

Much research in AI lately focuses on extending the capabilities of deep learning architectures: moving beyond simple classification and pattern recognition into the realm of learning algorithmic tasks, such as inductive programming. Building on our past work in neural program synthesis for learning string transformations in a functional language, our most recent work explores the challenges of training neural architectures for inducing programs in a more challenging imperative language (Karel) with complex control-flow.
Specifically, we are working to address the difficulty of program induction when a limited number of examples are available. Traditionally, neural program induction approaches rely on extremely large number of input-output examples—often on the order of hundreds of thousands to millions of examples—to achieve acceptable results. A portion of our research was directed at developing new techniques that can be used with significantly fewer examples. These new techniques, generally termed “portfolio adaptation” and “meta program induction,” rely on knowledge transfer from similar learning tasks to compensate for the lack of many input/output examples.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
We compared the performance of four such techniques in a benchmark test over a range of datasets. For the test case, we used the Karel programming language, which introduces complex control flow including conditionals and loops in addition to a set of imperative actions. The neural architectures were provided with a fixed number of example input/output pairs (ranging from 1 to 100,000), and subsequently asked to derive the correct outputs from a set of new inputs (by implicitly learning to induce the corresponding Karel program). The figure below shows a couple of program induction tasks for the Karel dataset that our meta model could learn accurately from only 2 to 4 examples.
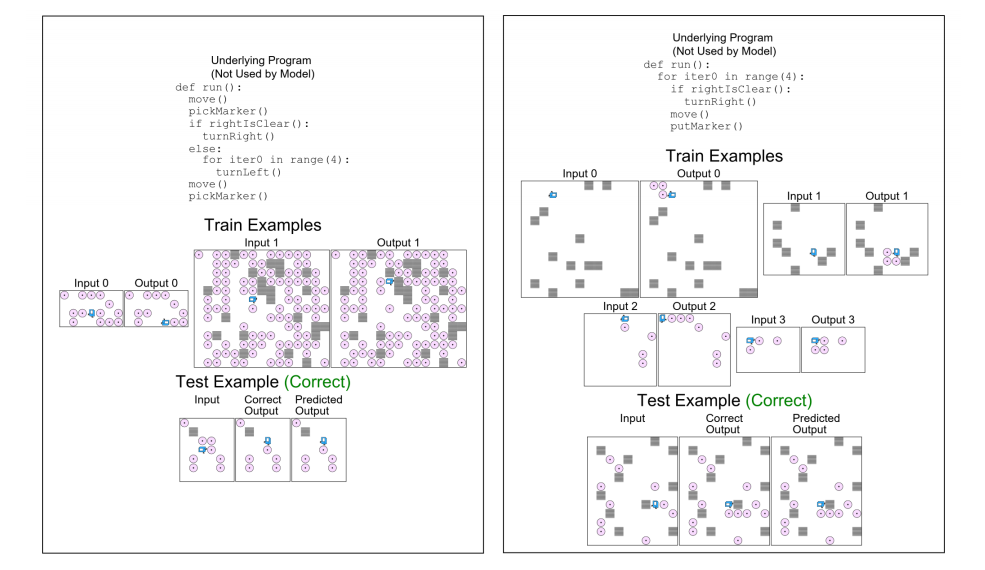
As detailed in our recently published paper, the results are quite promising: one of our meta induction techniques achieved an accuracy of nearly 40% with fewer than 10 examples (compared to 0% using the PLAIN example-driven technique alone).
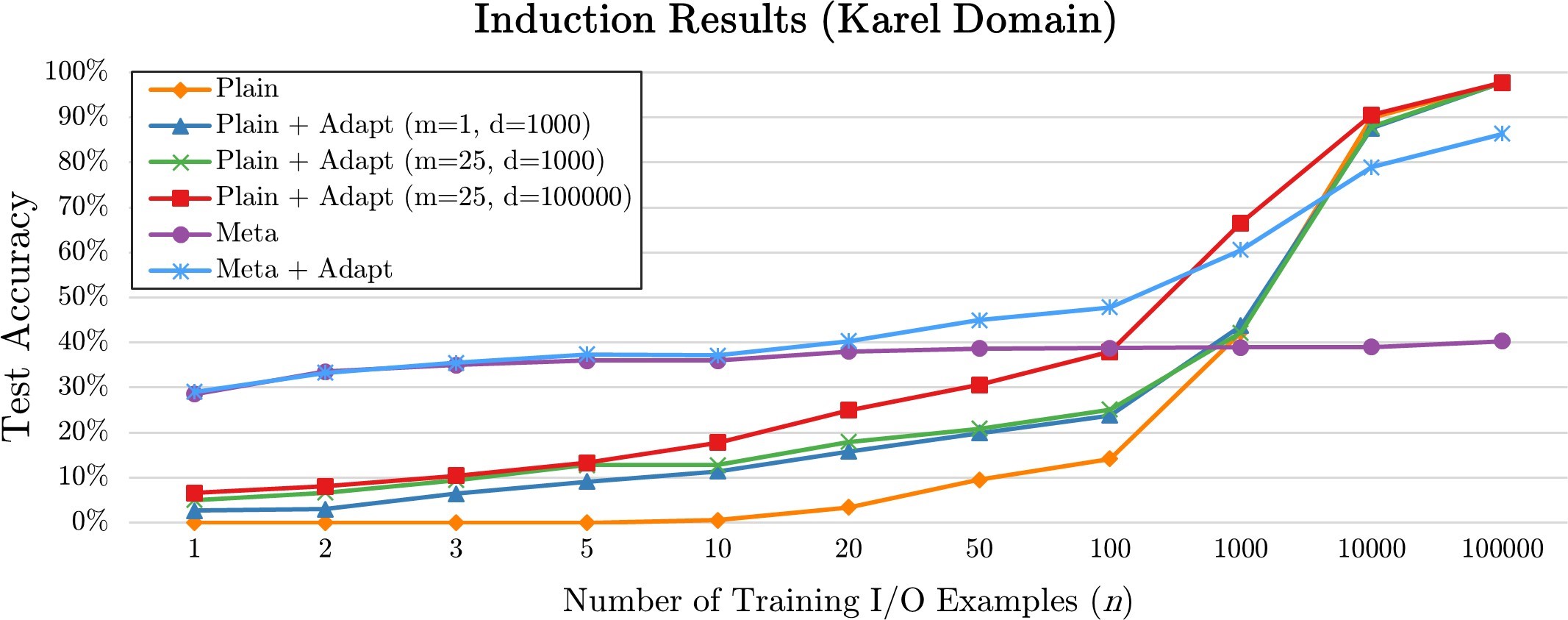
The accompanying graph illustrates how the performance of each of the four models varies with the sample size. As can be seen, the newer techniques performed significantly better when fewer examples were provided. While the results converge as the number of examples increase, we believe that our newer techniques still present some advantage in that they require less computing resources—and less processing time—than the traditional model.
The four techniques are summarized below.
- Plain Program Induction (PLAIN). Supervised learning is used to train a model which can perform induction on a single task, i.e., read in an input example for the task and predict the corresponding output. No cross-task knowledge sharing is performed.
- Portfolio-Adapted Program Induction (PLAIN+ADAPT). Simple transfer learning is used to adapt a model that has been trained on a related task for a new task.
- Meta Program Induction (META). A k-shot learning-style model is used to represent an exponential family of tasks, where the I/O examples corresponding to a task are directly conditioned on as input to the network. This model can generalize to new tasks without any additional training.
- Adapted Meta Program Induction (META+ADAPT). The META model is adapted to a specific new task using round-robin hold-one-out training on the task’s I/O examples.
Continued work in this area will continue to refine these models and develop new techniques that enable neural networks to perform complex programming tasks in possibly full-fledged programming languages—without the need for infinitely large number of examples.
Related: