
SUMEval 2022
Scaling Up Multilingual Evaluation Workshop @ AACL 2022
Location: Online only
The task of performance prediction is to be able to accurately predict the performance of a model on a set of target languages. These languages may be present in the fine-tuning data (few-shot training) or may not be present (zero-shot training). The languages used for fine-tuning are referred to as pivots, while the languages that we would like to evaluate model on are targets. This shared task will consist of building a machine learning model that can accurately predict the performance of a multilingual model on languages and tasks that we do not have test data for, given accuracies of models on various combinations of pivot and target pairs.
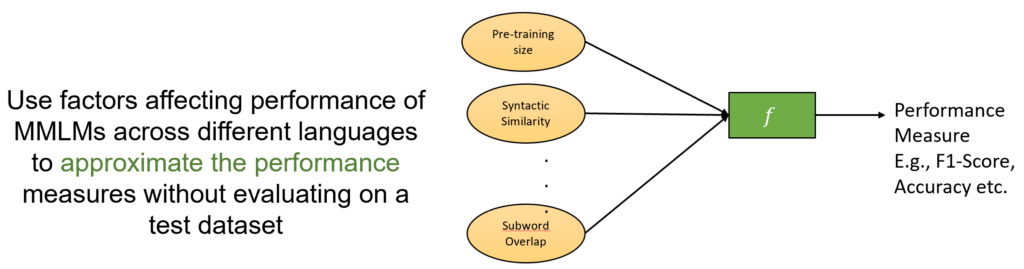
Challenge details:
We will release a dataset containing evaluation scores of multiple MMLMs on different tasks and languages. These scores can be used to train models that can predict how MMLMs trained on different pivot configurations will perform on target languages. For example, our training dataset may be as follows:
| MMLM | Task | Training Pivot configuration (language, data size) | Evaluation result (language, score) |
| mBERT | TyDiQA | (en, 1000), (sw, 1000), (ko, 1600), (ar, 14000) | (te, 0.81), (ko, 0.68), (id, 0.85), (en, 0.77) |
| XLMR | TyDiQA | (en, 10000), (bn, 2000), (te, 2000), (ru, 1000) | (te, 0.84), (ko, 0.69), (id, 0.87), (en, 0.76) |
The task is now to predict the model’s performance, given the following training configuration and test languages:
| MMLM | Task | Training Pivot configuration (language, data size) | Predicted result (language, score) |
| XLMR | TyDiQA | (en, 5000), (ar, 2000), (fi, 1000), (ko, 3000) | (te, ??), (ko, ??), (id, ??), (en, ??), (zh, ??), (ja, ??) |
Predictions will need to be made on test languages included in the training data, as well as surprise languages. For more details on the task formulation, please refer to the papers at the bottom of this page.
Dataset: The training dataset for the challenge can be found here (opens in new tab). Please refer to the Readme in the folder for details.
Evaluation procedure and Baseline numbers: Evaluation will be done in two conditions: Leave One Configuration Out (LOCO) and Surprise Languages.
Evaluation instructions: Litmus/SumEval at main · microsoft/Litmus · GitHub (opens in new tab)
Challenge Timeline (tentative):
- June 28 2022: Dataset release
- July 1 2022: Baseline numbers release
- August 1 2022: Test set release (non-surprise languages) and leaderboard opens.
- August 8 2022: Surprise languages test set released.
- August 15 2022: Challenge ends
- August 25 2022: Paper submission deadline
References:
- Xia, Mengzhou, Antonios Anastasopoulos, Ruochen Xu, Yiming Yang, and Graham Neubig. “Predicting Performance for Natural Language Processing Tasks. (opens in new tab)” In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 8625-8646. 2020.
- Srinivasan, Anirudh, Gauri Kholkar, Rahul Kejriwal, Tanuja Ganu, Sandipan Dandapat, Sunayana Sitaram, Balakrishnan Santhanam, Somak Aditya, Kalika Bali, and Monojit Choudhury. “Litmus predictor: An AI assistant for building reliable, high-performing and fair multilingual NLP systems.” (opens in new tab) In Thirty-sixth AAAI Conference on Artificial Intelligence. AAAI. System Demonstration. 2022.
- Ye, Zihuiwen, Pengfei Liu, Jinlan Fu, and Graham Neubig. “Towards More Fine-grained and Reliable NLP Performance Prediction.” (opens in new tab) In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp. 3703-3714. 2021.
- Ahuja, Kabir, Shanu Kumar, Sandipan Dandapat, and Monojit Choudhury. “Multi Task Learning For Zero Shot Performance Prediction of Multilingual Models. (opens in new tab)” In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5454-5467. 2022.