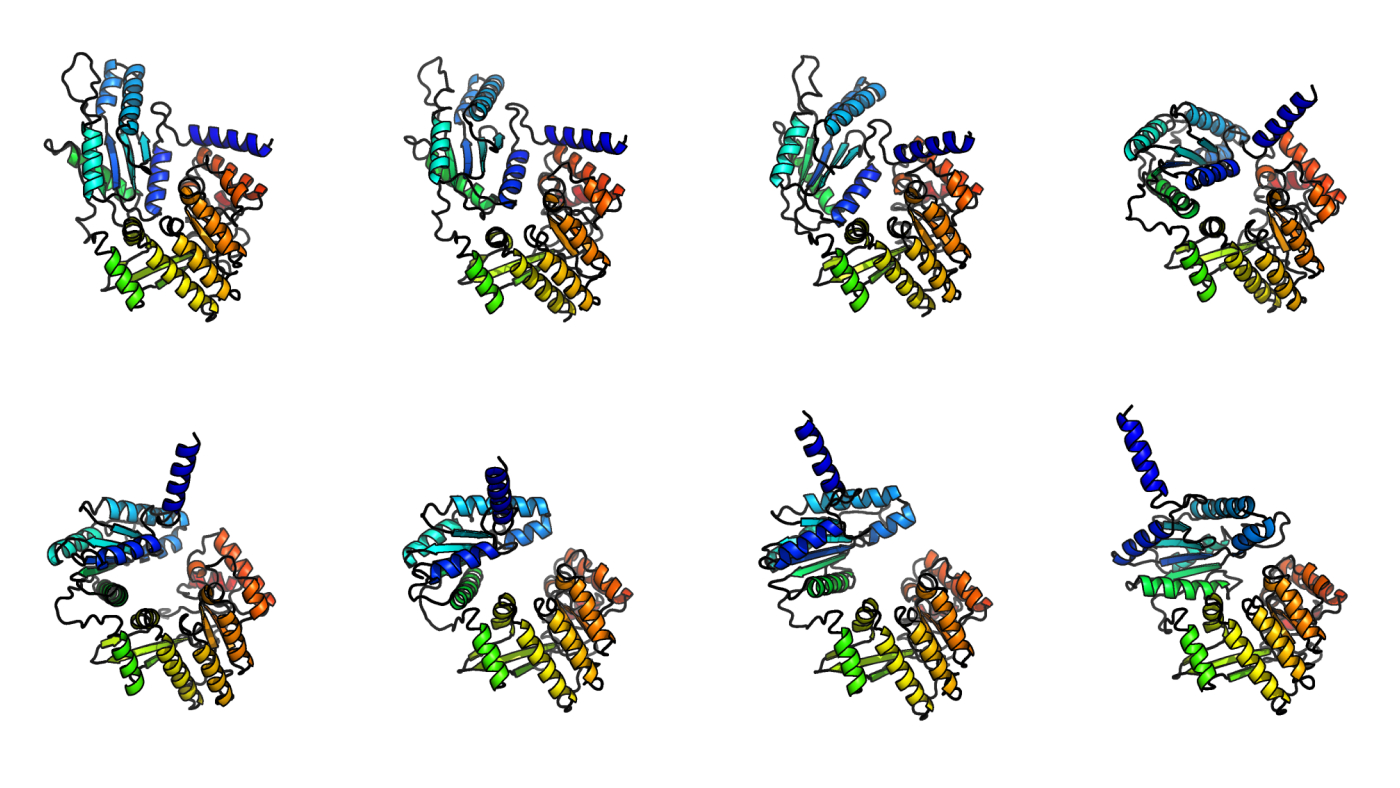
Scientific research breakthroughs are often achieved when many different scientists, in different labs and organizations, work together on a single task. That happened at the turn of the 21st century with the Human Genome Project, where human DNA was mapped for future reference and is now key to many breakthroughs in medicine. This is happening again, with a similarly visionary effort: the Human Proteome Project (HUPO (opens in new tab)), which is cataloging all 20,000 human proteins, such as insulin, toward the goal of treating and preventing many diseases. Many diseases are a result of changes in protein configuration and function, so scientists are eager to grow their knowledge in this area.
A key resource in the HUPO project is something called the Peptide Atlas, which is being spearheaded by the Seattle-based Institute for System Biology (opens in new tab) (ISB). Peptide Atlas is a catalog of the peptides, or building blocks of proteins, delineated through their mass spectrometry (MS) data, or “spectra.” It becomes the reference guide for all scientists doing proteomics work—they can see if the peptides they are working with are cataloged, and what spectra matches a particular peptide, a necessary precursor toward understanding proteins at a deeper level.
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the first four episodes on demand.
Here’s where Microsoft gets involved, with donated Azure credits to this effort.
Dozens, if not hundreds, of labs submit results and data to the Peptide Atlas; but the plethora of MS manufacturers and lab techniques, in addition to different research agendas, means the data submitted isn’t apples to apples. Post processing of the datasets needs to happen, and when you’re dealing with 20,000 proteins, each of which may have 50 peptides that need to be identified and catalogued, it becomes a big data challenge.
In addition, the technology used for matching spectra to peptides keeps improving and much of the existing data set needs to be reprocessed by using more up-to-date algorithms.
Through grants of Azure resources donated by Microsoft and made available through the West Big Data Hub (opens in new tab), ISB has the compute resources to do this important data processing work. Instead of their software scientists taking up all the ISB’s internal computer processing resources, they can use thousands of low priority inexpensive cores of Azure in the cloud to offload much of the challenge, both speeding the task through Azure Batch processing, and freeing up internal resources for ISB scientists to use on other projects.
The Big Data Hubs are a National Science Foundation (opens in new tab)-sponsored effort that supplies cloud computing credits to large scientific projects. In addition to the Azure credits donated by Microsoft, ISB received a Spoke Project Planning Grant from NSF to facilitate interactions between experts from the genomic variant and protein structure communities, with the goal of developing methods for integrating data. Eventually, every proteomics researcher will be able to access this data and run their algorithms on it, in the cloud.
And Microsoft will be there to help.