
 Consider a person who applies for a loan with a financial company, but their application is rejected by a machine learning algorithm used to determine who receives a loan from the company. How would you explain the decision made by the algorithm to this person? One option is to provide them with a list of features that contributed to the algorithm’s decision, such as income and credit score. Many of the current explanation methods provide this information by either analyzing the algorithm’s properties or approximating it with a simpler, interpretable model.
Consider a person who applies for a loan with a financial company, but their application is rejected by a machine learning algorithm used to determine who receives a loan from the company. How would you explain the decision made by the algorithm to this person? One option is to provide them with a list of features that contributed to the algorithm’s decision, such as income and credit score. Many of the current explanation methods provide this information by either analyzing the algorithm’s properties or approximating it with a simpler, interpretable model.
However, these explanations do not help this person decide what to do next to increase their chances of getting the loan in the future. In particular, changing the most important features for prediction may not actually change the decision, and in some cases, important features may be impossible to change, such as age. A similar argument applies when algorithms are used to support decision-makers in scenarios such as screening job applicants, deciding health insurance, or disbursing government aid.
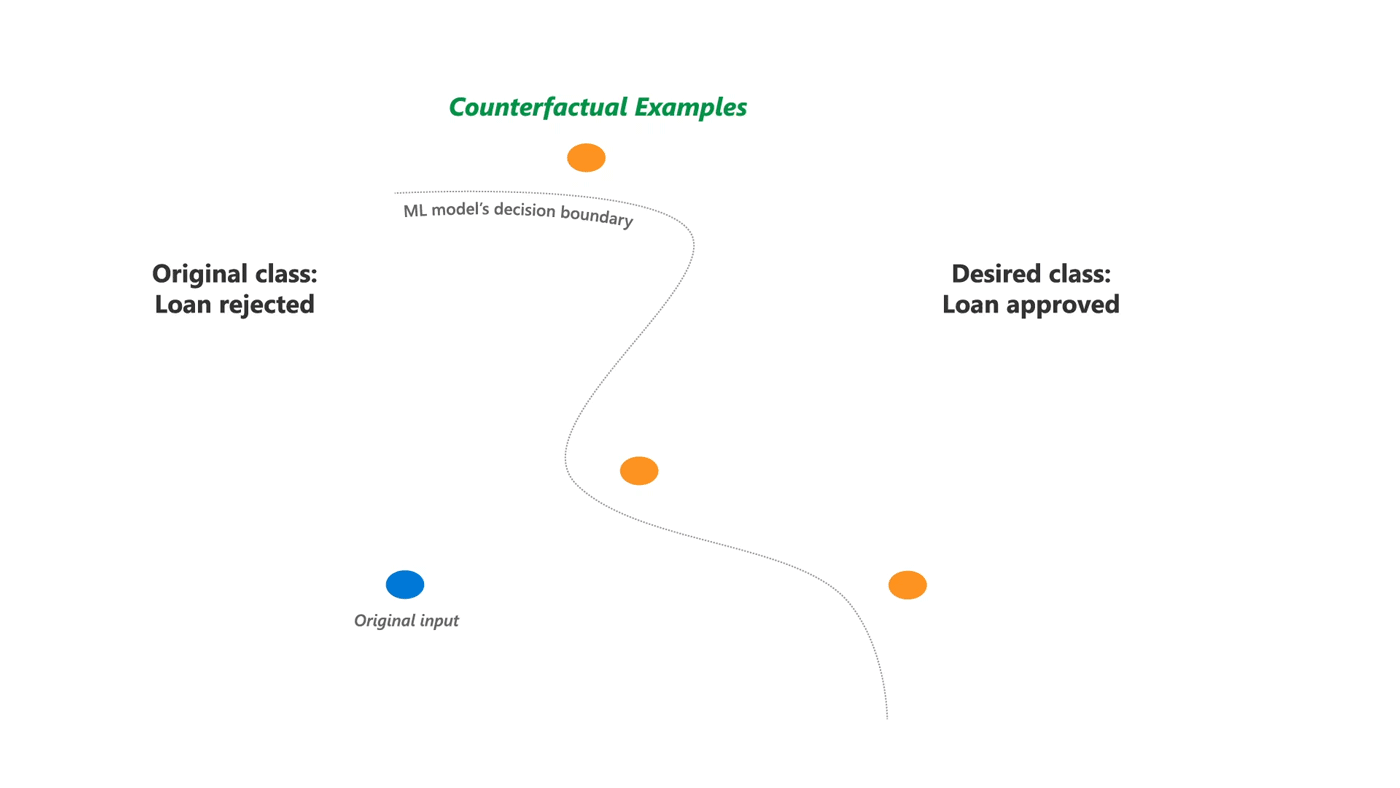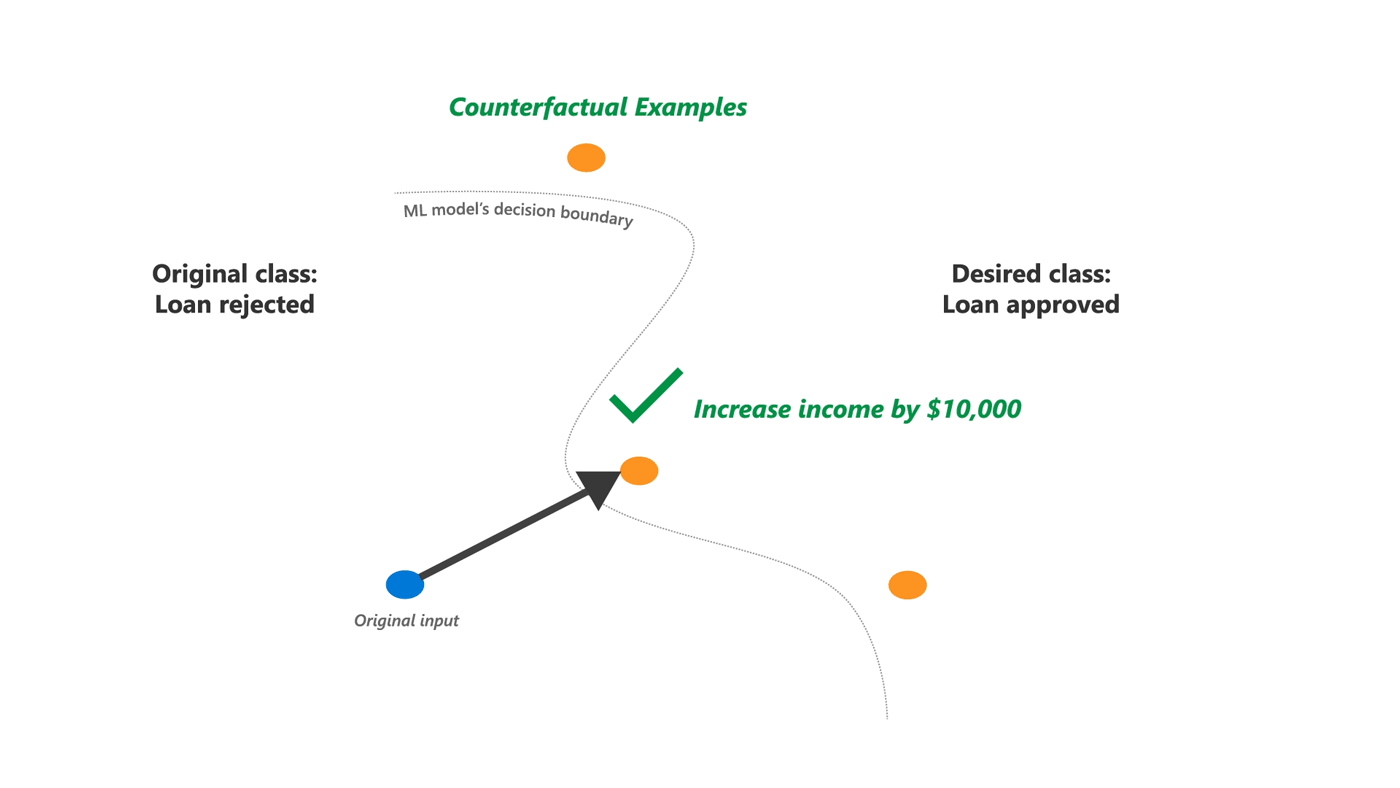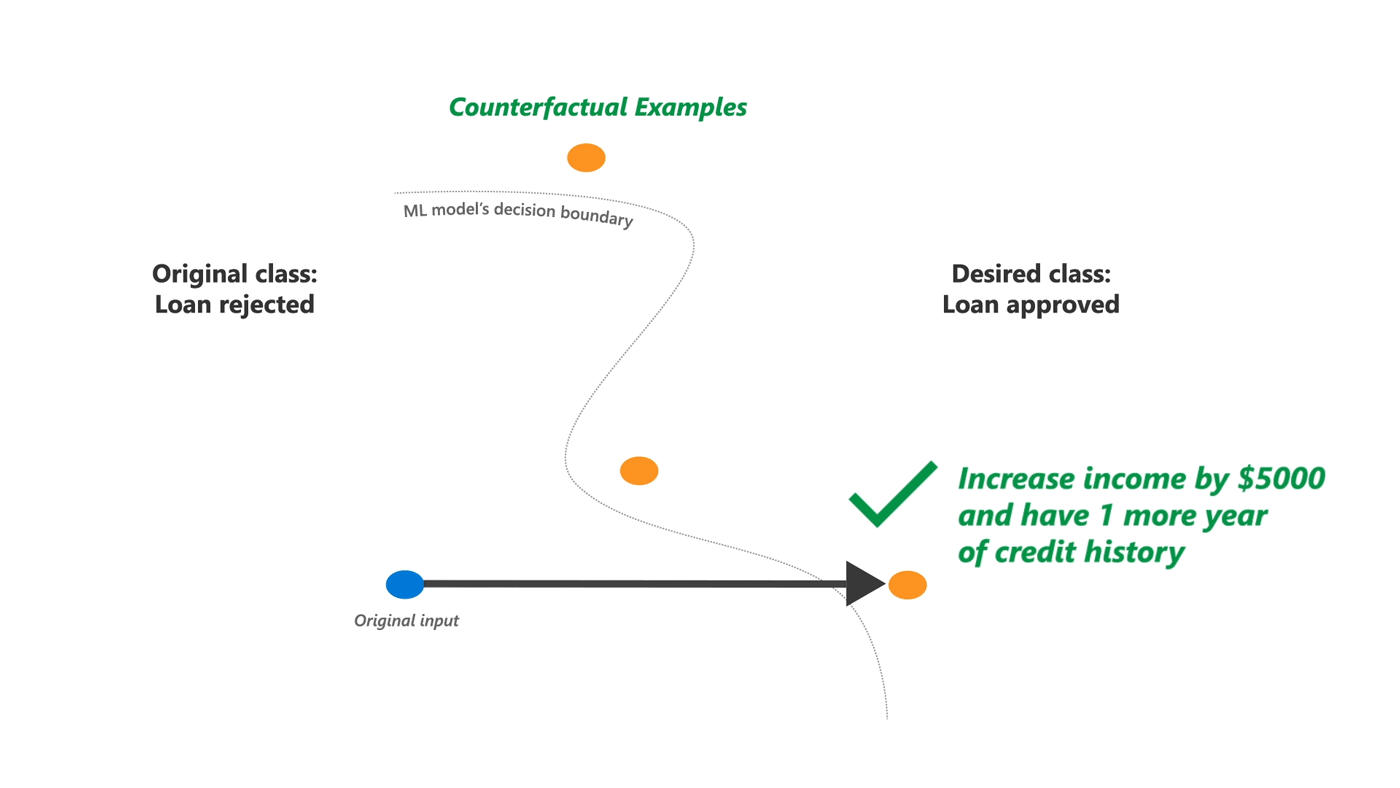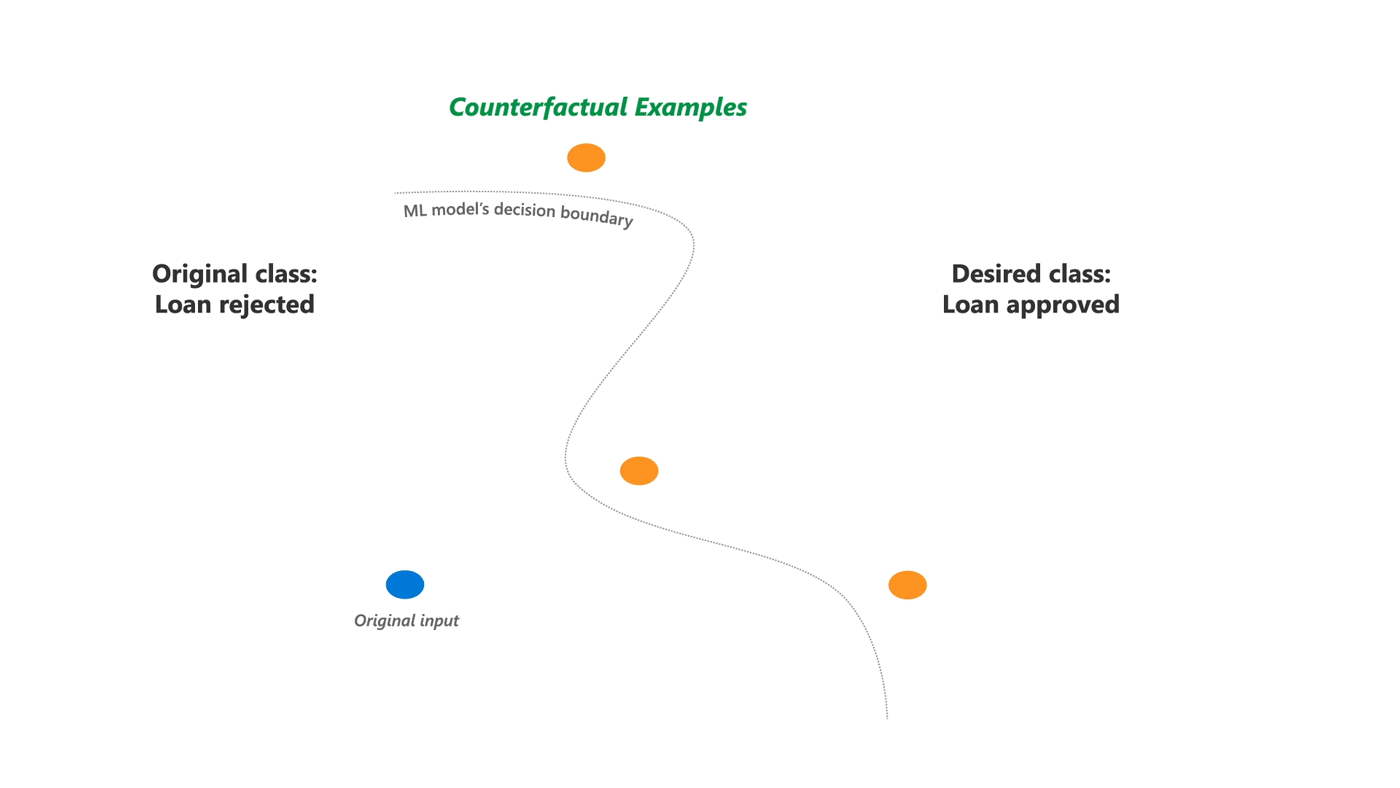
Therefore, it is equally important to show alternative feature inputs that would have received a favorable outcome from the algorithm. Such alternative examples are known as counterfactual explanations (opens in new tab) since they explain an algorithm by reasoning about a hypothetical input. In effect, they help a person answer the “what-if” question: What would have happened in an alternative counterfactual world where some of my features had been different?
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
To address this question, our team of researchers proposes a method for generating numerous diverse counterfactuals, which takes into account usefulness and relative ease. A paper detailing our research, entitled “Explaining Machine Learning Classifiers through Diverse Counterfactual Explanations,” will be presented at the ACM Conference on Fairness, Accountability, and Transparency (ACM FAT* 2020) (opens in new tab) in Barcelona, Spain. We have also released an open-source library, Diverse Counterfactual Explanations (DiCE) (opens in new tab), which implements our framework for generating counterfactual explanations. Although it is easy to generate a single counterfactual, the main challenge is to generate multiple useful ones, and that is the overlying goal of our method. This research was done in collaboration with Chenhao Tan from University of Colorado, Boulder (opens in new tab), and also includes Ramaravind Mothilal, who is currently an SCAI Center Fellow at Microsoft Research India.
The challenge: Generating multiple counterfactuals that are useful to users and system builders
Specifically, counterfactual explanation refers to a perturbation on the original feature input that results in the machine learning model providing a different decision. Such explanations are certainly useful to a person facing the decision, but they are also useful to system builders and evaluators in debugging the algorithm. In this sense, counterfactual examples are similar to adversarial examples, except that problematic examples are based not only on proximity to original input, but also on various domain-dependent restrictions that should not affect the outcome, such as sensitive attributes. Perhaps their biggest benefit is that they are always faithful to the original algorithm—following the counterfactual explanation will lead to the desired outcome, as long as the model stays the same.
Because of the large space of possible counterfactuals, it is unclear which examples will be actionable for a user or which ones will expose the various properties that a model builder may be interested in. For instance, a counterfactual explanation may suggest to change one’s house rent, but it does not disclose if there are other possible counterfactuals to the same effect or the relative ease with which different changes can be made.
Our solution: A method that creates many different counterfactuals at the same time
To find alternative counterfactuals that account for these additional factors, our method generates a diverse set of counterfactuals all at once. Much like web search engines, providing a set of diverse options allows a person to make an informed choice for the most actionable option. It also allows algorithm builders to test multiple ways of changing the outcome.
We do this by formulating a joint optimization problem that optimizes both diversity and proximity to the original input, in addition to ensuring that the model provides the desired outcome for the counterfactual example. In addition, we support adding different kinds of user-specific requirements. By adding constraints to the optimization problem, one can specify which features are varied, by how much, and the relative difficulty of varying each feature. Figure 1 is an example of our method applied to explain a machine learning model that predicts income for a person.

Figure 1: Counterfactual explanations for a person from the Adult Income Dataset (opens in new tab), based on a given machine learning model that classifies their income. DiCE constructs an optimization function to generate k=4 counterfactuals that are both proximal to the original input and diverse. Dashes in a counterfactual example correspond to no change in those features.
We find that our proposed method outperforms current methods for generating a diverse set of counterfactuals. We also discover an impressive property of counterfactuals: just a handful of counterfactual explanations are able to locally approximate the machine learning algorithm using a simple k-nearest neighbors classification model. That is, counterfactual explanations can approximate the local decision boundary with comparable accuracy to methods like LIME (opens in new tab) that are specifically optimized for the objective.
That said, what qualifies as a useful counterfactual varies by application domain, and many challenges remain to deploy counterfactual examples for real-world systems. One of the key challenges is handling causal relationships between features while modifying them. Features do not exist in a vacuum; they are generated from a data-generating process that constrains their modification. Therefore, while a counterfactual explanation may change features independently, the suggested change can sometimes be impossible (for instance, getting a higher degree without aging). We are currently developing methods that can generate counterfactual examples that satisfy causal constraints and presented our work (opens in new tab) at the NeurIPS 2019 workshop on causal machine learning (opens in new tab). In another paper (opens in new tab) that is presented at the ACM FAT* 2020 conference, my colleague Solon Barocas raises several other important issues on deciding the explanations to be shown and the potential consequences of revealing too much about the algorithm.
To accelerate research on these questions, we have released an open-source library called Diverse Counterfactual Explanations (DiCE) (opens in new tab) that implements our methods and provides a framework for testing other counterfactual explanation methods. We look forward to adding more methods to the library and integrating with the broader InterpretML framework (opens in new tab) for explaining machine learning models. Given the multiple objectives of diversity, proximity, and causal feasibility, we hope that the library enables development and benchmarking of different counterfactual explanation methods and provides an easy way for adapting counterfactual generation to different use cases for a model builder, evaluator, or end-user. To help researchers accomplish these goals, our team will be publishing regular updates to the GitHub page, including additions to the library and information about new methods.