

From left to right: Akshay Krishnamurthy, Nan Jiang, and Alekh Agarwal
Reinforcement learning, a machine learning paradigm for sequential decision making, has stormed into the limelight, receiving tremendous attention from both researchers and practitioners. When combined with deep learning, reinforcement learning (RL) has produced impressive empirical results, but the successes to date are limited to simulation scenarios in which data is cheap, primarily because modern “deep RL” algorithms are extremely data hungry. In “Provably Efficient RL with Rich Observations via Latent State Decoding”, Microsoft Research PhD intern Simon S. Du (opens in new tab) of Carnegie Mellon University, Nan Jiang (opens in new tab) of UIUC, Alekh Agarwal (opens in new tab) of Microsoft Research AI, along with myself (opens in new tab), Miroslav Dudík, and John Langford of Microsoft Research New York City, develop a provably data-efficient reinforcement learning algorithm, making important progress towards practical RL for real-world applications. The paper will be presented at the Thirty-sixth International Conference on Machine Learning (opens in new tab) (ICML 2019) in June by Simon Du.
Reinforcement learning involves an agent interacting with an environment through trial and error. The agent repeatedly uses environment cues, or observations, to perform actions, and these actions alter the state of the environment. The goal is for the agent to accomplish some pre-specified task—for example to have a robot navigate to its charging station. In modern RL scenarios, the observations are typically rich and noisy sensor readings like images from a front-view camera on the robot. However, the state of the environment is often much simpler; it might just be the location of the robot.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
The key to data-efficient RL is strategic exploration—the agent must learn about the environment through interaction, which often requires performing specific action sequences to reach particular environment states. Classical algorithms address the exploration question when the state is directly observed (the “tabular” setting), by counting the number of times each state has been visited and driving the agent to minimally visited states. However, these methods fail with rich observations because the state is not directly observed and must be inferred. Indeed, prior to our ICML 2017 paper, there were no provably data-efficient methods for handling rich observations.
Unfortunately, our previous method was not computationally tractable, but the new paper resolves this shortcoming. The new algorithm is a computationally and data-efficient method for strategic exploration with rich observations. It explores by first extracting underlying states from the observations, a form of dimensionality reduction. Once we have a small learned state space, classical RL algorithms are tractable, and therefore, our key contribution is a new technique for learning state representations.
We learn representations by leveraging supervised learning. Specifically, our supervised learner uses the observation to predict the “backward transition probability”—a distribution over previous actions and the state representation of the previous observation. We then construct the state representation from the predictions of the supervised learner. The intuition is that observations arising from semantically similar behaviors will induce the same predictions, so they will be collapsed into a single underlying state. We call the final algorithm “PCID,” which stands for “Policy Cover by Inductive Decoding.”
We obtained a data-efficiency guarantee: the algorithm learns a high-quality state representation and the amount of experience required is independent of the size of the observation space, scaling only with the number of underlying states. This allowed us to scale to rich observation settings and it represents an exponential improvement over earlier approaches. Furthermore, via the reduction to supervised learning, the algorithm is computationally tractable.
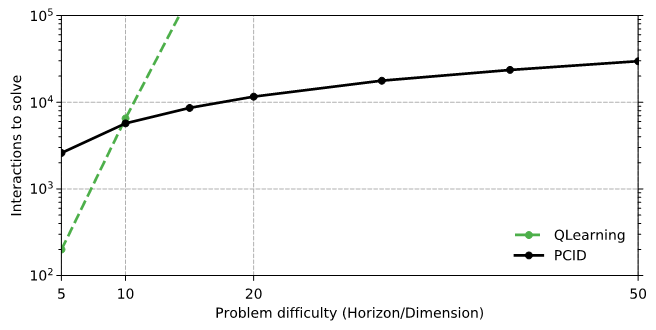
Figure 1. Empirical results comparing PCID with Q-Learning in a simple synthetic reinforcement learning environment. Q-Learning has the unfair advantage of directly accessing the latent state, yet, PCID is exponentially more sample efficient.
We also benchmark PCID on synthetic environments, comparing with a simple but popular baseline: Q-learning with epsilon-greedy exploration. Our environments have a small underlying state space but rich high-dimensional observations. While we run PCID on the observations, we give Q-learning an unfair advantage by running it directly on the underlying state space. Despite being severely handicapped in this manner, PCID is exponentially more efficient than Q-learning, scaling gracefully with problem difficulty. The paper includes several other experiments as well.
“Provably efficient RL with Rich Observations via Latent State Decoding” is the latest in a series of works by Microsoft researchers and colleagues, developing a new statistical theory for modern reinforcement learning.
We look forward to seeing you at ICML 2019 in Long Beach, California!