
Language Representation Learning maps symbolic natural language texts (for example, words, phrases and sentences) to semantic vectors. Robust and universal language representations are crucial to achieving state-of-the-art results on many Natural Language Processing (NLP) tasks.
Ensemble learning is one of the most effective approaches for improving model generalization and has been used to achieve new state-of-the-art results in a wide range of natural language understanding (NLU) tasks. However, ensemble learning typically consists of tens or even hundreds of different deep neural network (DNN) models and is prohibitively expensive to deploy due to the computational cost of runtime inference.

Figure 1: Architecture of the MT-DNN student model.
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the latest episodes on demand.
In “Improving Multi-Task Deep Neural Networks via Knowledge Distillation for Natural Language Understanding”, researchers Xiaodong Liu and Jianfeng Gao of Microsoft Research and Pengcheng He and Weizhu Chen of Microsoft Dynamics 365 AI compressed multiple ensembled models into a single Multi-Task Deep Neural Network (MT-DNN) via knowledge distillation for learning robust and universal text representations across multiple NLU tasks. The ensemble model was utilized, in an offline manner, to produce a set of soft targets for each task in the training dataset. These generated soft targets provide more information per training sample than the hard targets and less variance in the gradient between training samples. For example, the sentiment of the sentence “I really enjoyed the conversation with Tom” has a small chance of being classified as negative. But the sentence “Tom and I had an interesting conversation” can be either positive or negative, depending on its context, if available, leading to a high entropy of the soft targets assigned by the teacher. Then, a single MT-DNN (student) was trained via multi-task learning with the help of the teachers by using both the soft targets and correct targets across different tasks. Empirical experiments show that the distilled MT-DNN outperforms the original MT-DNN and obtained a new state-of-the-art result on the General Language Understanding Evaluation (GLUE) benchmark.
The MT-DNN student model
The student model is a MT-DNN model proposed by Microsoft in 2019 that incorporates a pre-trained bidirectional transformer language model, known as BERT, developed by Google AI. Figure 1 illustrates the architecture of the student model. The lower layers are shared across all tasks while the top layers are task-specific. The input X (either a sentence or a set of sentences) is first represented as a sequence of embedding vectors, one for each word, in l1. Then the Transformer encoder captures the contextual information for each word and generates the shared contextual embedding vectors in l2. Finally, for each task, additional task-specific layers generate task-specific representations, followed by operations necessary for classification, similarity scoring, or relevance ranking. The shared layers of MT-DNN are initialized by using BERT, then trained jointly via multi-task learning (MTL).
Multi-task knowledge distillation
The process of knowledge distillation for MTL is illustrated in Figure 2. A set of tasks where there is task-specific labeled training data is picked. Then, for each task, an ensemble of different neural nets (teacher) is trained. The teacher is used to generate a set of soft targets for each task-specific training sample. Given the soft targets of the training datasets across multiple tasks, a single MT-DNN (student) is trained using multi-task learning, except that if task $t$ has a teacher, the task-specific loss is the average of two objective functions—one for the correct targets and the other for the soft targets assigned by the teacher.
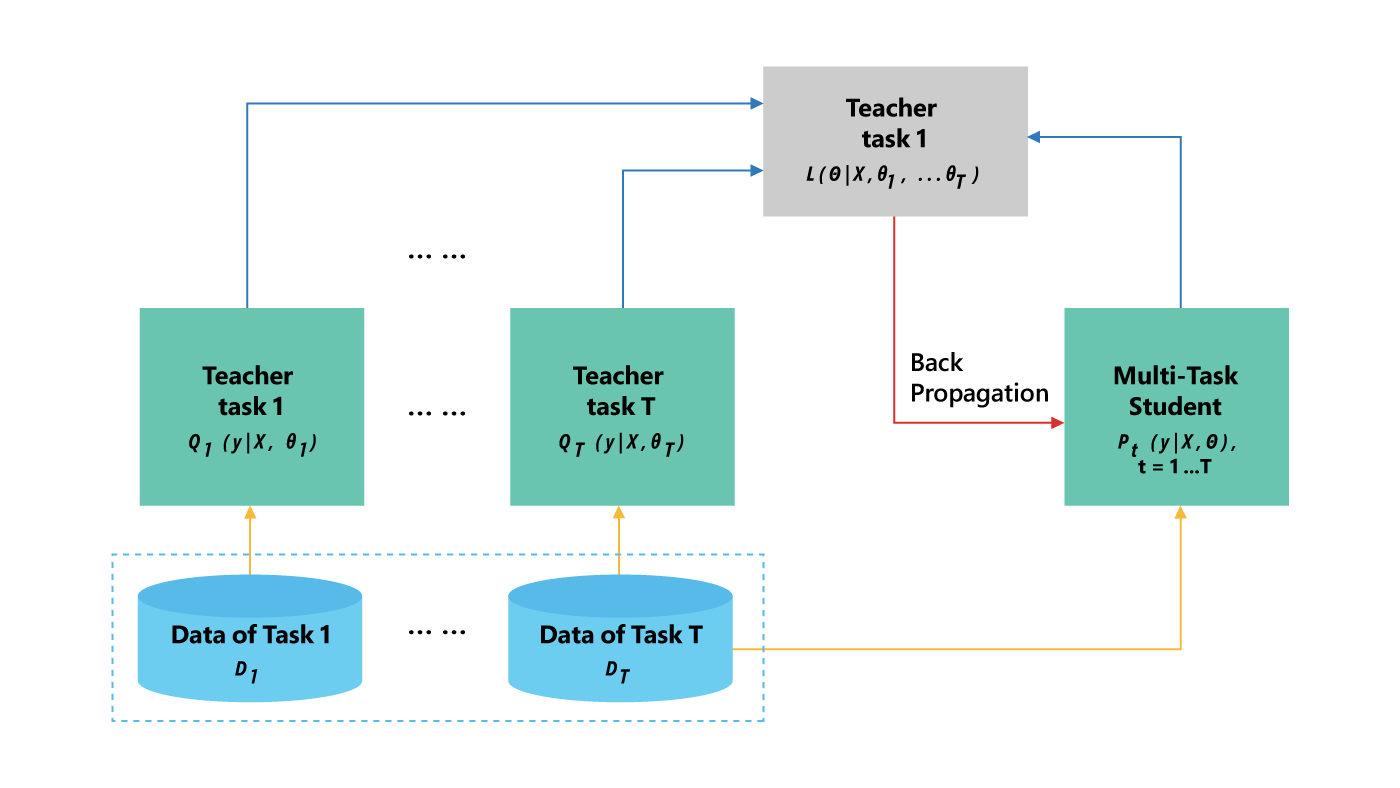
Figure 2: Knowledge distillation for multi-task learning
Results
The authors compared the distilled MT-DNN with BERT and MT-DNN. As shown in Figure 2, the MT-DNN outperforms BERT by a substantial margin, and the distilled MT-DNN further realizes a significant improvement over MT-DNN in terms of overall score on GLUE. On the GLUE diagnostics data, which is a manually-curated test set for the analysis of system performance, similar observations are found: both MT-DNN and distilled MT-DNN outperform BERT. All these demonstrate that language representation learned via distilled MT-DNN is more robust and universal than BERT/MT-DNN. Detailed results can be found at the GLUE leaderboard (opens in new tab).
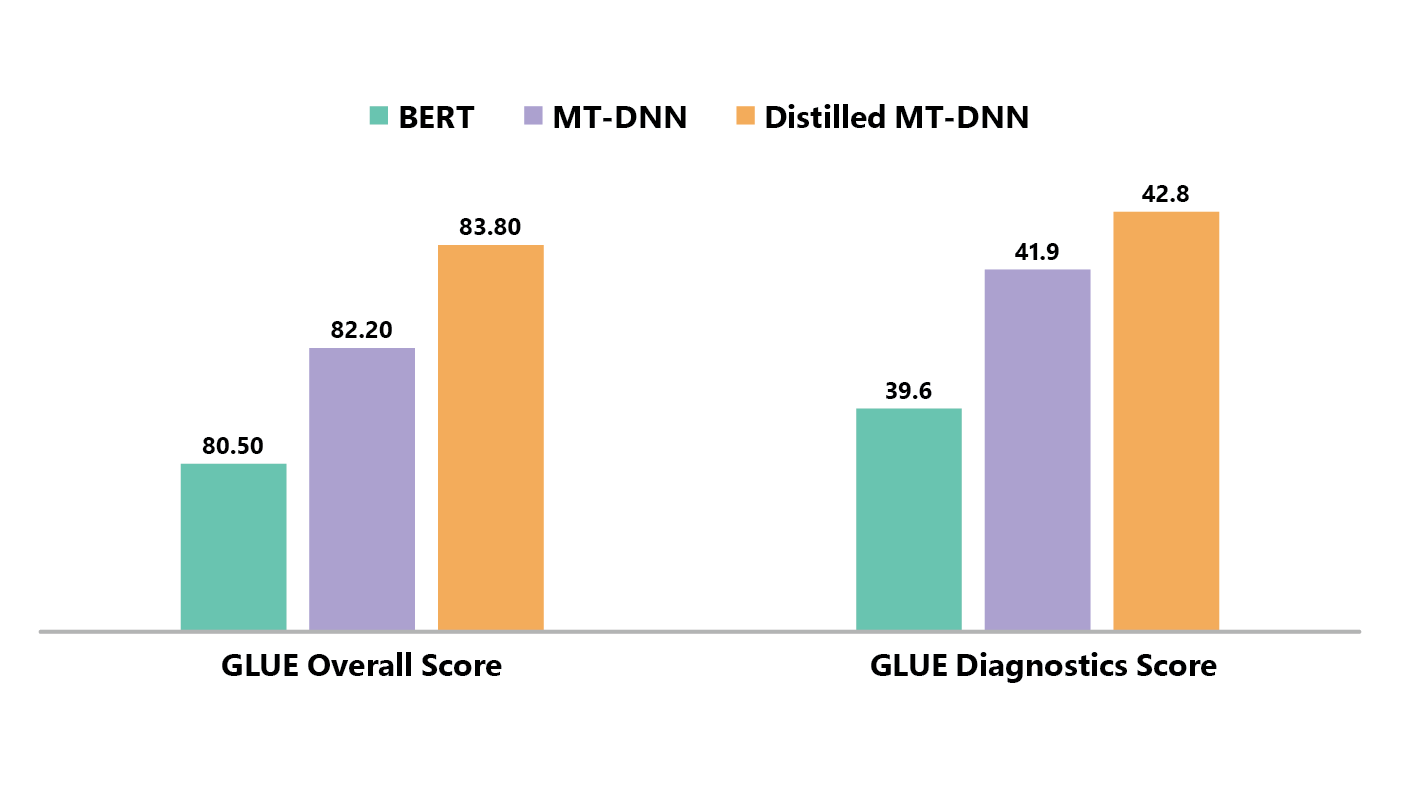
Figure 3: GLUE test results
Release news
Microsoft plans to release the distilled MT-DNN package in June 2019 to the public at https://github.com/namisan/mt-dnn. The release package contains the pretrained models, the source code and the Readme that describes step by step how to reproduce the results reported in the paper. We welcome your comments and feedback and look forward to future developments!
Acknowledgements
This research was conducted by Xiaodong Liu, Pengcheng He, Weizhu Chen and Jianfeng Gao. Additional thanks go to Asli Celikyilmaz, Xuedong Huang, Moontae Lee, Chunyuan Li, Xiujun Li, and Michael Patterson for their helpful discussions and comments.