

Mixture of experts (MoE) is a deep learning model architecture in which computational cost is sublinear to the number of parameters, making scaling easier. Nowadays, MoE is the only approach demonstrated to scale deep learning models to trillion-plus parameters, paving the way for models capable of learning even more information and powering computer vision, speech recognition, natural language processing, and machine translation systems, among others, that can help people and organizations in new ways.
Today, we’re proud to announce Tutel, a high-performance MoE library (opens in new tab) to facilitate the development of large-scale DNN models; Tutel is highly optimized for the new Azure NDm A100 v4 series, now generally available (opens in new tab). With Tutel’s diverse and flexible MoE algorithmic support, developers across AI domains can execute MoE more easily and efficiently. For a single MoE layer, Tutel achieves an 8.49x speedup on an NDm A100 v4 node with 8 GPUs and a 2.75x speedup on 64 NDm A100 v4 nodes with 512 A100 GPUs (all experiments in this blog are tested on Azure NDm A100 v4 nodes with 8 x 80 GB NVIDIA A100 and an 8 x 200 gigabits per second InfiniBand network), respectively, compared with state-of-the-art MoE implementations such as that in Meta’s Facebook AI Research Sequence-to-Sequence Toolkit (fairseq) (opens in new tab) in PyTorch. For end-to-end performance, Tutel—benefiting from an optimization for all-to-all communication—achieves a more than 40 percent speedup with 64 NDm A100 v4 nodes for Meta’s (Facebook is now Meta) 1.1 trillion–parameter MoE language model. Tutel provides great compatibility with rich features to ensure the great performance when working on the Azure NDm A100 v4 cluster. Tutel is open source and has been integrated into fairseq.
Tutel MoE optimizations
Complementary to other high-level MoE solutions like fairseq and FastMoE, Tutel mainly focuses on the optimizations of MoE-specific computation and the all-to-all communication, as well as other diverse and flexible algorithmic MoE supports. Tutel has a concise interface, making it easy to integrate into other MoE solutions. Alternatively, developers can use the Tutel interface to incorporate standalone MoE layers into their own DNN models from scratch and benefit from the highly optimized state-of-the-art MoE features directly.
MoE-specific optimization for computation
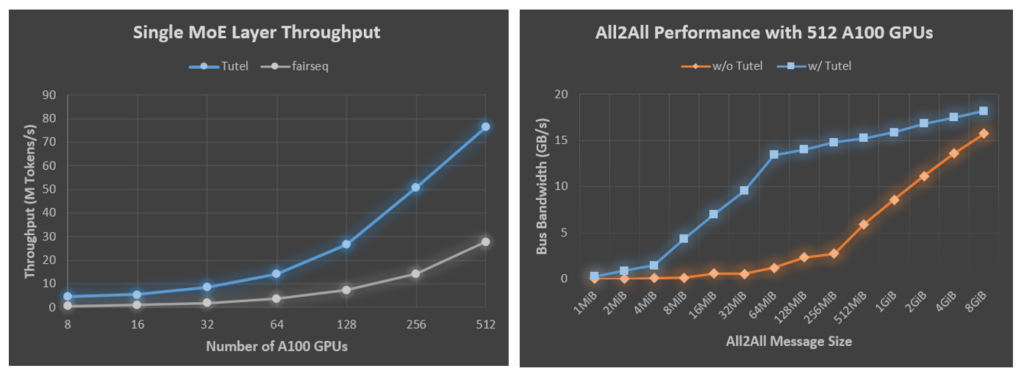
Because of the lack of efficient implementations, MoE-based DNN models rely on a naive combination of multiple off-the-shelf DNN operators provided by deep learning frameworks such as PyTorch and TensorFlow to compose the MoE computation. Such a practice incurs significant performance overheads thanks to redundant computation. Tutel designs and implements multiple highly optimized GPU kernels to provide operators for MoE-specific calculation. For example, Tutel reduces the time complexity of dispatching “gating output” from O(N^3) to O(N^2), which significantly improves the data dispatching efficiency. Tutel also implements a fast cumsum-minus-one operator, achieving a 24x speedup compared with the fairseq implementation. Tutel also leverages NVRTC (opens in new tab), a runtime compilation library for CUDA C++, to further optimize the customized MoE kernel just-in-time. Figure 1 shows the comparison results of Tutel with fairseq on the Azure NDm A100 v4 platform, where—as mentioned above—a single MoE layer with Tutel achieves an 8.49x speedup on 8 A100 GPUs and a 2.75x speedup on 512 A100 GPUs.
Underlying all-to-all communication optimization on Azure NDm A100 v4 clusters
Tutel also optimizes the all-to-all collective communication for large-scale MoE training on Azure NDm A100 v4 clusters, including CPU-GPU binding and adaptive routing (AR) tuning. A proper CPU-GPU binding on a multi-non-uniform memory access (NUMA) system, especially on the NDm A100 v4 nodes, is very critical for all-to-all performance. Unfortunately, existing machine learning frameworks have not provided an efficient all-to-all communication library, resulting in performance regression for large-scale distributed training. Tutel optimizes the binding automatically and provides an elegant interface for user fine-tuning. Furthermore, Tutel leverages multipath technology, namely AR, on NDm A100 v4 clusters. For the all-to-all communication in MoE, the total data traffic size of the communication for each GPU doesn’t change, but the data size between each GPU pair becomes smaller with the increasing number of GPUs. Smaller data size incurs a larger overhead in the all-to-all communication, leading to poorer MoE training performance. By taking advantage of AR technology available on NDm A100 v4 clusters, Tutel improves communication efficiency for groups of small messages and provides high-performance all-to-all communication on NDm A100 v4 systems. Benefiting from CPU-GPU binding and AR tuning, Tutel achieves a 2.56x to 5.93x all-to-all speedup with 512 A100 GPUs for message sizes hundreds of MiB large, which are typically used in MoE training, as illustrated in Figure 2.
Diverse and flexible MoE algorithms support
Tutel provides diverse and flexible support for state-of-the-art MoE algorithms, including support for:
- the arbitrary K setting for the Top-K gating algorithm (most implementations only support Top-1 and Top-2).
- different exploration strategies (opens in new tab), including batch-prioritized routing, input dropout, and input jitter
- different levels of precisions, including half precision (FP16), full precision (FP32), and mixed precision (we’ll support BF16 in our next release)
- different types of devices, including both NVIDIA CUDA and AMD ROCm devices
Tutel will be actively integrating various emerging MoE algorithms from the open-source community.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
Integrating Tutel with Meta’s MoE language model
Meta made its MoE language model open source (opens in new tab) and uses fairseq for its MoE implementation. We worked with Meta to integrate Tutel into the fairseq toolkit (opens in new tab). Meta has been using Tutel to train its large language model, which has an attention-based neural architecture similar to GPT-3, on Azure NDm A100 v4. We use Meta’s language model to evaluate the end-to-end performance of Tutel. The model has 32 attention layers, each with 32 x 128-dimension heads. Every two layers contains one MoE layer, and each GPU has one expert. Table 1 summarizes the detailed parameter setting of the model, and Figure 3 shows the 40 percent speedup Tutel achieves. With the increasing number of GPUs, the gain from Tutel is from 131 percent with 8 A100 GPUs to 40 percent with 512 A100 GPUs because the all-to-all communication becomes the bottleneck. We’ll do further optimization on the next version.
| Configuration | Setting | Configuration | Setting |
| code branch | moe-benchmark (opens in new tab) | Git commit ID | 1ef1612 |
| decorder-layers | 32 | Arch | transformer_lm_gpt |
| decoder-attention-heads | 32 | Criterion | moe_cross_entropy |
| decoder-embed-dim | 4096 | moe-freq | 2 |
| decorder-ffn-embed-dim | 16384 | moe-expert-count | 512 |
| tokens-per-sample | 1024 | moe-gating-use-fp32 | True |
| Batch-size | 24 | Optimizer | Adam |
| vocabulary size | 51200 | fp16-adam-stats | True |
The promise of MoE
MoE is a promising technology. It enables holistic training based on techniques from many areas, such as systematic routing and network balancing with massive nodes, and can even benefit from GPU-based acceleration. We demonstrate an efficient MoE implementation, Tutel, that resulted in significant gain over the fairseq framework. Tutel has been integrated into the DeepSpeed framework, as well, and we believe that Tutel and related integrations will benefit Azure services, especially for those who want to scale their large models efficiently. As today’s MoE is still in its early stages and more efforts are needed to realize its full potential, Tutel will continue evolving and bring us more exciting results.
Acknowledgment
The research behind Tutel was conducted by a team of researchers from across Microsoft, including Wei Cui, Zilong Wang, Yifan Xiong, Guoshuai Zhao, Fan Yang, Peng Cheng, Yongqiang Xiong, Mao Yang, Lidong Zhou, Rafael Salas, Jithin Jose, Kushal Datta, Prabhat Ram, and Joe Chau.



