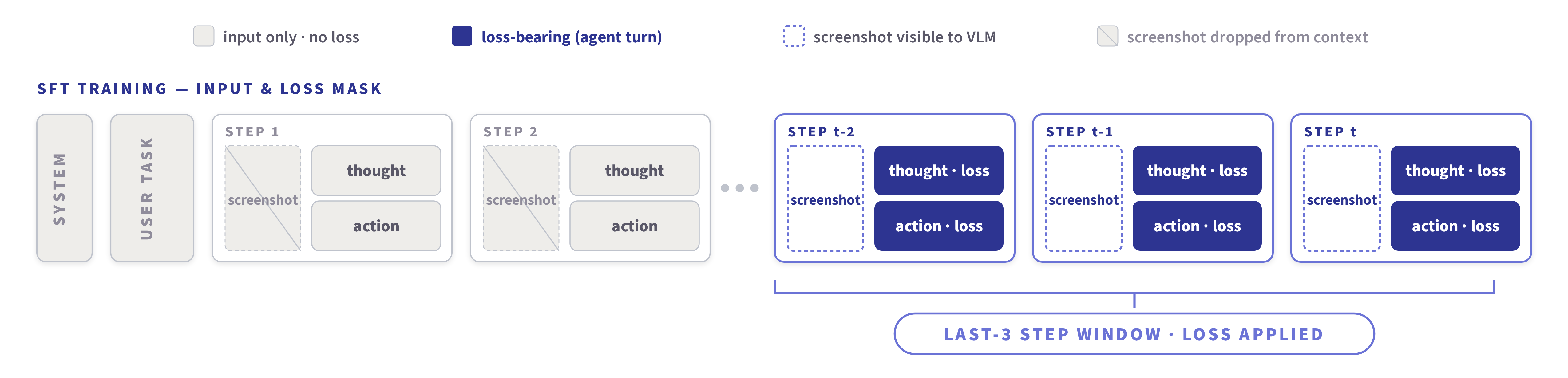
Training setup. We treat each step in a trajectory as a training example, training our models to output the current step, given the preceding ones. As previously mentioned, the input at each step contains the full text conversation history and the most recent three screenshots. Since we keep only the most recent screenshots at each step, we only apply the loss to actions for the most recent three turns. The figure below shows an example of this. We use a cross-entropy loss applied to the tokens of the thoughts and actions.
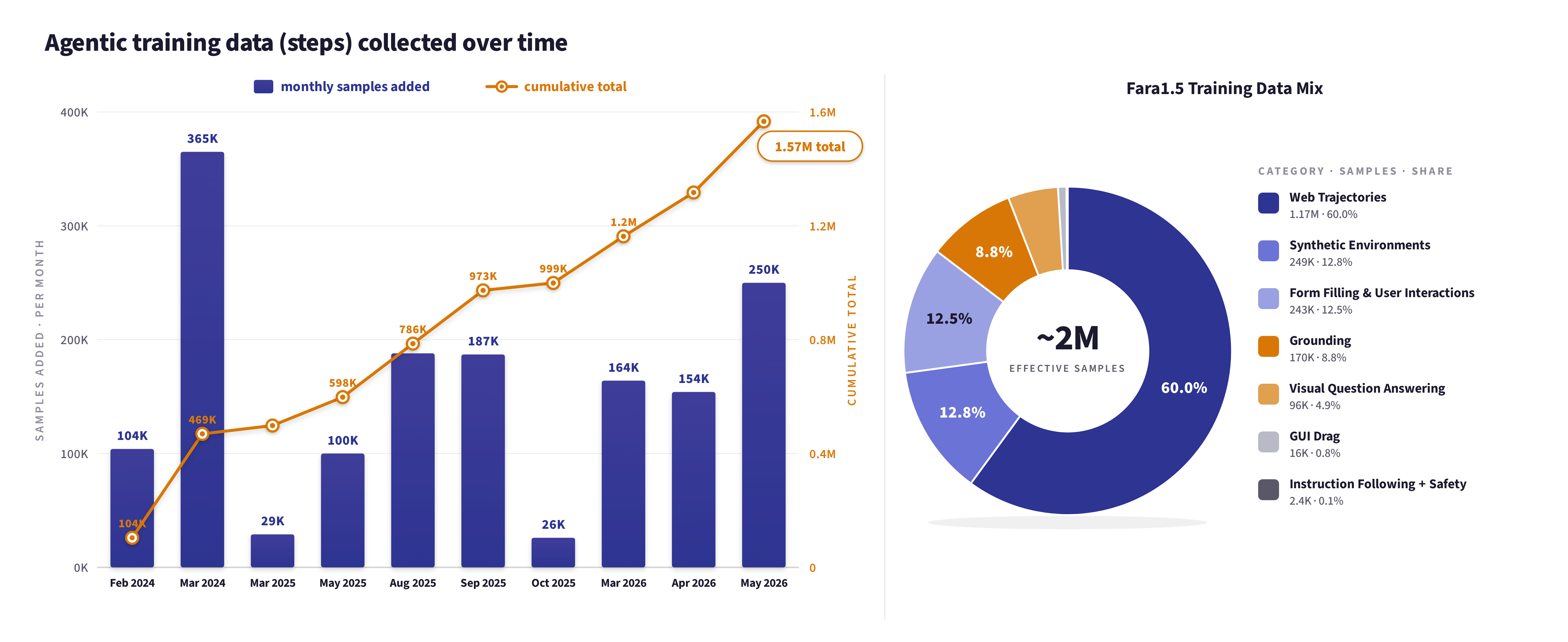
Data mix. The core of our training data consists of full trajectories that have been verified to solve complex tasks. In addition to these agentic trajectory traces, our final data mixture also includes data from related auxiliary tasks like grounding, VQA, instruction following, and safety. The breakdown of our training dataset is depicted in the figure below. Over time, we experimented with various data mixes and ultimately arrived at this recipe which provided a desirable trade-off in performance on agentic tasks while retaining or improving performance on core capabilities like grounding and VQA.
Base model. We select Qwen3.5 as our base model given its strong grounding and reasoning capabilities. By using stronger base models, we have a better starting point for fine-tuning and reach higher performance overall. We use the 4B, 9B, and 27B variants models as our backbones.
Model Family
Fara1.5 comes in three model sizes – 4B, 9B, and 27B. Holding the training data fixed, we trained models of different sizes and evaluate on two benchmarks – WebVoyager and Online-Mind2Web. We observe a clear positive scaling for performance as we scale the model size. Going from 4B to 27B yields +14.7 points on Online-Mind2Web and +7.8 points on WebVoyager. This suggests that our training recipe is viable for training both edge scale models that run on-device as well as larger cloud hosted models. We also note that Fara1.5-27B is among the top models based on the Online-Mind2Web leaderboard and outperforms even larger and proprietary models like Gemini 2.5 Computer Use, OpenAI operator, and Yutori Navigator n1.

FaraGen1.5: End-to-End Synthetic Data Generation for CUA
FaraGen1.5 is the next evolution of our scalable synthetic data generation pipeline for computer use data. The pipeline consists of three modular components: environments, solvers, and verifiers. Compared to FaraGen (from Fara-7B), this evolution allows for an expanded set of environments including synthetic domains for task solving, improved solvers that achieve higher accuracy, and more reliable verifiers consistent with human judgement.
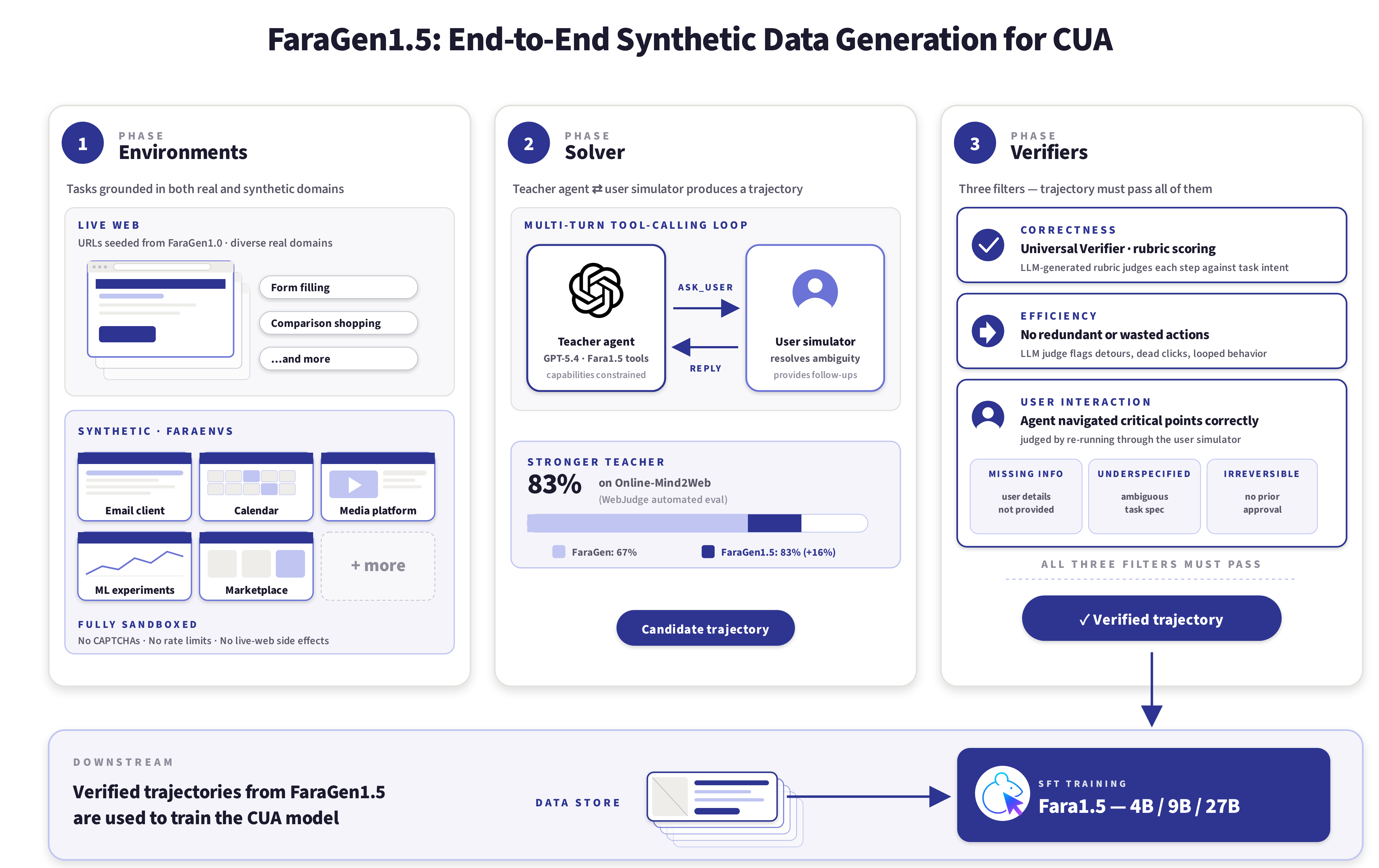
Environments
Our goal is to have our task distribution reflect realistic tasks that users care about on the web. Based on feedback for Fara-7B, we prioritize two broad kinds of environments to create tasks for: open-internet and gated domain.
Open-internet tasks are ones that are feasible to complete on live websites, without requiring logins, real accounts, etc. For example, a task might be to find current internship openings at Microsoft Research, which only involves navigating the web and identifying options. To target these, we utilize the same large index of URLs from FaraGen as seeds to generate diverse tasks, categorizing them by different types and target use case scenarios. Furthermore, we expand our task type coverage by manually curating seed tasks that capture use cases surfaced via the feedback for Fara-7B. This includes tasks like form filling, product comparisons, and more.
Gated-domain tasks require login and accounts to complete. Returning to the example above, if instead the task is to apply for an internship, then this becomes an issue because our solving system would be taking irreversible actions and would require a real login. To address this, we create synthetic environments that mimic real world domains, which allows our agent to learn from tasks that go beyond gated domains. In FaraGen1.5, we use a semi-automated recipe to generate synthetic websites that functionally replicate real domains.
Synthetic environment creation. Our approach to creating these environments starts by collecting trajectories of interactions on the domain we would like to replicate. Then, we provide these interactions to a coding agent, notably GitHub Copilot CLI (opens in new tab), to generate a spec for fully functional sandboxed clone, complete with a realistic-looking frontend and a fully functional API backed by a database. The coding agent works with a human to iteratively refine the environment based on human feedback. The final result is a fully functional replica of the desired website or app. We found the first iteration of the coding agent to be often lacking, e.g., having nonfunctional buttons. But in conjunction with iterative human testing, we found coding agents to be an excellent way to generate synthetic training environments.
Once we have these synthetic replica environments, we generate realistic task scenarios that take into account both the environment and database used to populate it. For instance, if we are building an email domain, we generate the environment with persona-based narratives to simulate an employee in a small-sized IT firm with emails referencing IT projects and calendar invites involving the same colleagues to ensure consistency. Because we control the full stack (UI, database, seed data, and tasks), we know the correct outcome for every task. For tasks where an agent must mutate the state of the backend database, an LLM judge scores the trajectory by comparing database snapshots taken before and after execution. The judge confirms that the intended action was taken and no other actions were performed. Tasks that do not produce database changes are scored by an LLM judge against pre-computed reference answers.
We use this pipeline to produce six synthetic environments (FaraEnvs) spanning domains such as email clients, calendars, media platforms, ML experiment managers, and marketplaces.
Solver
Given a task from the previous step, we use a strong solver agent that interacts with a user simulator to produce a trajectory for the task that we can use for supervised finetuning. Specifically, we use OpenAI’s GPT-5.4 with custom defined tools that replicate Fara1.5 action space in a multi-turn tool calling loop. This new solver agent obtains a score of 83% on Online-Mind2Web using the automated WebJudge compared to 67% for the solver system we used in the earlier Fara-7B. In certain cases, we constrain the capabilities of GPT-5.4 so that the data is learnable by the small model, for instance by not allowing it to issue complex URL queries that can bypass site interaction.
The user simulator is invoked by the solver agent if the agent issues an ask_user tool call to provide the agent with additional context on the task (user information, resolve ambiguities, or provide preferences) or when the agent finishes a task to provide adjustments or follow-up requests.
Verifiers
Once a trajectory is generated, we need to ensure that it is sufficiently high quality to use in training. We judge trajectories according to three criteria: correctness, efficiency, and user interaction. A trajectory that fails any of three criteria is not included in our training data. For correctness, we rely on the process score from the Universal Verifier that our team has released for the open-internet tasks, which uses LLM-generated rubrics to judge trajectories. On synthetic environments, we use the previously mentioned privileged-information LLM-judge. For efficiency, we use an LLM-judge that scores a trajectory based on any inefficiencies in terms of redundant or unnecessary actions that the agent took. Finally, for user interaction, we check if the task involves any critical points, which we categorize into three cases:
- Missing User Information: task requires personal information user has not provided.
- Underspecified Task: task description is ambiguous or missing details needed to act at the current step.
- Irreversible Action without prior approval: we are about to perform an action that cannot be undone (e.g., submitting a form) and for which prior approval was not obtained.
If a task involves any of these critical points, we judge if the agent navigated this situation correctly by asking the user simulator.
Evaluations
Comparison to Fara-7B
We first benchmark our new Fara1.5-9B model against our prior generation, Fara-7B. We find that Fara1.5-9B offers consistent improvements over Fara-7B across all the benchmarks we evaluate. In most of these benchmarks (e.g., Online-Mind2Web), Fara1.5-9B also sets the new state of the art for the size class.

Agentic Benchmarks
To further study the performance of Fara1.5 models against a broader comparison pool, we choose to evaluate their CUA capabilities on two well-established external benchmarks: WebVoyager and Online-Mind2Web. They measure a model’s ability to complete tasks on the live internet.
We rely on Browserbase to stabilize browser sessions and reduce the rate of session-level blocking. All Fara1.5 and Fara-7B numbers are averaged over three independent runs.
Comparison of similarly sized agents. We first compare Fara1.5-9B against other models in a similar size range. We find that Fara1.5-9B substantially outperforms every prior agentic SLM on both WebVoyager and Online-Mind2Web benchmarks.
| Model | Size | Org. | WebVoyager | Online-Mind2Web |
|---|---|---|---|---|
| Fara-7B | 7B | Microsoft | 73.5 | 34.1 |
| MolmoWeb | 8B | AI2 | 78.2 | 35.3 |
| Holo2 | 8B | H Company | 80.2 | N/A |
| GUI-Owl-1.5 | 8B | Alibaba | 78.1 | 48.6 |
| Fara1.5-9B | 9B | Microsoft | 86.6 | 63.4 |
Comparison against larger and proprietary agents. We further compare our Fara1.5-27B model against a broader set of frontier agents, including proprietary systems such as OpenAI Operator, Google Gemini 2.5 Computer Use, Yutori Navigator n1, as well as larger open-weights models like GUI-Owl-1.5-32B Thinking shown in Table 2. We additionally report all three Fara1.5 variants, 4B/9B/27B, in the same table, so the model-scaling behavior of the family can be read directly alongside the cross-model comparison.
| Model | Size | Org. | WebVoyager | Online-Mind2Web |
|---|---|---|---|---|
| Gemini 2.5 CU | – | – | 57.3 | |
| Operator | – | OpenAI | 87.0 | 58.3 |
| Yutori Navigator (n1) | – | Yutori | – | 64.7 |
| GUI-Owl-1.5 | 32B | Alibaba | 82.0 | – |
| Holo2 | 30B-A3B | H Company | 83.0 | – |
| Fara1.5-4B | 4B | Microsoft | 80.8 | 57.3 |
| Fara1.5-9B | 9B | Microsoft | 86.6 | 63.4 |
| Fara1.5-27B | 27B | Microsoft | 88.6 | 72.3 |
| FaraGen1.5 (solver) w/ GPT-5.4 | – | Microsoft / OpenAI | 93.4 | 83.4 |
Comparing to other pixel-to-action models, Fara1.5-27B sets a new state-of-the-art on both benchmarks. On Online-Mind2Web, Fara1.5-27B outperforms Operator, Gemini 2.5 Computer Use and Yutori Navigator n1 by large margins. Even our Fara1.5-9B model is competitive with these much larger systems. We also note the performance of the solver we use to generate the data. We find that there is still a small gap in performance between Fara1.5 and the “teacher”, which constitutes an upper bound for our SFT-based training setup.
Model scaling. Holding the training data fixed, we evaluate three Fara1.5 variants, 4B/9B/27B on both Online-Mind2Web and WebVoyager. Both metrics improve monotonically with parameter count. Going from 4B to 27B yields +14.7 points on Online-Mind2Web and +7.8 points on WebVoyager. The 9B model already covers two-thirds of gains while going from 4B to 27B, making it a good choice for deployment. However, 27B is a good choice if raw quality matters more than deployment cost.
WebTailBench results. Finally, we also evaluate our model on WebTailBench v1.5, a benchmark of long-tail web tasks that are generally underrepresented in standard agentic benchmarks. We report two metrics: Process Success, which credits the agent for taking the correct intermediate steps, and Outcome Success, which requires that the final task state be correct. We compare Fara1.5-9B against two prompted set-of-marks (SOM) baselines, o3 SOM and GPT-5 SOM agents, Fara-7B, and against GPT-5.4.
| Model | Size | Process Success | Outcome Success |
|---|---|---|---|
| o3 SOM | — | 69.5 | 35.0 |
| GPT-5 SOM | — | 69.2 | 45.1 |
| GPT-5.4 | — | 79.6 | 57.4 |
| Fara-7B | 7B | 48.8 | 24.1 |
| Fara1.5 | 9B | 64.5 | 32.3 |
Fara1.5-9B substantially outperforms Fara-7B, improving outcome success by +8.2 at a comparable scale. These results suggest the gains from Fara1.5 carry over to the long tail as well.
Evaluating with Synthetic Environments
We also evaluate using our synthetic environments with two questions in mind: (1) Are these tasks learnable within the environments themselves? (2) How well does training on our synthetic environments transfer to real domains?
To answer the first question, we evaluate on six FaraEnvs using held-out validation tasks: Mail, Calendar, Stream, ML, Stay, Scheduler. We compare Fara-7B, Fara1.5-9B, and our FaraGen1.5 solver agent based on GPT-5.4. Fara-7B has not been trained on gated domains, while Fara1.5-9B has. We see low performance for Fara-7B, but Fara1.5-9B performs strongly on this in-distribution data. The combination of these suggests that generalizing from only open-internet data to closed domain data is challenging, so training in such environments is important.
| Model | Calendar | Stream | ML | Stay | Scheduler | Average | |
|---|---|---|---|---|---|---|---|
| Fara-7B | 16.4 | 11.6 | 21.0 | 11.5 | 18.0 | 34.3 | 18.8 |
| Fara1.5-9B | 77.3 | 77.3 | 75.0 | 77.0 | 56.0 | 68.0 | 71.8 |
| FaraGen1.5 (solver) w/ GPT-5.4 | 81.7 | 81.9 | 76.0 | 86.0 | 75.0 | 76.0 | 79.4 |
Towards the second question, we construct four synthetic environments modeled after domains from WebVoyager: Allrecipes, Apple, HuggingFace, and GitHub. Using FaraGen1.5, we generate trajectories on these synthetic environments (called synth-replica below), train Qwen3.5-9B on them, and evaluate on the corresponding live websites. The baseline here trains on a small amount of data from other domains as a control. We see that the gap on these domains between the synth-replica model and the full Fara1.5-9B is not large, which suggests that our synthetic environments provide some synthetic-to-real transfer.
| Domains | Allrecipes | Apple | HuggingFace | GitHub | Combined |
|---|---|---|---|---|---|
| Baseline | 87.5 | 68.8 | 59.5 | 75.6 | 73.4 |
| + synth-replica | 92.5 | 81.3 | 73.0 | 85.4 | 83.4 |
| Fara1.5-9B | 96.7 | 85.4 | 87.4 | 88.6 | 89.8 |
Safety
Computer use agents take actions with real-world consequences as they complete tasks on behalf of users. Therefore, we must ensure robust safety measures for their operations to prevent misuse, avoid unintended consequences and protect against external risks like prompt injections or online scams. Fara1.5 remains a research preview, and we continue to work on more robust mechanisms to ensure safe operation.
To mitigate misuse, we trained Fara1.5 to refuse harmful tasks based on a mixture of public safety datasets and internally generated tasks abiding by Microsoft’s Responsible AI Policy. To prevent Fara1.5 from taking unintended actions, Fara1.5 was trained to stop and ask the user at any critical points in the interaction. Critical points of the interaction occur when the task requires missing user information, or when the task itself is ambiguous or when the task requires taking irreversible actions that were not authorized by the user.
When used with the MagenticLite interface, all actions by the agent are logged and auditable allowing users to monitor task progress. The MagenticLite sandboxed browsers allow users to stop the agent at any time and provide a security boundary between the browser and the user’s machine.
For guidance on how to use our model safely, and the security considerations to be mindful of when using our model, please refer to our Model card.
Looking forward
Fara1.5 pushes the frontier of current computer use agent at their respective sizes. We have ambitious plans to continue pushing the performance and applications of the Fara1.5 model family. We aim to expand the scope of environments that Fara1.5 can manipulate including desktop and enterprise software. As we move to new environments, Fara1.5 will also need to perform new actions such as interacting with the terminal and running scripts. If you’d like to join us and help shape the future of agentic models, please apply for open roles here.
How to Use Fara1.5 Models
The Fara family of models are now open-weight and can be accessed from HuggingFace under the MIT license. Direct link to model collection: https://aka.ms/fara1.5-hf (opens in new tab)
Fara1.5-9B is also available on Microsoft Foundry (opens in new tab) and is integrated with MagenticLite (opens in new tab).
Our inference harness for running Fara1.5 is available on github (opens in new tab).
Acknowledgements
We thank Sara Abdali, Pashmina Cameron, Adam Fourney, Ran Gal, Sarthak Harne, Michael Harrison, Rafah Hosn, Neel Joshi, Ece Kamar, John Langford, Maya Murad, Michael Sapienza, Sidhartha Sen, Pratyusha Sharma, Weili Shi, Amanda Swearngin, and Cheng Tan for their valuable help, insightful discussions, and continued support throughout this work.
We also thank members of the Microsoft Edge team – Tao Li, Jay Liu, Linjun Shou, Jingxia Xing, Javier Flores Assad, and Meghan Perez – for their close collaboration and help to improve our models.