
During the Tang dynasty of China, which lasted from 618 to 907, the poet Jia Dao was known for polishing his poems over and over to make them better and better. One famous story describes how he deliberated over two lines of a poem that read, “Birds nestle in the trees by the pond. A monk pushes the door in the moonlight.” Dao concentrated on the word “pushes.” He considered using “knocks” instead. After a long period of deliberation, he chose “knocks” because it provides contrast to the tranquil atmosphere of the suburban night. Such a careful re-thinking process led to a beautiful poem that continues to spread:

The story about Dao’s deliberation over the words “pushes” and “knocks” demonstrates an important human cognitive process: To compose great literary works, the first draft is typically a base to build on and polish until it yields the final version. The same is true in the process of writing academic papers; first drafts are usually written by students and then revised or re-written by their supervisors. In these cases, the first draft is typically unsatisfactory but provides a global textual skeleton for retouching and revision. The polishing process, which we call deliberation, improves the quality.
video series

On Second Thought
A video series with Sinead Bovell built around the questions everyone’s asking about AI. With expert voices from across Microsoft, we break down the tension and promise of this rapidly changing technology, exploring what’s evolving and what’s possible.
In a paper presented at the 2017 Neural Information Processing Systems (opens in new tab) conference in Long Beach, California, we describe our Deliberation Network that we developed to enhance artificial intelligence, in particular natural language generation. Our network is inspired by the human process of deliberation.
We start with the basic neural machine translation structure: the sequence-to-sequence model, shown in Figure 1. To translate a sentence in a source language, for example the Chinese sentence “微软亚洲研究院即将迎来二十周年诞辰,” we first use a neural network called an encoder to scan over it and then pass the output to another neural network called the decoder. Based on the encoder’s output, the decoder will generate each translated word in the target language, for example, in this case, “Microsoft Research is about to have twenty birthday,” which is a rough translation.

Figure 1: Basic sequence-to-sequence structure to perform translation.
As Figure 1 shows, there is only one generation process in this framework. That is, the generation result via the decoder is set as the final translation. We refer to such a decoder as the first pass decoder. To add the deliberation process, we added another decoder, the second pass decoder, to the network structure, which is illustrated in Figure 2.
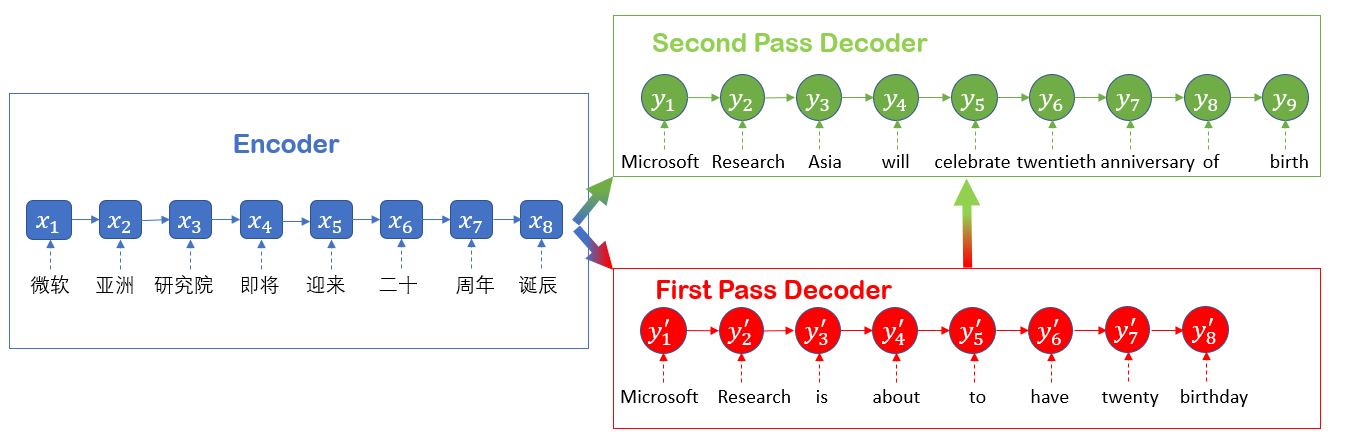
Figure 2: The structure of Deliberation Network.
The second pass decoder expands the translation process to two steps: the first pass decoder first reads the encoder’s encoding result for the source sentence x and outputs a rough, or first-draft, translation sentence, denoted as y’. Then, the second pass decoder takes both x and y’ as inputs to generate the final translation y. The second step is the deliberation process: the y’ output via the first pass decoder acts as the draft, which is revised into y via automatic learning using a deep neural network. An example is shown in Figure 2: the original translation, “Microsoft Research is about to have twenty birthday” is revised to: “Microsoft Research Asia will celebrate twentieth anniversary of birth.”
We verify the effectiveness of our Deliberation Network on a large benchmark dataset, the English-French translation campaign from the Ninth Workshop on Statistical Machine Translation (opens in new tab) in 2014, which contains about 36 million training data and 3 thousand test data. The results are shown in Table 1. The baseline systems include several of the most powerful neural machine translation systems in the current literature such as We conclude that, together with our previous dual learning technique to effectively leverage monolingual data, we achieve the best single model performance (41.50) on this task using Deliberation Network, on top of a simple stack LSTM architecture (opens in new tab).
| System | Configurations | BLEU |
| GNMT (opens in new tab) | 8-8 stacked LSTM encoder and decoder + RL finetune | 39.92 |
| FairS2S (opens in new tab) | 15-15 convolutional encoder and decoder | 40.51 |
| Transformer (opens in new tab) | 6-6 self-attention encoder and decoder | 41.0 |
| This work | 4-4 stacked LSTM encoder and decoder | 39.51 |
| +Dual learning | 40.53 | |
| +Dual learning + Deliberation Network | 41.5 |
Related: