
Talking to machines to get things done
We have become familiar with talking to personal assistants such as SIRI or Cortana to get simple tasks accomplished. A popular feature is setting reminders: it is more efficient to say everything in one sentence instead of entering several fields (task name, day, time etc) manually on a phone screen. More recently, text-based conversational agents (or chatbots) have been made easier to access and develop through platforms such as Facebook Messenger. We can still say everything in one sentence, but we can directly type it and avoid talking out loud in the street or dealing with bad speech recognition in noisy environments.
Conversational agents, whether in research or in industry, have been mostly designed so far for one use-case: the user knows exactly which tasks she wants to accomplish. For this particular use-case, there is no need for any complex interaction: the conversational agent simply needs to gather all the information necessary to accomplish the task. The same process is used for information seeking. For instance, if you look for a restaurant through a chatbot, the bot will ask for some criteria (e.g., type of food) and return a few results.
A need for memory
Restaurant-seeking is a simple task because there are few parameters. We are working towards the next generation of chatbots and we have decided to tackle the more complex task of vacation planning. In this case, many parameters need to be decided: hotel type, destination, budget, flight time and so on. Not only are there more parameters, but these parameters are often quite vague: you might want to go to South America but you don’t know exactly which country you want to visit first; you have preferences for hotels but are ready to compromise, etc. In this setting, there is a decision-making process, and this process is based on preferences and constraints, but also on the available vacation packages.

Azure AI Foundry Labs
Get a glimpse of potential future directions for AI, with these experimental technologies from Microsoft Research.
Supporting this kind of decision-making process in conversational systems implies adding memory. Memory is necessary to track different vacation packages or preferences set by the user during the dialogue. For instance, consider comparisons. If a user wants to compare different vacation packages, then the conversational agent should be able to recall all the properties pertaining to each package.
We need to switch from the sequential information-seeking process to a process that enables users to consider different options, go back and forth between packages, and make up their minds based on the available options.

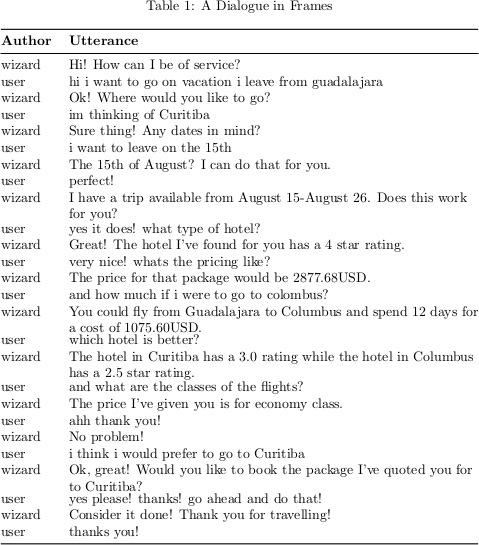
To build such a system, we need adequate data. We have published a paper (opens in new tab) and developed a dataset for academic research (opens in new tab) comprising dialogues that require memory. Microsoft Research Montreal’s Frames dataset is a corpus of 1,369 human-human dialogues collected by humans role-playing a dialogue between a customer and a travel agent. The person playing the customer role had a vague idea of wanting to take a vacation and asked many questions to the travel agent – flights, hotels, destinations and so on.
Collection methodology
To build the Frames dataset, a team of 12 human participants collected data over a period of 20 days. We deployed a Slack bot to allow participants to converse with each other. Participants were encouraged to use natural language. At the beginning of each dialogue, the participant who was playing the role of the user was given an objective to find a vacation package given a few constraints. Examples of constraints are: a certain number of people, a particular destination, a rigid budget. Where no packages were available, the user would either end the dialogue or change a few of her constraints. On the other side, the wizards (participants playing the role of the chatbot) received a link to a search interface every time a user was connected with them. The search interface was a simple GUI with all the searchable fields in the database:
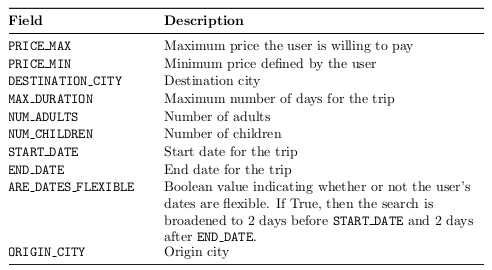
At the conclusion of the dialogue, the users were asked to rate the cooperativity of the wizards, on a scale of 1 to 5.
Frame tracking
In order to measure and test the memory capabilities of conversational agents, we formalize a new task called frame tracking. In frame tracking, the conversational agent must simultaneously track multiple semantic frames throughout the dialogue. A semantic frame can be see as a summary of the dialogue: it contains the user’s preferences and the user’s questions. Frame tracking is an extension of state tracking. In state tracking, all the information summarizing dialogue history is compressed into one semantic frame. This is what is used for sequential information-seeking. This implies that if the user changes the value of a constraint, this value overwrites the previous one so there is no way to return to any earlier state of the dialogue. Since in our dataset, users can compare different options, we need to keep track of these options in separate frames.
We create a new frame for each new set of user preferences. For instance, if the user mentions going to Mexico City after talking about going to Buenos Aires, we end up with two frames: one for Mexico City and one for Buenos Aires. Complete vacation packages are also assigned to separate frames to enable users to compare them.
We can visualize statistics for frame creation and frame switching in the dataset:

The average number of frame changes per dialogue is 3.58, for an average of 6.71 frames created. This shows the variety of behaviors encountered in this dataset: some users will pick the first offer that looks good, whereas others will consider different options before picking one.
We formalize the frame tracking task and propose a baseline in the paper.
“This is an important new dataset that extends standard dialogue tasks into areas such as comparison and exploration of different customer options,” said Dr. Oliver Lemon, Professor, School of Mathematical and Computer Sciences (MACS), Heriot-Watt University. “Building conversational systems which can support such tasks is a fascinating challenge, and this dataset will help us to do that.”

Other topics of research
Dialogue management
A notable aspect of the dataset is that memory also impacts dialogue management. The wizards in the corpus did not always talk about the current frame, for instance, the current package that the user is considering. Sometimes, they spontaneously talked about previous packages. A conversational agent that would act as naturally as the wizards in this corpus would need to learn to make a similar use of its memories. In other words, if frame tracking provides the memories, the dialogue manager will need to learn how to use them efficiently and timely.
Another novelty for dialogue management is the ability to perform several actions in one turn. By actions, we mean for example, answering a question asked by the user, or proposing a package. It is novel because in previous datasets and previous dialogue management models, the conversational agent would only be able to perform one action. Performing several actions will help make dialogues more efficient by conveying richer information to the user at each turn.
Natural language generation
We observed that wizards often tended to summarize database results, i.e., all the packages matching the user’s constraints at a given point of the dialogue. Rather than just proposing a specific package, the wizard often would include additional information that is relevant. For example, the wizard may say “The cheapest available package that I have is $1,947.14” rather than simply saying “I have a package for $1,947.14”.
In this example, the wizard adds the information that this package is the cheapest one based on the list of packages that she has access to. In order to emulate this behavior, a conversational agent would need to reason over the database results to decide on an optimal way to present the information to the user.
“Having access to datasets such as Microsoft Research Montreal’s Frames is invaluable in helping AI researchers drive breakthroughs in goal-oriented dialogue,” said Dr. Verena Rieser, Associate Professor, School of Mathematical and Computer Sciences (MACS), Heriot-Watt University. “At the MACS Interaction Lab, this dataset will greatly benefit the academic research we are conducting in spoken dialogue systems and response generation.”
Enabling more capable conversational agents
With the rise in messaging platforms, mobile devices and in-home devices making use of text or chat as an interface, there will be an increased demand for capable conversational agents. Our research and the development of the Frames dataset will serve as a valuable tool to help dialogue researchers build goal-oriented dialogue systems that can handle multiple items. We propose that adding memory is a first milestone towards goal-oriented dialogue systems that support more complex dialogue flows. Further work will consist of proposing models for frame tracking as a well as proposing a methodology to scale data collection and annotation.
We welcome the academic research community to make use of our dataset.
