
Traditionally, machine learning based approaches to information retrieval have taken the form of supervised learning-to-rank models. Recent advances in other machine learning approaches—such as adversarial learning and reinforcement learning—should find interesting new applications in future retrieval systems. At Microsoft AI & Research, we have been exploring some of these methods in the context of web search. We will share some of our recent work in this area at SIGIR 2018 (opens in new tab). This post briefly describes what is in couple of the papers we are presenting at the conference.
Adversarial learning for cross domain regularization
While traditional learning-to-rank methods depend on hand-engineered features, recently proposed deep learning based ranking models such as DSSM and Duet focus more on learning good representations of query and document text for matching by training on large datasets. For example, during training if the ranking model observes that the pair of phrases, “Theresa May” and “UK Prime Minister” co-occur frequently together in documents then it may infer that they are somehow related. The model might learn to promote documents containing “Theresa May” in the ranking when the query involves “UK Prime Minister”. If this same model is employed to retrieve from a different, say, older test collection in which the connection to “John Major” may be more appropriate, then the model performance may suffer.
The ability to learn from data that certain entities, concepts, and phrases are related to each other gives representation learning models a distinct advantage. But this can come at the cost of poor cross-domain generalization. For example, if the training and the test data are sampled from different document collections then these models may demonstrate poorer retrieval performance. In web search, the query and document distributions also naturally evolve over time. Therefore, a representation learning model may need to be re-trained periodically to avoid performance degradations. Traditional IR models—such as BM25 (opens in new tab) —make minimal assumptions about the data distributions and therefore are more robust to such differences. Learning deep models that can exhibit similar robustness in cross domain performance is an important challenge in search. When Daniel Cohen, a PhD student from University of Massachusetts, Amherst, joined the Microsoft Research lab in Cambridge last summer, he chose to study the effectiveness of adversarial learning as a cross-domain regularizer.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
“My motivation for collection/domain regularization came about with the rise of these massively complex models that are achieving state of the art results. While this performance is desirable, these same models drastically underperform when the domain substantially shifts away from what was seen during training. As there are a lot of fields without enough training data (legal, medical), this provides a stepping stone towards a general relevance model that isn’t burdened with traditional handcrafted features.” – Daniel Cohen
The findings from our project are summarized in, “Cross Domain Regularization for Neural Ranking Models (opens in new tab)” co-authored by Daniel Cohen, myself, Katja Hofmann, and W. Bruce Croft. In this work, we train the neural ranking models on a small set of domains. Simultaneously, an adversarial discriminator is trained that provides a negative feedback signal to the model to discourage it from learning domain specific representations.
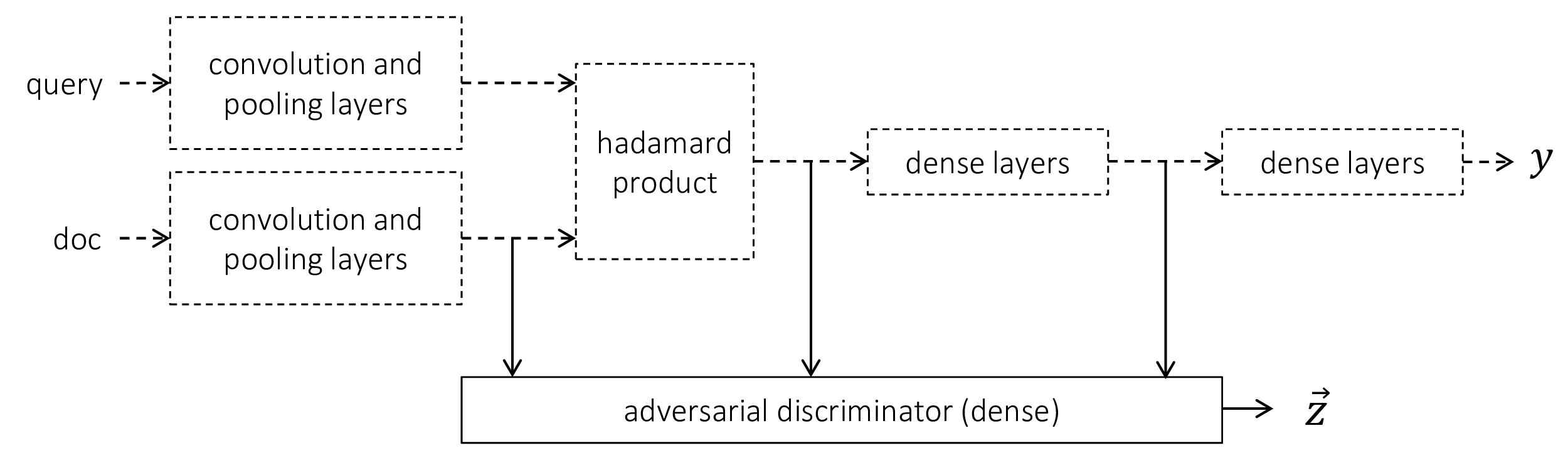
Figure 1 – Cross domain regularization using an adversarial discriminator. The discriminator inspects the learned representations of the ranking model and provides a negative feedback signal for any representation that aids domain discrimination.
The proposed adversarial approach shows consistent performance improvements over different deep neural baselines. However, we found that a model trained on large in-domain data is still likely to have a significant advantage over these models. Machine learning approaches to retrieval might need significantly more breakthroughs before achieving the level of robustness of some of the traditional retrieval models. In the meantime, improving robustness of these deep models will continue to be an important research challenge.
Reinforcement learning for effective and efficient query evaluations
Web search engines attempt to retrieve the top few relevant results by searching through collections containing billions of documents, often in under a second. To achieve such short response times, these systems typically employ large scale distributed indexes and specialized data structures. Typically, an initial set of candidates is identified that are progressively pruned and ranked by a cascade of retrieval models of increasing complexity. The index organization and query evaluation strategies explicitly trade off retrieval effectiveness and efficiency during the candidate generation stage. Unlike in late stage re-ranking where machine learning models are commonplace, the candidate generation frequently employs traditional retrieval models with few learnable parameters.
In Bing, the candidate generation involves scanning the index using statically designed match plans that prescribe sequences of different match criteria and stopping conditions. During query evaluation, the query is classified into one of a few pre-defined categories and based on this categorization a match plan is selected. Documents are scanned based on the chosen match plan which consists of a sequence of match rules and corresponding stopping criteria. A match rule defines the condition that a document should satisfy to be selected as a candidate for ranking and the stopping criteria decides when the index scan using a match rule should terminate — and whether the matching process should continue with the next match rule, or conclude, or reset to the beginning of the index. These match plans influence the trade-off between how quickly Bing responds to a search query and the quality of its results. For example, long queries with rare intents might require more expensive match plans that consider the body text of the documents and search deeper into the index to find more candidates. In contrast, for a popular navigational query a fast and shallow scan against a subset of the document fields—for example, URL and title—may be sufficient.
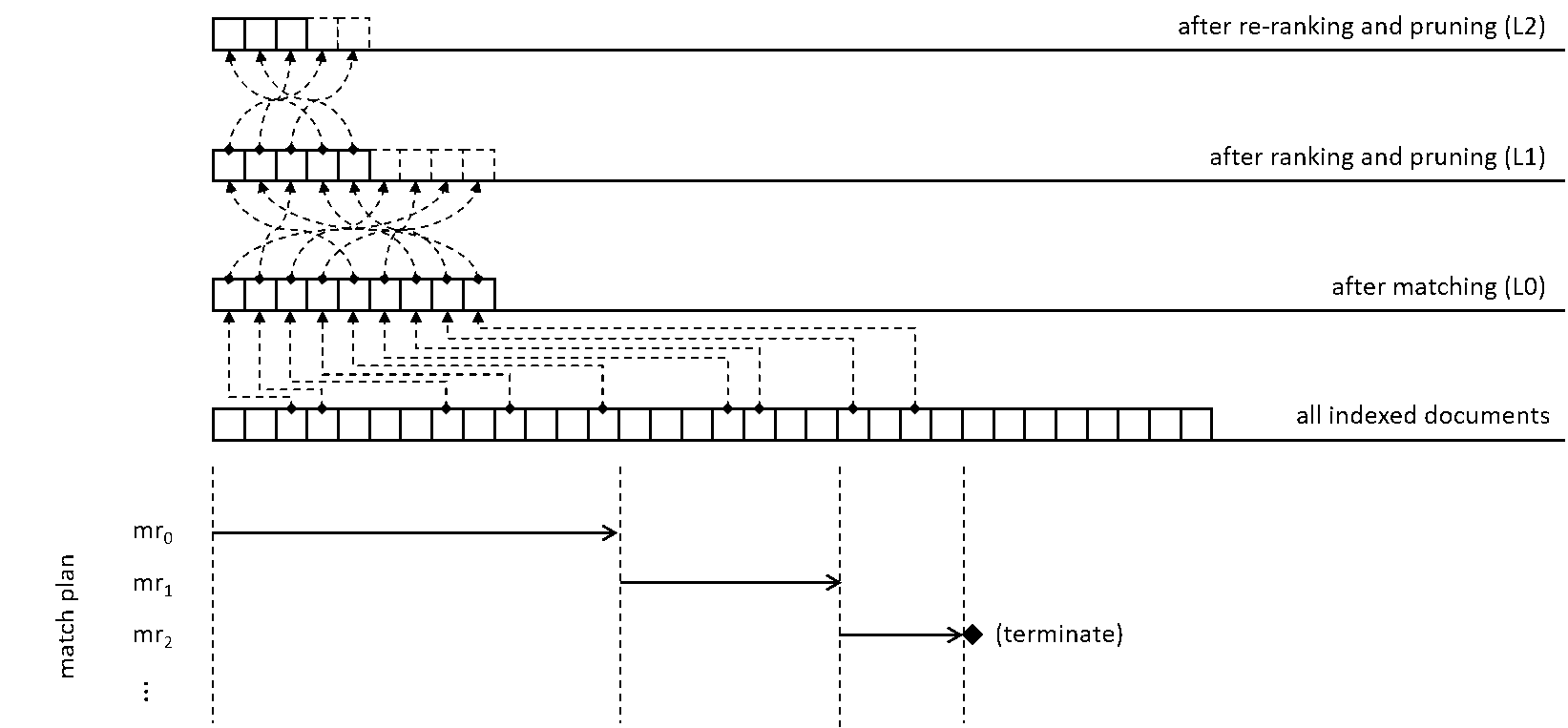
Figure 2 – A cascading architecture employed in Bing’s retrieval system. Documents are scanned using a pre-defined match plan. Matched documents are passed through additional rank-and-prune stages.
Sometime last year, we started thinking about casting the match planning process as a reinforcement learning task. After some experimentation, we managed to successfully learn a policy using table-based Q-learning that sequentially decides which match rules to employ during the candidate generation. We trained the model to maximize a cumulative reward computed based on the estimated relevance of the additional documents discovered, discounted by their cost of retrieval. By learning—instead of hand-crafting—these match plans, we observed significant reduction in the number of index blocks accessed with small or no degradations in the candidate set quality. You can find more information about this project in the paper titled “Optimizing Query Evaluations using Reinforcement Learning for Web Search (opens in new tab)”, by Corby Rosset, Damien Jose, Gargi Ghosh, myself, and Saurabh Tiwary.
In web search, machine learning models are typically employed to achieve better retrieval effectiveness by learning from large datasets, often in exchange for few additional milliseconds of latency. In this work, we argue that machine learning can also be useful for improving the speed of retrieval. Not only do these translate into material cost savings in query serving infrastructure, but milliseconds of saved run-time can be re-purposed by upstream ranking systems to provide better end-user experience.

Figure 3 – The co-authors of the two papers discussed in this post. (From left) Katja Hofmann, Bhaskar Mitra, W. Bruce Croft, Daniel Cohen, Damien Jose, Gargi Ghosh, Corby Rosset, and Saurabh Tiwary.
What’s next?
At Microsoft AI & Research, we are always exploring new ways to apply state of the art machine learning approaches to information retrieval and search. If you’re interested in learning more about some of our recent work in search and information retrieval, I encourage you to check out our recent publications. You can also find more information about the research that my team is focused on here. There are a lot of hard problems and exciting recent work in machine learning for search. If you’re interested in this area, please be sure to check out our overview paper on neural information retrieval.



