
 Significant advances are being made in artificial intelligence, but accessing and taking advantage of the machine learning systems making these developments possible can be challenging, especially for those with limited resources. These systems tend to be highly centralized, their predictions are often sold on a per-query basis, and the datasets required to train them are generally proprietary and expensive to create on their own. Additionally, published models run the risk of becoming outdated if new data isn’t regularly provided to retrain them.
Significant advances are being made in artificial intelligence, but accessing and taking advantage of the machine learning systems making these developments possible can be challenging, especially for those with limited resources. These systems tend to be highly centralized, their predictions are often sold on a per-query basis, and the datasets required to train them are generally proprietary and expensive to create on their own. Additionally, published models run the risk of becoming outdated if new data isn’t regularly provided to retrain them.
We envision a slightly different paradigm, one in which people will be able to easily and cost-effectively run machine learning models with technology they already have, such as browsers and apps on their phones and other devices. In the spirit of democratizing AI, we’re introducing Decentralized & Collaborative AI on Blockchain (opens in new tab).
Through this new framework, participants can collaboratively and continually train and maintain models, as well as build datasets, on public blockchains, where models are generally free to use for evaluating predictions. The framework is ideal for AI-assisted scenarios people encounter daily, such as interacting with personal assistants, playing games, or using recommender systems. An open-source implementation for the Ethereum blockchain (opens in new tab) is available on GitHub (opens in new tab), and our paper “Decentralized & Collaborative AI on Blockchain“—co-authored by myself and Bo Waggoner (opens in new tab), a postdoc researcher with Microsoft at the time of the work—will be presented at the second IEEE International Conference on Blockchain (opens in new tab) July 14–17.
Why blockchain?

Azure AI Foundry Labs
Get a glimpse of potential future directions for AI, with these experimental technologies from Microsoft Research.
Leveraging blockchain technology allows us to do two things that are integral to the success of the framework: offer participants a level of trust and security and reliably execute an incentive-based system to encourage participants to contribute data that will help improve a model’s performance.
With current web services, even if code is open source, people can’t be 100 percent sure of what they’re interacting with, and running the models generally requires specialized cloud services. In our solution, we put these public models into smart contracts (opens in new tab), code on a blockchain that helps ensure the specifications of agreed upon terms are upheld. In our framework, models can be updated on-chain, meaning within the blockchain environment, for a small transaction fee or used for inference off-chain, locally on the individual’s device, with no transaction costs.
Smart contracts are unmodifiable and evaluated by many machines, helping to ensure the model does what it specifies it will do. The immutable nature and permanent record of smart contracts also allows us to reliably compute and deliver rewards for good data contributions. Trust is important when processing payments, especially in a system like ours that seeks to encourage positive participation via incentives (more to come on that later). Additionally, blockchains such as Ethereum have thousands of decentralized machines all over the world (opens in new tab), making it less likely a smart contract will become completely unavailable or taken offline.
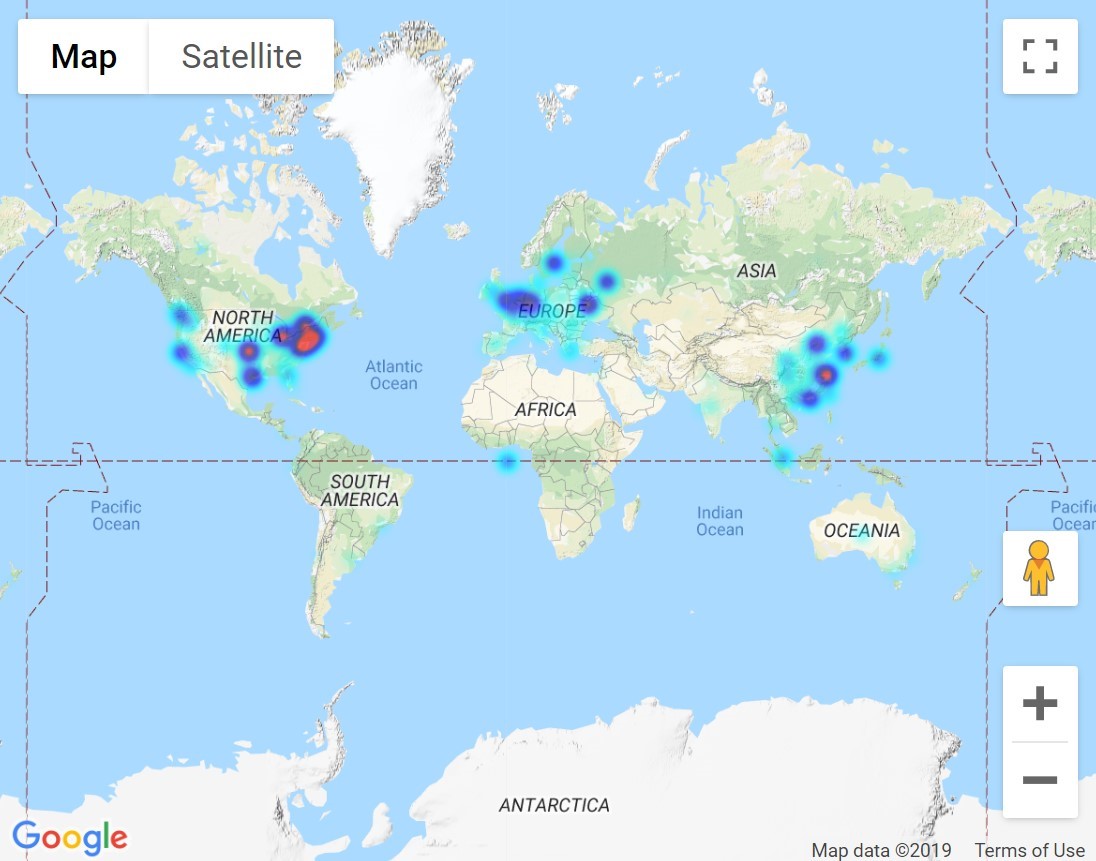
Ethereum nodes are located around the world. Locations are as of July 4, 2019. Source: https://www.ethernodes.org (opens in new tab)
Deploying and updating models
Hosting a model on a public blockchain requires an initial one-time fee for deployment, usually a few dollars, based on the computational cost to the blockchain network. From that point, anyone contributing data to train the model, whether that be the individual who deployed it or another participant, will have to pay a small fee, usually a few cents, again proportional to the amount of computation being done.
Using our framework, we set up a Perceptron (opens in new tab) model capable of classifying the sentiment, positive or negative, of a movie review. As of July 2019, it costs about USD0.25 to update the model on Ethereum. We have plans to extend our framework so most data contributors won’t have to pay this fee. For example, contributors could get reimbursed during a reward stage or a third party could submit the data and pay the fee on their behalf when the data comes from usage of the third party’s technology, such as a game.
To reduce computational costs, we use models that are very efficient to train with such as a Perceptron or a Nearest Centroid Classifier (opens in new tab). We can also use these models along with high-dimensional representations computed off-chain. More complicated models could be integrated using API calls from the smart contract to machine learning services, but ideally, models would be kept completely public in a smart contract.
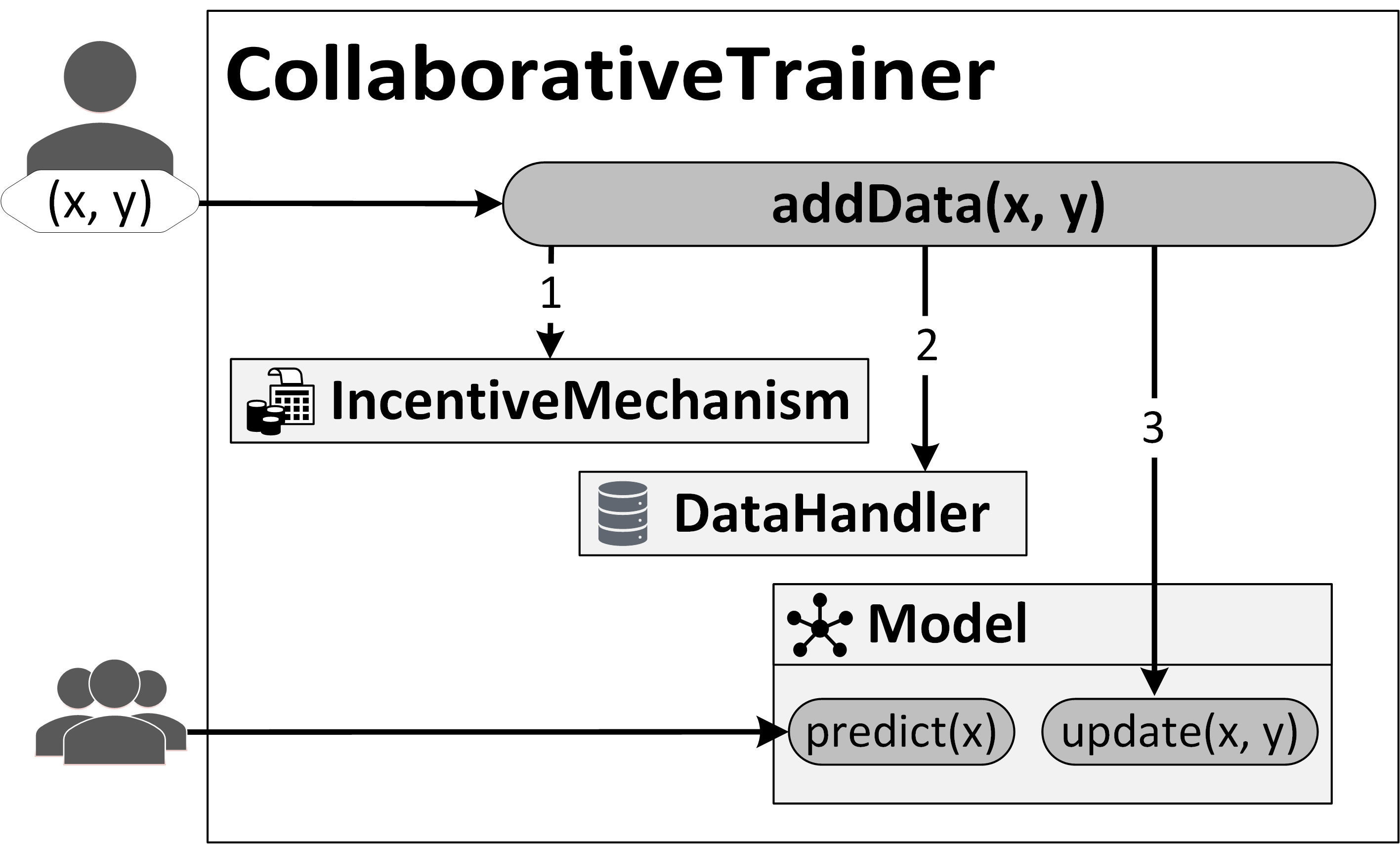
Adding data to a model in the Decentralized & Collaborative AI on Blockchain framework consists of three steps: (1) The incentive mechanism, designed to encourage the contribution of “good” data, validates the transaction, for instance, requiring a “stake” or monetary deposit. (2) The data handler stores data and metadata onto the blockchain. (3) The machine learning model is updated.
Incentive mechanisms
Blockchains easily let us share evolving model parameters. Newly created information such as new words, new movie titles, and new pictures can be used to update existing models hosted regardless of a specific person or organization’s ability to update and host the model themselves. To encourage people to contribute new data that will help maintain the model’s performance, we propose several incentive mechanisms: gamified, prediction market–based, and ongoing self-assessment.
Gamified: Like on Stack Exchange (opens in new tab) sites, data contributors can earn points and badges when other contributors validate their contributions. This proposal relies solely on the willingness of contributors to collaborate for a common good—the betterment of the model.
Prediction market–based: Contributors get rewarded if their contribution improves the performance of the model when evaluated using a specific test set. This proposal builds on existing work using prediction market (opens in new tab) frameworks to collaboratively train and evaluate models, including “A Collaborative Mechanism for Crowdsourcing Prediction Problems (opens in new tab)” and “A Market Framework for Eliciting Private Data. (opens in new tab)”
The prediction market–based incentive in our framework has three phases:
- A commitment phase in which a provider stakes a bounty to be awarded to contributors and shares enough of the test set to prove the test set is valid
- A participation phase in which participants submit training data samples with a small deposit of funds to cover the possibility their data is incorrect
- A reward phase in which the provider reveals the rest of the test set and a smart contract validates it matches the proof provided in the commitment phase
Participants are rewarded based on how much their contribution helped the model improve. If the model did worse on the test set, then participants who contributed “bad” data lose their deposit.
Here is how the process looks when running in a simulation:

For this simulation, a Perceptron was trained on the IMDB reviews dataset for sentiment classification (opens in new tab). The participants contributing “good” data profit, the participants contributing “bad” data lose their funds, and the model’s accuracy improves. This simulation represents the addition of about 8,000 training samples.
Ongoing self-assessment: Participants effectively validate and pay each other for good data contributions. In such scenarios, an existing model already trained with some data is deployed. A contributor wishing to update the model submits data with features \(x\), label \(y\), and a deposit. After some predetermined time has passed, if the current model still agrees with the classification, then the person gets their deposit back. We now assume the data has been validated as “good,” and that contributor earns a point. If a contributor adds “bad” data—that is, data that cannot be validated as “good”—then the contributor’s deposit is forfeited and split among contributors who’ve earned points for “good” contributions. Such a reward system would help deter the malicious contribution of “bad” data.
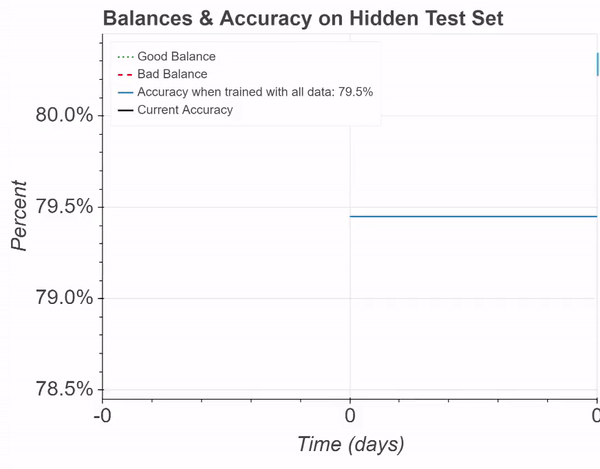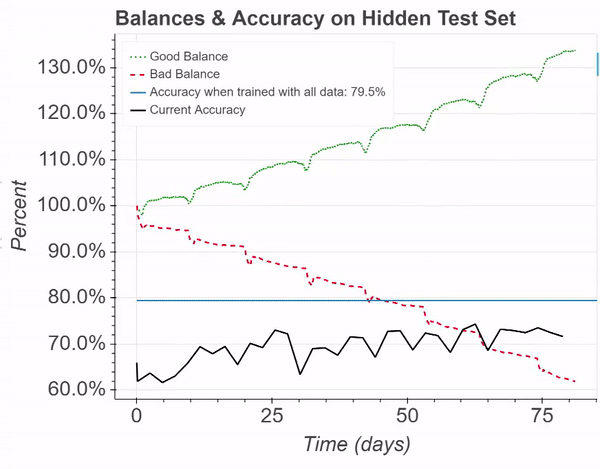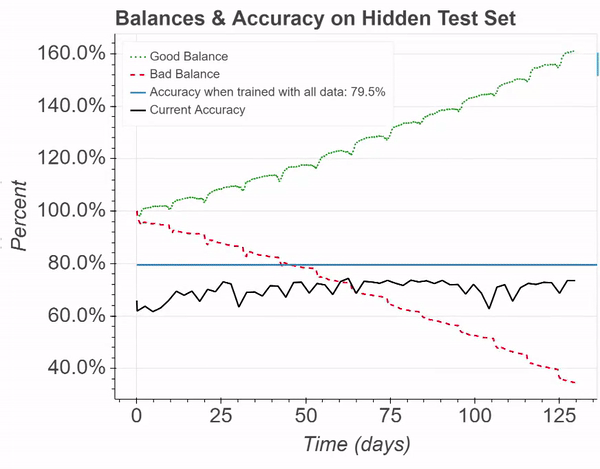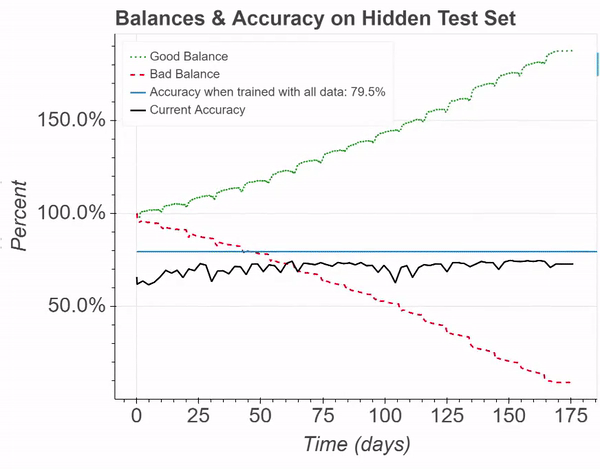
For this simulation, a Perceptron was again trained on the IMDB reviews dataset for sentiment classification (opens in new tab). This figure demonstrates balance percentages and model accuracy in a simulation where an adversarial “bad contributor” is willing to spend more than an honest “good contributor.” Despite the malicious efforts, the accuracy can still be maintained, and the honest contributor profits. This simulates the addition of about 25,000 training samples.
From the small and efficient to the complex
The Decentralized & Collaborative AI on Blockchain framework is about sharing models, making valuable resources more accessible to all, and—just as importantly—creating large public datasets that can be used to train models inside and outside the blockchain environment.
Currently, this framework is mainly designed for small models that can be efficiently updated. As blockchain technology advances, we anticipate that more applications for collaboration between people and machine learning models will become available, and we hope to see future research in scaling to more complex models along with new incentive mechanisms.