

More and more people are relying on instructional videos, such as cooking videos, to teach themselves skills with “how to” instructions. An important research question is then, in place of watching the entire video, can we provide a type of interactive access to make learning more effective? Figure 1 illustrates how videos are divided into segments, allowing users to skip to the answer segment for the given question. This question is becoming more important, as people are relying more heavily on videos to teach themselves skills during the COVID-19 pandemic.
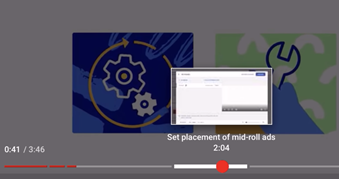
Figure 1. This figure demonstrates a scenario where a question is asked on an instructional video, and the video is skipped directly to a related segment for effective teaching. Currently, YouTube relies on manual annotation for this feature.

Figure 2. Research challenges for asking “how to” questions, known as non-factoid questions with long answers for text and video modality.
Professor Seung-won Hwang from Yonsei University in South Korea and his collaborators, Microsoft Research Asia’s Nan Duan and Lei Ji, and Yonsei PhD students, Kyungjae Lee, Hojae Han, and Seungtaek Choi, have been investigating this topic. Despite active research conducted on Question Answering (QA), answering “how to” questions is an under-studied topic, and existing solutions targeting factoid QA cannot satisfactorily answer “how to” questions with long answers, especially for multi-modal QA. Research challenges are summarized in Figure 2, which show how to support non-factoid QA for text and video modality. For text modality, the researchers found that the length difference between short questions and long answers hinders neural matching between two representations. They addressed this issue using the MICRON framework (published at EMNLP 2019), which combines the advantages of representation- and interaction-based matching. Their proposed model combines contextual representations and also considers interactions between n-grams of multiple granularities.
Their finding is extended to video QA. For this, there are two additional challenges (marked in red in Figure 2). Though documents are often semantically pre-segmented by paragraphs, segmenting them into answer units itself is a challenge in video QA. In addition, videos have multimodality, where semantics represented in both text and video modalities need to be aggregated. The researchers proposed a two-stage method, where Segmenter uses multimodal-BERT to generate segmentation candidates by predicting likely start/end positions. Ranker then prioritizes candidates based on length-adaptive gating to overcome the length gap challenge discussed above. This idea is described in an AAAI 2020 paper entitled “Segment-then-Rank: Non-factoid Question Answering on Instructional Videos.” See Figure 3.
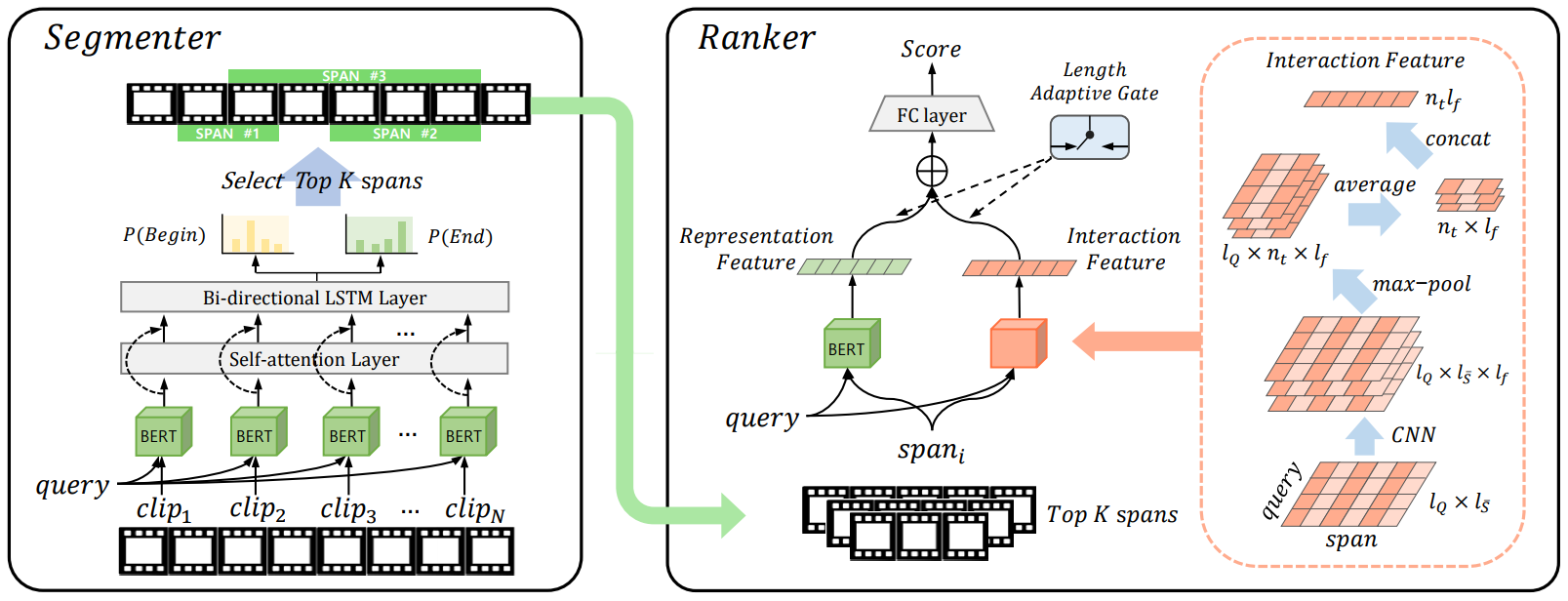
Figure 3. Segment-then-rank framework for non-factoid video QA
The team is continuing efforts to extract key segments from a full video, as Figure 4 illustrates. Existing video summarization extracts highlights but cannot support chaptering. The distinction with the current research is that it seeks to leverage external knowledge, such as recipes, to annotate key steps, which would help students discover key questions to ask for learning. A demo has been published at ECML 2020, available at: http://pcdeepred.yonsei.ac.kr/IVSKS/
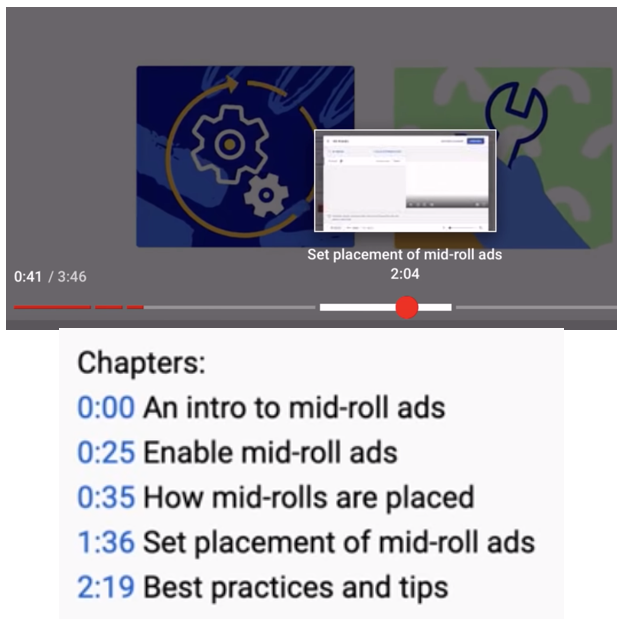
Figure 4. Grounding video with procedural knowledge for automated chaptering.
[1] https://support.google.com/youtube/answer/9884579?hl=en (opens in new tab) (credit: Figure 1 and 4)