

Communication is a large part of who we are as human beings, and today, technology has allowed us to communicate in new ways and to audiences much larger and wider than ever before. That technology has assumed single-language speech, which — quite often — does not reflect the way people naturally speak. India, like many other parts of the world, is multilingual on a societal level with most people speaking two or more languages. I speak Bengali, English, and Hindi, as do a lot of my friends and colleagues. When we talk, we move fluidly between these languages without much thought.
This mixing of words and phrases is referred to as code-mixing or code-switching, and from it, we’ve gained such combinations as Hinglish and Spanglish. More than half of the world’s population speaks two or more languages (opens in new tab), so with as many people potentially code-switching, creating technology that can process it is important in not only creating useful translation and speech recognition tools, but also in building engaging user interface. Microsoft is progressing on that front in exciting ways.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
In Project Mélange, we at Microsoft Research India have been building technologies for processing code-mixed speech and text. Through large-scale computational studies, we are also exploring some fascinating linguistic and behavioral questions around code-mixing, such as why and when people code-mix, that are helping us build technology people can relate to. At the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) (opens in new tab), my colleagues and I have the opportunity to share some of our recent research with our paper “Word Embeddings for Code-Mixed Language Processing.”
A data shortage in code-mixed language
Word embeddings — multidimensional vector representation where words similar in meaning or used in similar context are closer to each other — are learnt using deep learning from large language corpora and are valuable in solving a variety of natural language processing tasks using neural techniques. For processing code-mixed language — say, Hinglish — one would ideally need an embedding of words from both Hindi and English in the same space. There are standard methods for obtaining multilingual word embeddings; however, these techniques typically try to map translation equivalents from the two languages (e.g., school and vidyalay) close to each other. This helps in cross-lingual transfer of models. For instance, a sentiment analysis system trained for English can be appropriately transferred to work for Hindi using multilingual embeddings. But it’s not ideal for code-mixed language processing. While school and vidyalay are translation equivalents, in Hinglish, school is far more commonly used than vidyalay; also, these words are used in slightly different contexts. Further, there are grammatical constraints on code-mixing that disallow certain types of direct word substitutions, most notably for verbs in Hinglish. For processing code-mixed language, the word embeddings should ideally be learnt from a corpus of code-mixed text.
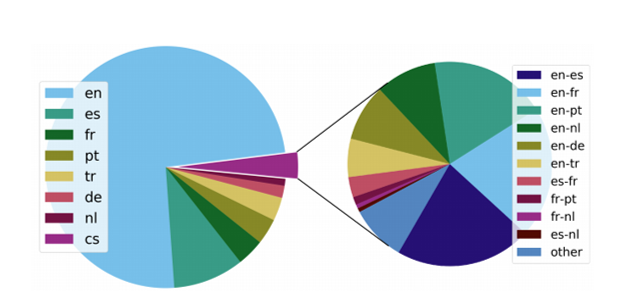
It is difficult to estimate the amount of code-mixing that happens in the world. One good proxy is the code-mixing patterns on social media. Approximately 3.5 percent of the tweets on Twitter are code-mixed. The above pie charts show the distribution of monolingual and code-mixed, or code-switched (cs), tweets in seven major European languages: Dutch (nl), English (en), French (fr), German (de), Portuguese (pt), Spanish (es), and Turkish (tr).

The chart above shows the distributions of monolingual and code-mixed tweets for 12 major cities in Europe and the Americas that were found to have very large or very small fractions of code-mixed tweets, represented in the larger pies by the missing white wedge. The smaller pies show the top two code-mixed language pairs, the size being proportionate to their usage. The Microsoft Research India team found that code-mixing is more prevalent in cities where English is not the major language used to tweet.
Even though code-mixing is extremely common in multilingual societies, it happens in casual speech and rarely in text, so we’re limited in the amount of text data available for code-mixed language. What little we do have is from informal speech conversations, such as interactions on social media, where people write almost exactly how they speak. To address this challenge, we developed a technique to generate natural-looking code-mixed data from monolingual text data. Our method is based on a linguistic model known as the equivalence constraint theory of code-mixing, which imposes several syntactic constraints on code-mixing. In building the Spanglish corpus, for example, we used Bing Microsoft Translator to first translate an English sentence into Spanish. Then we aligned the words, identifying which English word corresponded to the Spanish word, and in a process called parsing identified in the sentences the phrases and how they’re related. Then using the equivalence constraint theory, we systematically generated all possible valid Spanglish versions of the input English sentence. A small number of the generated sentences were randomly sampled based on certain criteria that indicated how close they were to natural Spanglish data, and these sentences comprise our artificial Spanglish corpus. Since there is no dearth of monolingual English and Spanish sentences, using this fully automated technique, we can generate as large a Spanglish corpus as we want.
Solving NLP tasks with an artificially generated corpus
Through experiments on parts-of-speech tagging and sentiment classification, we showed that word embeddings learnt from the artificially generated Spanglish corpus were more effective in solving these NLP tasks for code-mixed language than the standard cross-lingual embedding techniques.
The linguistic theory–based generation of code-mixed text has applications beyond word embeddings. For instance, in one of our previous studies published earlier this year, we showed that this technique helps us in learning better language models that can help us build better speech recognition systems for code-mixed speech. We are exploring its application in machine translation to improve the accuracy of mixed-language requests. And imagine a multilingual chatbot that can code-mix depending on who you are, the context of the conversation, and what topic is being discussed, and switch in a natural and appropriate way. That would be true engagement.