
Deep Neural Networks (DNNs) have facilitated tremendous progress across a range of applications, including image classification, translation, language modeling, and video captioning. DNN training is extremely time-consuming, needing efficient multi-accelerator parallelization.
In “PipeDream: Generalized Pipeline Parallelism for DNN Training,” published at the 27th ACM Symposium on Operating Systems Principles (SOSP 2019) (opens in new tab), Microsoft researchers in the Systems Research Group, along with students and colleagues from Carnegie Mellon University and Stanford University, have proposed a new way to parallelize DNN training. The system, called PipeDream, achieves up to 5.3 times faster training time than traditional approaches across a range of models as shown in our paper.
DNN training happens in iterations of forward and backward pass computations. In each iteration, the training loop processes a minibatch of input data and performs an update to the model parameters. The most common approach to parallelize DNN training is a method called data parallelism (see Figure 1 below), which partitions input data across workers (accelerators).
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the first four episodes on demand.
Unfortunately, despite advances in performance optimizations to speed up data parallelism, it can suffer from high communication costs at scale when training on cloud infrastructure. Also, rapid increases in GPU compute speed over time will further shift the bottleneck of training towards communication for all models.
A less common form of parallel training, model parallelism (see Figure 1 below), partitions operators across workers and has traditionally been used to enable the training of very large DNN models. Model parallelism has challenges as well: it uses hardware resources inefficiently and places an undue burden on programmers to determine how to split their specific model given a hardware deployment.
PipeDream, a system developed as part of Microsoft Research’s Project Fiddle, introduces pipeline parallelism, a new way to parallelize DNN training by combining traditional intra-batch parallelism (model and data parallelism) with inter-batch parallelism (pipelining).
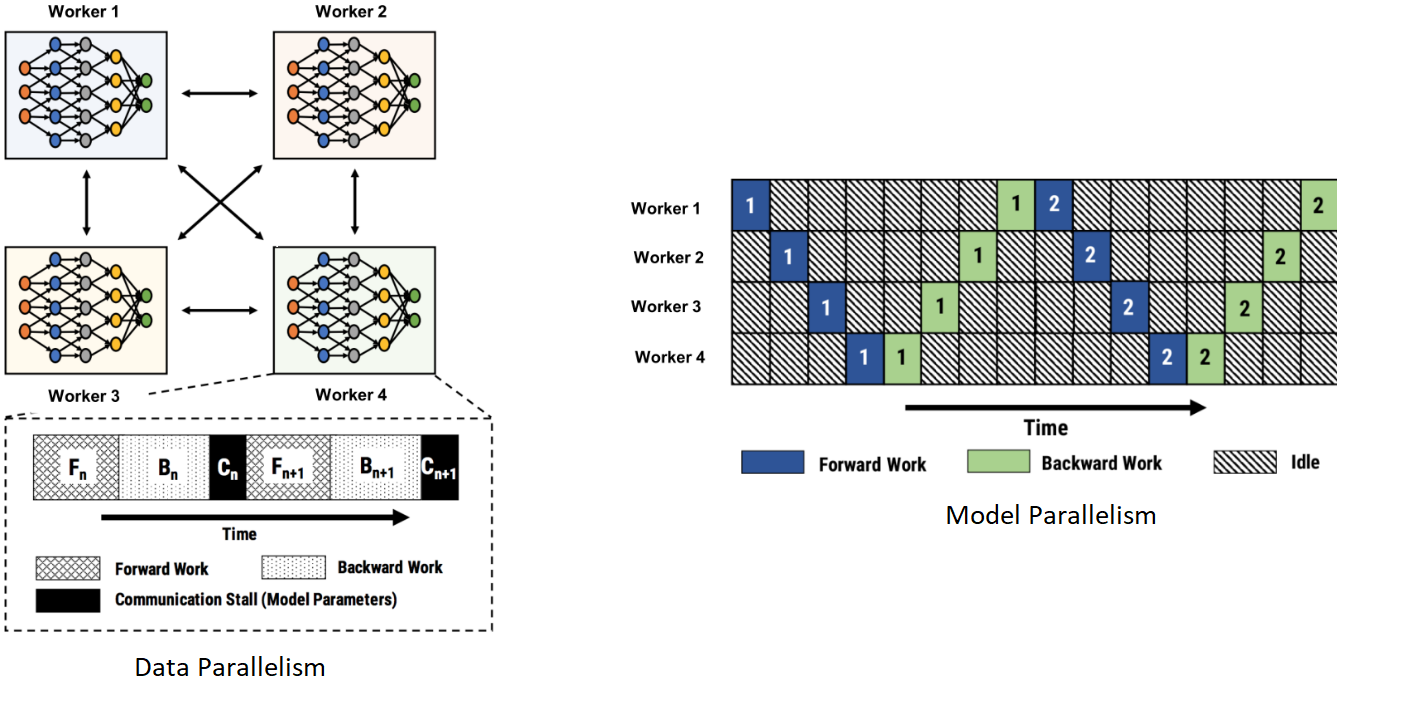
Figure 1: Traditional intra-batch approaches for parallel training, such as data parallelism and model parallelism, suffer from poor hardware efficiency. In the image on the left, individual workers in data parallelism incur communication stalls for gradient exchange. In the image on the right, with model parallelism, there is only one active minibatch that is being processed across workers, severely limiting hardware utilization.
Using pipeline-parallel training to overcome limitations of intra-batch parallelism
PipeDream revisits using model parallelism for performance, as opposed to the traditional motivation of working set size limitations for training large models. It uses pipelining of multiple inputs to overcome the hardware efficiency limitations of model-parallel training. A general pipeline parallel setup involves layers split across stages, with each stage potentially replicated and running data parallel. Multiple batches are injected into the pipeline to keep it full in steady state. Pipeline-parallel training, in most cases, communicates far lesser data than data-parallel training as it needs to communicate only the activations and gradients at the boundary of two stages. In steady state all workers are busy doing work with no pipeline stalls as in model-parallel training (as shown in the figure below).
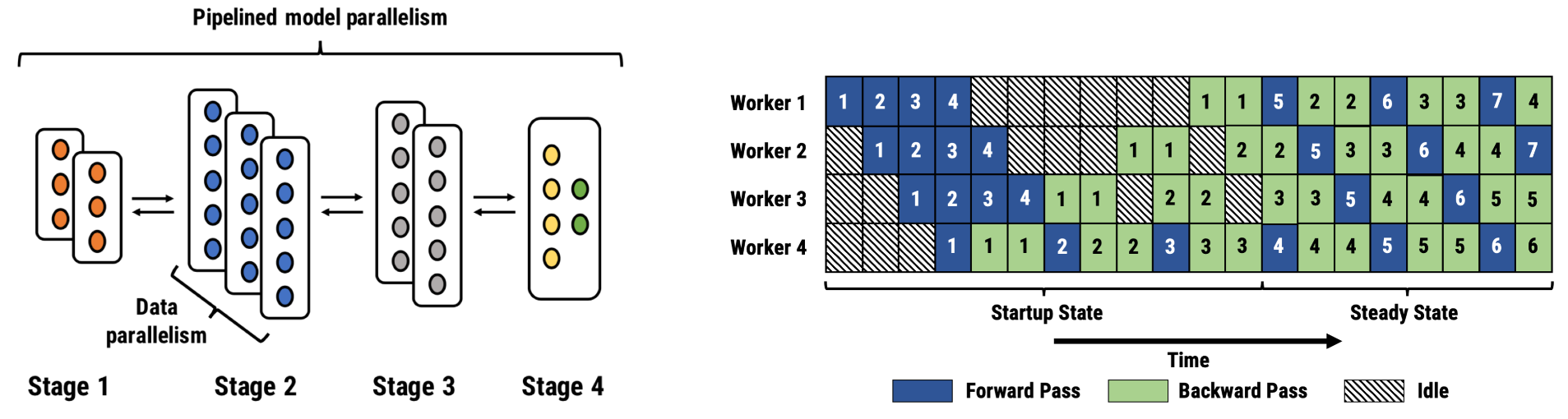
Figure 2: In the figure on the left, we show an example pipeline-parallel assignment with eight GPUs split across four stages. Only activations and gradients at stage boundaries are communicated. Stages 1, 2, and 3 have replicated stages to ensure a load-balanced pipeline. The figure on the right shows another pipeline with 4 workers, showing start-up and steady states. In this example, the backward pass takes twice as long as the forward pass.
Overcoming the challenges of pipeline-parallel training in PipeDream
To achieve the potential benefits of pipeline-parallel training, PipeDream has to overcome three main challenges:
- First, PipeDream has to schedule work in a bidirectional pipeline across different inputs.
- Next, PipeDream needs to manage weight versions for the backward pass to compute numerically correct gradients and to use the same version in the backwards pass as the one used during the forward pass.
- Last, PipeDream must require that all stages in the pipeline take roughly the same amount of time in order to operate the pipeline at peak throughput (since the throughput of a pipeline is bottlenecked by the slowest stage).
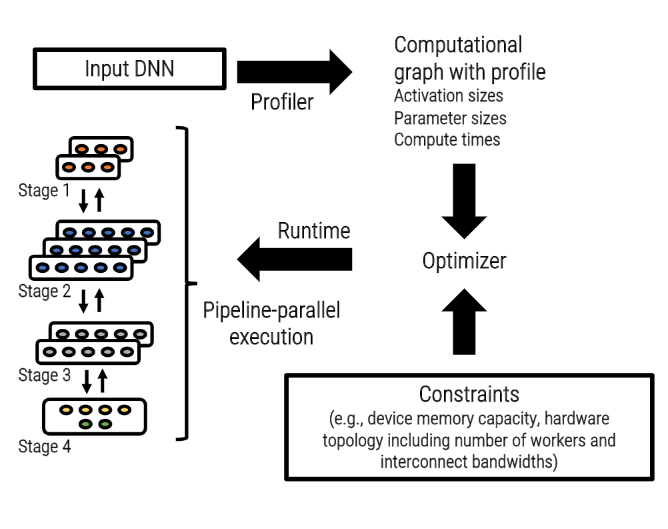
Figure 3: An overview of PipeDream’s workflow
Figure 3 shows the high-level overview of PipeDream’s workflow. Given a model and deployment, PipeDream automatically determines how to partition the operators of the DNN based on a short profiling run performed on a single GPU, balancing computational load among the different stages while minimizing communication for the target platform. PipeDream effectively load balances even in the presence of model diversity (computation and communication) and platform diversity (interconnect topologies and hierarchical bandwidths).
As DNNs do not always divide evenly among available workers, PipeDream may decide to use data parallelism for some stages—multiple workers can be assigned to a given stage, processing different minibatches in parallel. PipeDream uses a scheduling algorithm called 1F1B to keep hardware fully utilized while achieving semantics similar to data parallelism.
In 1F1B’s steady state, each worker strictly alternates between forward and backward passes for its stage, ensuring high resource utilization (negligible pipeline stalls, no pipeline flushes) even in the common case where the backward pass takes longer than the forward pass. An example of this is shown above in Figure 2. 1F1B also uses different versions of model weights to maintain statistical efficiency comparable to data parallelism. Finally, PipeDream extends 1F1B to incorporate round-robin scheduling across data-parallel stages, ensuring that gradients in a backward pass are routed to the corresponding worker from the forward pass.
PipeDream has been built to use PyTorch (an earlier version of PipeDream (opens in new tab) uses Caffe). Our evaluation, encompassing many combinations of DNN models, datasets, and hardware configurations, confirms the training time benefits of PipeDream’s pipeline parallelism. Compared to data-parallel training, PipeDream reaches a high target accuracy on multi-GPU machines up to 5.3 times faster for image classification tasks, up to 3.1 times faster for machine translation tasks, 4.3 times faster for language modeling tasks, and 3 times faster for video captioning models. PipeDream is also 2.6 to 15 times faster than model parallelism and up to 1.9 times faster than hybrid parallelism.
If you are interested in exploring PipeDream in more detail, the source code can be found on GitHub (opens in new tab).
PipeDream will be presented at the first talk during SOSP 2019 in Huntsville, Ontario, Canada, beginning at 9:00am (EDT) on Monday, October 28th. Join us to hear more about our research.



