

Editor’s note: How can we assess a person’s language proficiency level? In addition to making assessments through objective questions, subjective scoring is also required, such as essay scoring and oral evaluation. However, subjective evaluation is often costly, and the results are often variable. To solve this problem, the Microsoft Xiaoying team proposed a new method: using ordinal regression, which has been applied to pronunciation assessment, fluency evaluation, and English essay scoring.
In language learning, a key issue is how to assess learners’ performance. Generally, the assessment can be composed of both objective and subjective evaluation. Objective evaluation is completed through objective tests that consist of filling in the blanks, multiple choices, etc., and marks the learners as qualified if their answers to these questions are correct, while subjective evaluation is usually carried out in the form of questions and answers, where graders give a subjective evaluation of the testers’ answers, such as through essay scoring, oral evaluation, etc.
Subjective evaluation is often extremely costly both in terms of time and labor. In addition, it is not easy to maintain consistency in evaluation results due to differences in evaluation equipment, raters’ mental states, and personal preferences. In order to solve these problems, subjective evaluation has been identified as an important project in Computer-Assisted Language Learning (CALL).
We will introduce Microsoft Xiaoying team’s experiences in employing the Ordinal Regression (OR) method to handle the subjective evaluation problem in CALL, as well as the application of this method in pronunciation assessment, speech fluency evaluation, and English writing evaluation. We will then provide a summary of and outlook on related methods.
Ordinal regression and subjective evaluation
In subjective evaluation problems, different scores reflect different levels of performance. For example, in the 5-point Mean Opinion Score (MOS) system, 1 to 5 are used to represent performances that are very poor, poor, average, good, and outstanding. Traditional methods usually solve the problem through classification or regression, where classifiers or regressors are trained to obtain the mapping between input features and their scores.
However, with such, information on the relative order of samples in these types of problems cannot be fully utilized. In addition to absolute scores, the physical meaning of different scores is also representative of the sample’s relative position in the entire distribution. For example, information taken from a 3-point sample represents information that is worse than that from 4-point samples and better than that from 2-point samples. At the same time, the gap between 3-point and 2-point samples is different from the gap between 2-point and 1-point samples. Traditional classifiers only treat each score as a class and cannot fully utilize the relative order of the scores.
The differences between samples of different scores are not equidistant. For example, in essay scoring, points of 1 to 3 are often differentiated by spelling and grammatical errors, while points 3 to 5 are differentiated by higher-level writing skills, such as argumentation, expansion, relevance and so on. For regression with equal intervals, because it is affected by the size of the data set and the data distribution, there exists the problem of overfitting the model to the training data.
Considering the relative order between scores, researchers at Microsoft Research Asia proposed to use ordinal regression to solve such problems. Ordinal regression is used to model and predict data sets with subjective natural ordering. The ordinal regression method also has great applicable potential for tackling similar issues, such as age prediction, credit identification, and aesthetic appraisal.
Ordinal regression with anchored reference samples
When collecting data, the researchers found that with annotators, it is more difficult for them to give a sample a score of 1 to 5 than to determine which sample out of a pair is better, and during scoring, they are also more prone to fluctuations and deviations caused by changes in the scorer and evaluation time. This is because for some samples, due to psychological or physiological changes undergone by the scorer, the evaluation criteria shifts as a consequence, resulting in unsteady subjective scoring. Compared with directly scoring individual samples, it is easier to judge which one out of a pair is better. Although comparisons between sample pairs are more consistent and accurate, the number of possible combinations of different sample pairs increases factorially with the number of samples, leading to a parallel increase in labor and costs. But for machines, determining the relative superiority and inferiority of a pair of samples can be achieved easily using a binary classifier, which does not pose a great burden on computing power.
Based on such observations, the researchers proposed Ordinal Regression with Anchored Reference Samples (ORARS). As is shown in Figure 1, the basic logic of this method is to select several samples in different score segments as anchor points. New test samples are compared with the anchored reference samples in different score buckets to obtain the position of the test samples in the overall distribution, thus determining their corresponding levels. For example, during the comparison process, a sample to be tested performs better than the anchored reference samples in the 1-point and 2-point buckets, is comparable to the samples in the 3-point bucket, and is slightly worse than the samples in the 4-point and 5-point buckets. It is then easy to infer that the most appropriate score is 3 points. This method does not directly predict its score, but restitutes the ordinal relationship represented by the score to its corresponding position in the original sequence distribution. For machines, understanding the absolute meaning of different scores is a relatively more difficult operation, especially for fine-grained segmentation such as the 100-point system. The ORARS method returns this type of scoring problem to its original simplicity, comparing the relative superiority and inferioritybetween samples and using the samples at the corresponding positions as the predicted score.

Figure 1: Logistic schematic diagram of ordinal regression based on anchored reference samples
Specifically, ORARS is divided into training and inference stages. As is shown in Figure 2, during the training phase, the anchor set A and the remaining training set T are first separated from the training set D (the sample set with expert evaluation),. A and T can overlap, and the Cartesian product between A and T is used to generate sample pairs (a, b). The corresponding labels of the sample pairs are determined by the relative relationship between the sample pairs, where either sample a is better than sample b, or sample a is not better than sample b. Then, the constructed sample pair set is used to train a binary classifier to judge the relative merits of the input sample pairs. During the inference phase, the test sample is first paired with all samples in the selected anchor point set A, then the binary classifier obtained in the training phase is used to conduct inference, and finally the comparison of results between the test sample and all samples in A is used to predict the score.
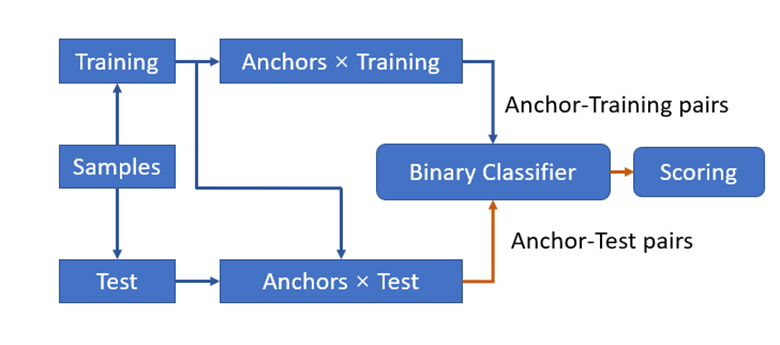
Figure 2: Schematic diagram of the flow of ordinal regression with anchored reference samples
For the scoring of the inference process, the researchers proposed two different scoring methods, which are either applicable in cases of relatively uniform sample distribution or uneven sample distribution.
Method 1: For a sample set with relatively uniform data distribution, when selecting anchor point set A, suppose there are N levels in total, then M samples are selected for each level as anchor points. Generally, it is recommended that samples of more unified opinions from multiple annotators are selected as anchor points. The inference result of the trained binary classifier is noted as P(x_t, x_a), and its physical meaning is whether the test sample is better than the anchor reference sample x_a. The final score is s= ∑_(i=1)^( N*M)(P(x_t,x_a)/M). This method uses the comparisons between the test samples and the anchor samples in each score bucket, and obtains the final predicted scores by means of a weighted average.
Method 2: For sample sets with uneven data distribution or more grades (such as a percentile system), it is extremely challenging to select a uniform anchor point set. Therefore, researchers use all samples in the training set as anchored reference samples and compare the test samples with all samples, using the sum of all model outputs to obtain the “rankings” of the test samples in the anchor sequence, and the sample scores corresponding to the rankings in the anchor set is used as the prediction scores.
Ordinal regression with anchored reference samples has the following advantages: First, ordinal information is utilized to simplify the traditional multi-classifier or regression to relative comparisons between sample pairs. On one hand, the binary comparison is much simpler. On the other, a large number of data samples are generated through the combination and pairing of the original data samples. Hence, the binary classifier is trained so that the performance of the model is ensured through more data and simpler comparisons of superiority and inferiority of the data. Second, compared to the traditional ordinal regression method, ORARS introduces anchored reference samples, which determine the levels of the samples to be tested through the comparisons between sample pairs. The anchored reference samples provide reference information during the comparison and build more accurate ordinal space and fine quantification of ordinal regression.
Application of ORARS in Computer Aided Language Learning
Ordinal regression with anchored reference samples introduces ordinal information and transforms the original scoring problem into a comparison between sample pairs, so that the performance is optimized.
The researchers verified its effectiveness in three sub-problems, namely, the fluency scoring of ESL (English as a Second Language) speech, pronunciation accuracy assessment, and English writing evaluation. The three sub-problems were drawn from the fields of speech signal processing and natural language processing, and the sample sizes of the data sets were 8,000, 2,500, and 350 respectively. These experiments help to verify the universality and robustness of the ORARS method in different problems and with data sets of different sizes.
Speech fluency scoring
8,000 sentences from Microsoft Xiaoying’s ESL (English as Second Language) speakers’ corpus were used. Each sentence scored was on a 5-point scale by two professional editors with linguistics backgrounds, and their average score as the standard samples. If the score difference between the two editors was greater than 2, a third professional editor was introduced for arbitration.
After that, 500 sentences were selected as the test set, and the remaining ones were used as the training set. The ORARS method was compared with the DNN classifier, SVM, SVR regressor, and the classical ordinal regression method (Binary decomposition [4] and multi-task ordinal regression [5].), and also with six-dimensional fluency feature vectors such as speech rate and pause.
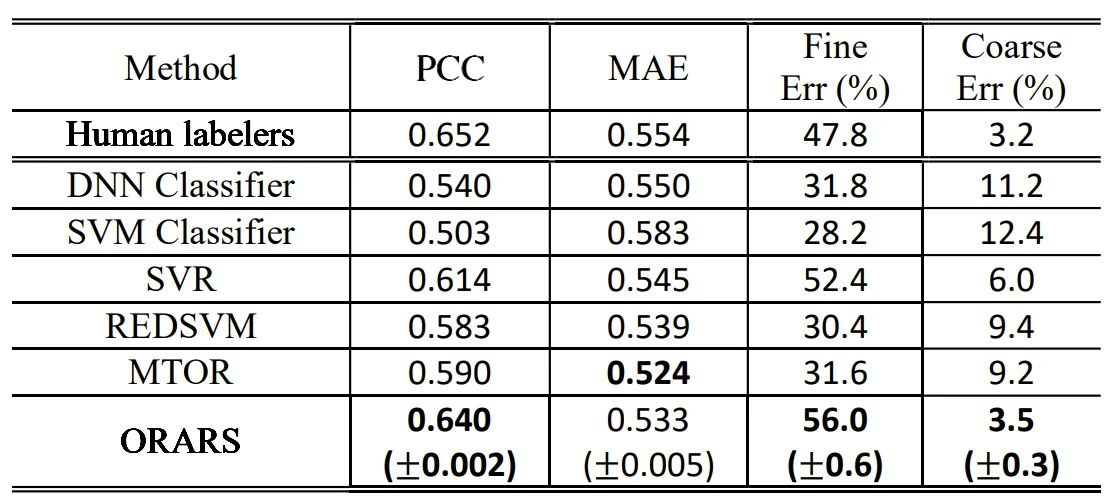
Table 1: Comparison of speech fluency in different methods
Through a comparison of the Pearson Correlation Coefficient (PCC), Mean Absolute Error (MAE), and the proportion of both fine errors (prediction errors less than 0.5) and coarse errors (prediction errors greater than 1.5), we can see that the method based on ordinal regression can improve the performance of the model, while the ORARS method can achieve the best performance, even surpassing expert evaluation on MAE and fine errors.
Pronunciation accuracy assessment
2,500 sentences from Microsoft Xiaoying’s ESL speakers in the Read-after-me scenarios were selected, with each sentence scored on a 5-point scale by four professional editors with language/phonetics backgrounds, and their average score as the sample label.
Traditional pronunciation scoring is generally based on GOP (Goodness of Pronunciation). The pronunciation score of each phoneme is first obtained, and then the total score of the sentence level is obtained by averaging. However, this method has the following problems: 1) The simple averaging operation ignores the differences between the phonemes and cannot represent the pronunciation level of the entire sentence; 2) It ignores the relative ranking information in the scoring problem. In this task, therefore, researchers proposed extracting sentence-level features (average GOP vector + confusion GOP vector), and used the ORARS method to build the scoring model.
Researchers performed two sets of experiments based on different acoustic models (AM), denoted as AM1 and AM2, and verified the performance of the model using a 5-fold cross-validation method. By comparing the performance differences between the traditional method GOP and its latest variant Transition Aware pronunciation Score (TA Score), the neural network-based regression methods, and the ORARS method, and subsequently using the Pearson Correlation Coefficient (PCC), the Spearman Correlation Coefficient (SCC), and MAE for conducting comparisons, the following results were obtained, as shown in Table 2:

Table 2: Comparison of different methods of scoring on pronunciation accuracy [2]
English essay scoring
The researchers collected 350 independent writings in TOEFL (Test of English as a Foreign Language), and each was marked by a professional editorial team based on a 30-point system. Each article was marked by two editors. Microsoft Xiaoying extracted features based on wording, sentences, paragraphs, and other aspects of the essays to build the model, and compared the performance of this model with others by means of a ten-fold cross-validation, as is shown in Table 3:

Table 3: Comparison of different methods of English essay scoring
Experimental results demonstrate that the ORARS method performs better than other methods. Due to the inadequate amount of data, regression based on Neural Net (NN) is almost impossible to train. However, the ORARS method increases the amount of data for training the binary classifiers by combining sample pairs, which demonstrates the excellence of its performance. However, when the amount of data is too small, there is still a long way to go for the performance of machine learning based on ORAS to be as good as expert reviewers, although ORARS has already shown more effectiveness than other traditional machine learning methods.
Summary and analysis
The ORARS method transforms the traditional subjective scoring problem into a binary comparison between a series of sample pairs. Compared with traditional machine learning methods and ordinal regression, the scoring performance of the ORARS method has been steadily improved. ORARS-based pronunciation scoring and writing scoring has been applied to Microsoft Azure Speech Pronunciation Rating Service and Microsoft AimWriting. In addition to the subjective scoring of language learning, the ORARS method can also be applied to more ranking problems, such as age prediction via faces, age recognition via timbre, subjective aesthetic ratings, etc. This method makes full use of humans’ cognitive understanding in dealing with similar problems. In future research, the Microsoft Xiaoying team will further elaborate on the theoretical analysis of the ORARS method and promote more applications from the perspectives of mathematics, theory, and cognition.
The ORARS method has also been applied to the pronunciation assessment of Microsoft Azure’s speech service Speech-to-Text, based on which the functions of Microsoft Xiaoying was constructed. Microsoft hopes to take this opportunity to better empower our partners, application developers, language schools, training centers, educational institutions, and test centers, who/which provide educational solutions, to support their development of various language learning, oral practicing, and testing scenarios.
We welcome you to test out Microsoft Xiaoying and Microsoft Azure’s pronunciation evaluation function. Any feedback and opinions you can provide would be highly appreciated.
- Microsoft Xiaoying Official Account
https://www.engkoo.com/ (opens in new tab)
- Microsoft Azure Voice Evaluation API Call Document
- Microsoft Azure Voice Evaluation Code Integration Example
References:
[1] Shaoguang Mao, Zhiyong Wu, Jingshuai Jiang, Peiyun Liu, Frank Soong, NN-based ordinal regression for assessing fluency of ESL speech. [in] Proc. ICASSP 2019, pp. 7420-7424, 2019.
[2] Bin Su, Shaoguang Mao, Frank Soong, Yan Xia, Jonathan Tien, Zhiyong Wu, Improving pronunciation assessment via ordinal regression with anchored reference samples. [in] arXiv preprint arXiv:2010.13339, 2020.
[3] Improve remote learning with speech-enabled apps powered by Azure Cognitive Services. Microsoft Tech Community Blog
[4] Ling Li, Hsuan-Tien Lin, Ordinal regression by extended binary classification. [in] Proc. Advances in neural information processing systems, pp. 865-872, 2007.
[5] Zhenxing Niu, Mo Zhou, Le Wang, Xinbo Gao, Gang Hua, Ordinal regression with multiple output cnn for age estimation. [in] Proc. CVPR, pp. 4920-4928, 2016.