

We are announcing SMART, a generalized pretraining framework for a wide variety of control tasks.

Self-supervised pretraining of large neural networks (BERT (opens in new tab), GPT (opens in new tab), MoCo (opens in new tab), and CLIP (opens in new tab)) has been shown to be successful in a wide range of language and vision problems. These works demonstrate that one single pretrained model can be easily finetuned to perform many downstream tasks, resulting in a simple, effective, and data-efficient paradigm. When it comes to control tasks, however, it is not clear yet whether the successes of pretraining approaches can be easily replicated. So, we ask the question: can we enable similar pretraining paradigm for efficient decision-making across various control tasks?
In “SMART: Self-supervised Multi-task pretrAining with contRol Transformers (opens in new tab)“, to be published at ICLR2023 (opens in new tab) (as notable-top-25%), we study how to pretrain a versatile, generalizable and resilient model for a wide variety of control tasks. We demonstrate that SMART can significantly improve the learning efficiency and facilitate rapid transfer to novel tasks under different learning scenarios including Imitation Learning (IL) and Reinforcement Learning (RL). Benefiting from the proposed control-centric objective, SMART is resilient to distribution shift between pretraining and finetuning, and even works well with low-quality datasets that are randomly collected.
We now discuss the challenges and introduce our key designing concepts and technical details.
Challenges unique to control tasks
There are research efforts that investigate application of pretrained vision models to facilitate control
tasks. However, there are challenges unique to sequential decision making and beyond the considerations of existing vision and language pretraining. We highlight these challenges below:
- Data distribution shift: Training data for decision making tasks is usually composed of trajectories generated under some specific behavior policies. As a result, data distributions during pretraining, downstream finetuning and deployment can be drastically different, resulting in a suboptimal performance.
- Large discrepancy between tasks: In contrast to language and vision where the underlying semantic information is often shared across tasks, decision making tasks span a large variety of task-specific configurations, transition functions, rewards, and state-action spaces as well. Consequently, it is hard to obtain a generic representation for multiple decision-making tasks.
- Long-term reward maximization: A good representation for downstream policy learning should capture information relevant for both immediate and long-term planning, which is usually hard in tasks with long horizons, partial observability, and continuous control.
- Lack of supervision and high-quality data: Success in representation learning often depends on the availability of high-quality expert demonstrations and ground-truth rewards. However, for most sequential decision-making tasks, high-quality data and/or supervisory signals are either non-existent or prohibitively expensive to obtain.
Unlocking generalized pretraining-finetuning pipeline for sequential decision-making
In this work, we follow ideas established in vision and language community to explicitly define our pretraining and finetuning pipeline. Specifically, during the pretraining phase we train representations with a large offline dataset collected from a set of training tasks. Then, given a specific downstream task which may or may not be contained in pretraining tasks, we attach a simple policy head on top of the pretrained representation and train it with Imitation Learning (IL) or with Reinforcement Learning (RL). The central tenet of pretraining is to learn generic representations which allow downstream task finetuning to be simple, effective, and efficient, even under low-data regimes. The pretrained model is expected to be:
- Versatile so as to handle a wide variety of downstream control tasks and variable downstream learning methods such as IL and RL,
- Generalizable to unseen tasks and domains spanning multiple rewards and agent dynamics, and
- Resilient to varying-quality pretraining data without supervision.
SMART architecture and framework
A unified model architecture to fit different learning methods
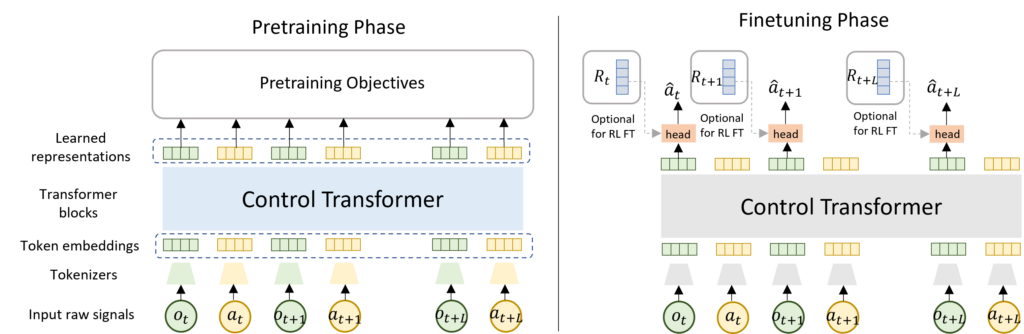
Inspired by the recent success of transformer models in sequential modeling, we propose a Control Transformer (CT). The input to the model is a control sequence composed of observations and actions, and the outputs of CT correspond to token embeddings representing each observation and action, respectively. The figure below depicts the CT architecture. Different from the Decision Transformer (DT) (opens in new tab) which directly learn reward-based policies, CT is designed to learn reward-agnostic representations, which enables it as a unified model to fit different learning methods (e.g. Imitation Learning (IL) and Reinforcement Learning (RL)) and various tasks.
Control-centric pretraining objectives to learn generic representations
Built upon CT, we propose a control-centric pretraining objective that consists of three terms: forward dynamics prediction, inverse dynamics prediction and random masked hindsight control. The figure below illustrates each objective. These terms focus on policy-independent transition probabilities and encourage CT to capture dynamics information of both short-term and long-term temporal granularities.
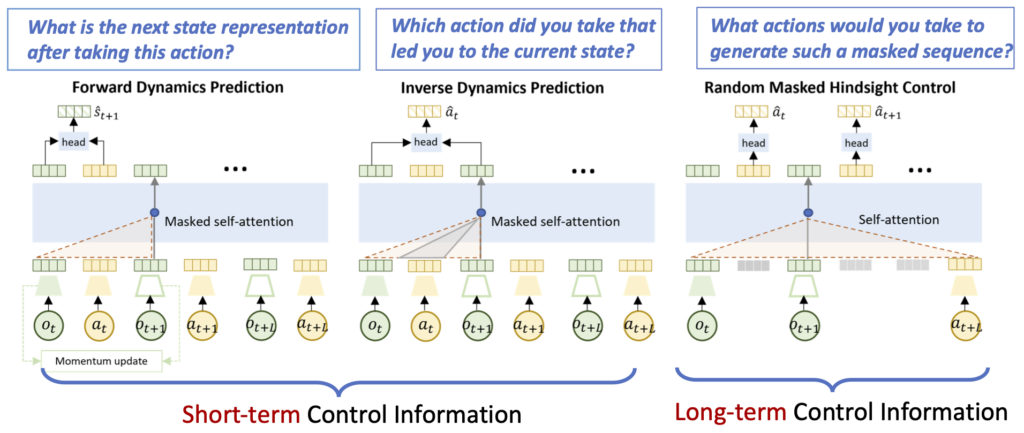
- Forward Dynamics Prediction: For each observation-action pair in a control sequence, we aim to predict the next immediate latent state. This forward prediction captures the local transition information in the embedding space.
- Inverse Dynamics Prediction: For each consecutive observation pair, we learn to recover the action that leads to the transition between the observation pair.
- Random Masked Hindsight Control: Given a control sequence, we randomly mask part of actions and observations, and recover the masked actions based on the remaining incomplete sequence. This objective is akin to asking the question “what actions should I take to generate such a trajectory?” Therefore, we replace the causal attention mask with a non-causal one, to temporarily allow the model “see the future”. As a result, we encourage the model to learn controllable representations and global temporal relations, and to attend to the most essential representations for multi-step control.
Experimental results highlights
The multi-task DMC benchmark
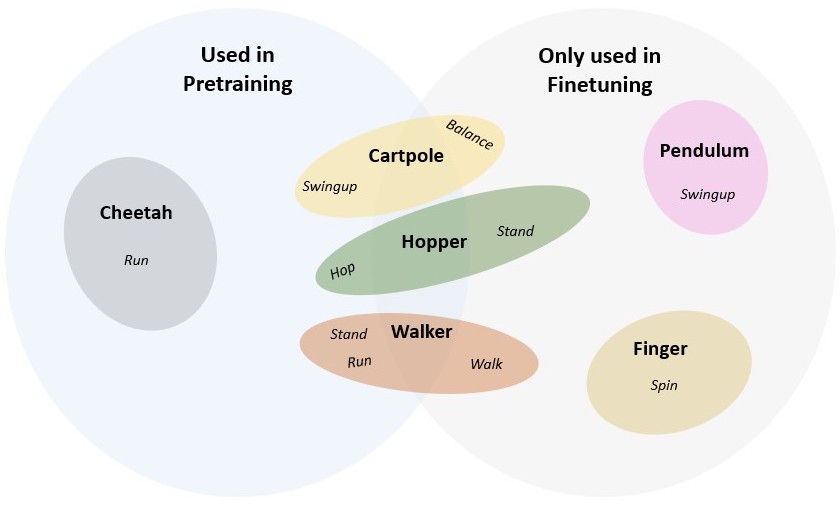
We evaluate SMART on the DeepMind Control (DMC) suite (opens in new tab), which contains a series of continuous control tasks with RGB image observations. There are multiple domains (physical models with different state and action spaces) and multiple tasks (associated with a particular MDP) within each domain, which creates diverse scenarios for evaluating pretrained representations. Our experiments use 10 different tasks spanning over 6 domains. In pretraining, we use an offline dataset collected over 5 tasks, while the other 5 tasks (with 2 unseen domains) are held out to test the generalizability of SMART. The graphical relations of all tasks and domains involved are shown in the figure below.
Versatility
To evaluate the versatility of SMART, we design experiments to answer the following questions:
- Whether a single pretrained model can be finetuned with different downstream learning methods (i.e. Return-To-Go conditioned (RTG) and Behavior Cloning (BC));
- Whether the pretrained model can adapt towards various downstream tasks.
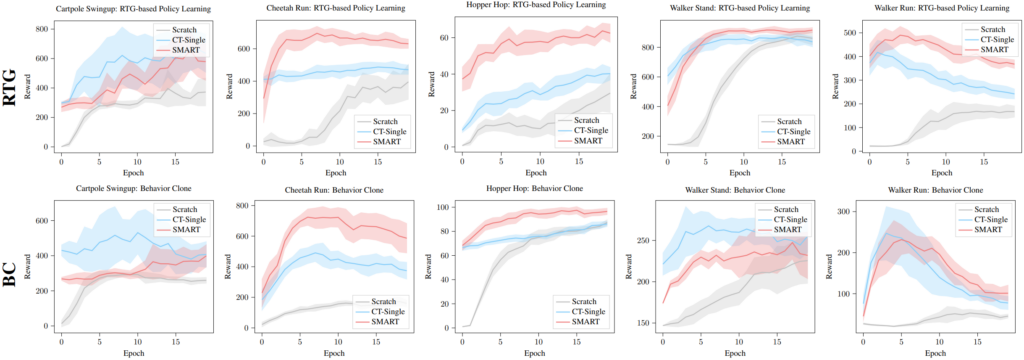
In the figure above, we compare the reward curve of SMART with Scratch and CT-Single, where models are pretrained with Exploratory dataset. It can be seen that pretrained CT from both single-task dataset (CT-single) and multi-task dataset (SMART) can achieve much better results than training from scratch. In general, under both RTG and BC finetuning, pretrained models have a warm start, a faster convergence rate, and a relatively better asymptotic performance in a variety of downstream tasks. In most cases, pretraining CT from multi-task dataset (SMART) yields better results than pretraining with only in-task data (CT-single), although it is harder to accommodate multiple different tasks with the same model capacity, which suggests that SMART can extract common knowledge from diverse tasks.
Generalizability
The figure shows the performance of SMART pretrained on Exploratory dataset, compared to Scratch and CT-single on 5 unseen tasks. We can see that SMART is able to generalize to unseen tasks and even unseen domains, whose distributions have a larger discrepancy as compared to the pretraining dataset. Surprisingly, SMART achieves better performance than CT-single in most tasks, even though CT-single has already seen the downstream environments. This suggests that good generalization ability can be obtained from learning underlying information which might be shared among multiple tasks and domains, spanning a diverse set of distributions.

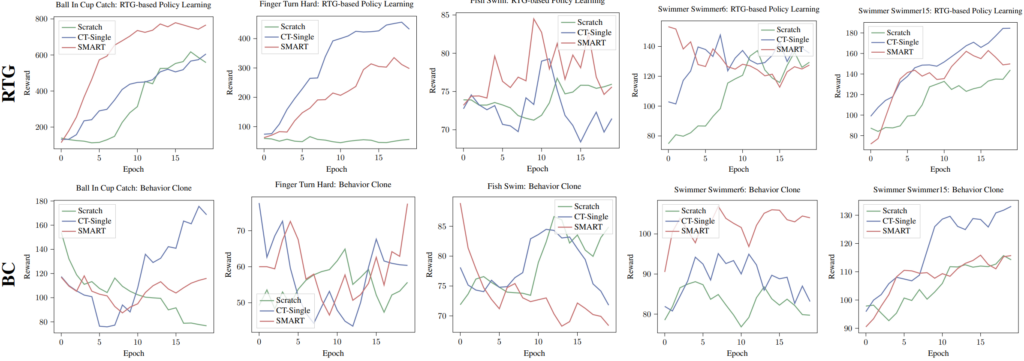
To further investigate the generalizability of SMART, we evaluate the performance of SMART in other more challenging domains and tasks that have larger discrepancy with pretraining domains/tasks. These additional domain-tasks are: ball-in-cup-catch, finger-turn-hard, fish-swim, swimmer-swimmer6 and swimmer-swimmer15. Note that these agents have significantly different appearance and moving patterns compared to pretraining tasks, as visualized in the figure below.

The results are shown in figures below, where we can see that the pretrained model can still work in most cases, even under such a large task discrepancy. Note that here CT-Single is pretrained with data from exactly the downstream task, where SMART has never seen a sample from the downstream tasks and is pretrained on significantly different domains. Therefore, it is unsurprising that CT-Single is generally better than SMART in this setting. However, it is interesting to see that SMART is comparable with or even better than CT-Single in some tasks, suggesting the strong generalizability of SMART. On the other hand, one can imagine that it is unavoidable that the performance of a pretrained model will decrease as the discrepancy between pretraining tasks and downstream tasks increases. Therefore, we stress the importance of using diverse multi-task data for pretraining in practice.

Resilience
We aggregate the results in all tasks by averaging the normalized reward (dividing raw scores by expert scores) in both RTG and BC settings. When using the Exploratory dataset for pretraining, SMART outperforms ACL (opens in new tab), and is comparable to DT (opens in new tab) which has extra information of reward. When pretrained with the Random dataset, SMART is significantly better than DT and ACL, while ACL fails to outperform training from scratch. This result show that SMART is robust to low-quality data as compared to other baseline methods.

Analysis
In large-scale training problems, performance usually benefits from larger model capacity. We investigate if this also applies to sequential decision making tasks by varying the embedding size (width) and the number of layers (depth) in CT. The per-task comparisons are show in the figure below. From the comparison, we can see that in general, increasing the model depth leads to a better performance. However, when embedding size gets too large, the performance further drops, as a large representation space might allow for irrelevant information. In addition, the design choice of model capacity should also be considered together with the training dataset scale and diversity.

Towards Foundation Models for Perception and Control
We are thrilled to announce the release of SMART, a technique designed to bring foundation models for decision-making within reach of a wider audience. Our goal with SMART is to make it easy for anyone to use pretrained foundation models without requiring specialized knowledge of model architecture or pretraining approaches. By leveraging the latest advances in spatio-temporal data analysis, SMART is at the forefront of addressing the challenges of perception and control jointly. Our team is excited to see what the future holds for this powerful new technique.
This work is being undertaken by members of the Microsoft Autonomous Systems and Robotics Research Group and University of Maryland (opens in new tab). The researchers included in this project are: Yanchao Sun (opens in new tab), Shuang Ma (opens in new tab), Ratnesh Madaan (opens in new tab), Rogerio Bonatti (opens in new tab), Furong Huang (opens in new tab), and Ashish Kapoor.