
Part 1: Introduction
Probably every piece of software has some defects in it. Known defects (also called bugs) are found by manufacturers and users and fixed. Unknown ones remain there, waiting to be discovered some day.
The question is: how big is that unknown set?
One approach to that problem is presented here. It is not the most precise and definitely has some limitations. But it is relatively simple and straightforward to derive, with no secret know-hows, so I decided to share it.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Every time I mention “counting unknown bugs” questions arise that are worth a little FAQ, so here it is:
Q: Why would your even need to know the count of unknown bugs?
A: First, it sets the expectations. Knowing how many bugs are still there provides an upper cup on your support/response story. Second, it provides a quantitative assessment of the engineering effectiveness, by comparing what’s been found to what still remains in there.
Q: Is it even possible to count all unknown bugs?
A: Strictly speaking, no. Some “bugs” are infinite by nature (e.g., new feature suggestions). Some bug may belong to classes yet unknown — for example, there was no way count CSRF bugs before CSRF was invented. So we are talking here about counting unknown bugs of known, specific class/nature, defined at the today’s level of technology.
Q: Any examples of those classes?
A: It’s got to be something of a common nature, with similar lifetime, discovery methods, and statistical properties. For instance:
- Memory corruption issues
- XSS bugs
- Performance degradations above certain threshold
- Errors in documentation
- Setup failures
Q: The idea of “total bug count” looks like an abstract theory rather than something with a practical meaning. Is it anything material?
A: To translate that into a practical world, think these measurable examples:
- The total number of bugs to be found with current discovery methods if testing continues indefinitely
- The number of bugs to be reported by customers if the last version of the product remains on the market for infinite time
Q: Fine, the theory may look good, but can it be validated? Does it have a predictive power?
A: Here are some ways to validate it that I see.
The first is side by side products comparison. If products A and B of similar functionality and similar user base have vastly different hidden bug counts, it is reasonable to expect that their post-release defects discovery rates would be similarly different.
Second, this method derives an analytical description of some bug curves over time. That equals to a long-term bug discovery rate forecast. Unfortunately, I had a chance to do only very rudimentary work on such forecasting so this still needs more research. Yet this approach could probably be used for validation purposes as well.
With that, let’s go to the theory.
While I did my best to verify the correctness of calculations, they may still contain errors, so I assume no responsibility for using (or not using) them.
The method presented here is a research work and carries no guarantees.
Opinions expressed in the post do not necessarily reflect those of my employer (Microsoft). My recommendations in no way imply that Microsoft officially supports them or recommends doing the same. Any phrases where it may look as if I don’t care about customer’s security, or recommend practices that seemingly increase the risk should be treated as purely accidental failures of expression. No figures or statements given here imply any conclusions about the actual state of security of any Microsoft products. All numeric figures are purely fictitious examples.
The intent of this text is to share the knowledge and improve security of software products across the industry. The emotional content represents my personal ways of writing rather than any part of the emotional atmosphere within the company.
Part 2: Ideal World Theory
The approach is based on the Capture & Recapture (opens in new tab) method that has been used in biology and criminalistics since at least 1930s. Conceptually, it is very simple.
When two entities independently search for something in a shared space (e.g., for birds in a forest), they occasionally may stumble upon each other’s past discoveries. The tighter the space to search is the more often bumping into each other’s finds will occur. By measuring the frequency of such encounters it is possible to reason about the total size of the space being searched.
To formalize it, let’s use a fictitious product example. In that product, no bug fixes or code changes ever happen at all. Two groups of people randomly and independently of each other look for bugs in it. The first group is called Internal Engineering, the 2nd — External Attackers Researchers. Think of them as of two projectors randomly scooping with light rays through the product and sometimes highlighting the same spots:
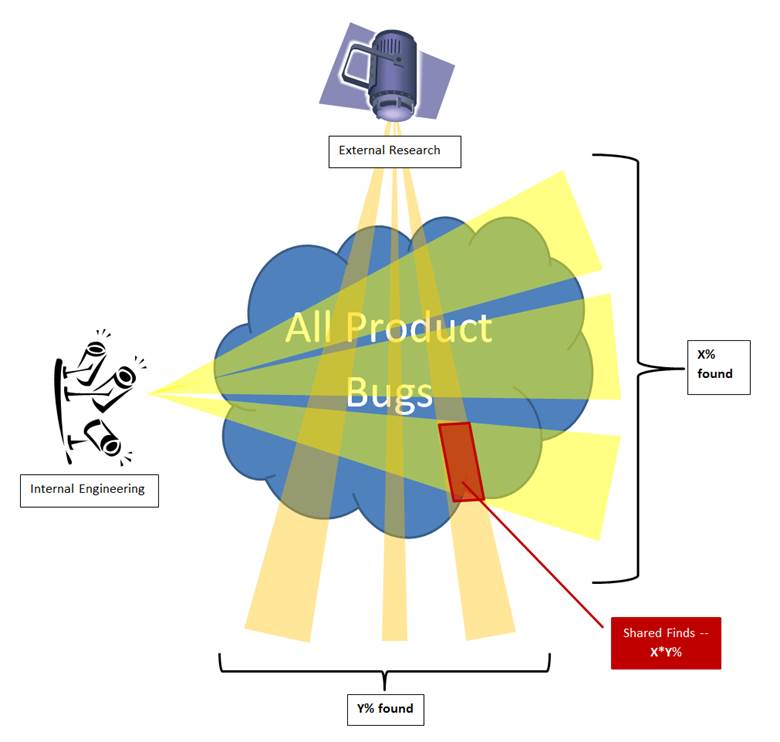
Let’s put that into basic math:
Let B be the total count of bugs of a particular class in the product, both known and unknown.
Detection effectiveness of the Internal Engineering process is y per year. That means, they find I = y*B bugs in one year.
Detection & reporting effectiveness of External Researchers is x. They find and report E = x*B bugs through the same time.
If these processes are independent, then it does not matter whether External Researchers are looking for already known or yet unknown bugs. In either case their chances of success are x. Therefore they will find x of those bugs that have already been found internally, which would be x*I bugs. These are the shared bugs, known to both Internal and External parties. Let’s denote their count through S = x*I.
Now let’s substitute into that the already known value of I = y*B, so S = x*I = x*y*B.
Then let’s construct an expression of the form I*E/S. What does it evaluate to?
It’s easy: I*E/S = (y*B)*(x*B)/(y*x*B) = (y*B)*(x*B)/(x*y*B) = B*B/B = B.
In other words, the total number of bugs (both known and unknown) in such an ideal product is estimated simply as:
B = I*E/S [10]
For example, let’s say that in one year Internal Engineering has found 40 bugs in a product. External Researchers have found 20 bugs in the same time, and out of those twenty 4 bugs were the same as internally known bugs. That means, Externals were capable of detecting 4/20 = 20% of known bugs. If unknown bugs are not fundamentally different, that means Externals’ detection rate is also 20% for unknown (and all) bugs. And that 20% efficiency is represented by 20 external discoveries. Therefore, the total bug count in the system is 20/0.20 = 100.
Although very simple, formula [10] already enables reasonable estimates in many cases. If a product in question is not changing much through the duration of observation, just multiplying the number of internal finds by the number of external ones, and dividing that by the number of shared bugs is sufficient to assess the remaining defects count.
And how do you count shared bugs? Make a list of bugs that affected version 1.0. Cross out those that also affected 2.0. The remaining are those that hit 1.0 exclusively. So most likely we did something to 2.0 that has prevented those bugs. Look at the 2.0’s code where those bugs originally were in version 1.0. See what’s changed there. Often, that would be a fix to an internally found bug. Often something completely oblivious of the externally reported problem :)) Yet this is a shared find. Count it.
Another source is your Duplicate bugs. See if any of them are resolved to the externally reported cases.
