
Microsoft’s mission is to empower every person and organization to achieve more. So, we are constantly looking for opportunities to simplify workflows and save people time and effort. Sending replies to email or chat messages is a common activity and people spend considerable amount of time on it. By harnessing the power of AI, we are helping people reply faster by intelligently suggesting replies which can be used to easily respond to messages with a simple click or tap on the device. For email messages, people can then edit the response or hit the ‘Send’ button, while for chat messages, the reply is immediately sent. The difference in behavior is designed keeping in mind that for chats, people can break their reply content into a few adjacent chat snippets and so immediately sending the reply offers the quickest workflow. We have also expanded the feature to multiple international languages like Spanish, Portuguese, French and Italian and plan to roll out to several new languages and markets in the next year. This feature currently saves users hundreds of millions of keystrokes each month.
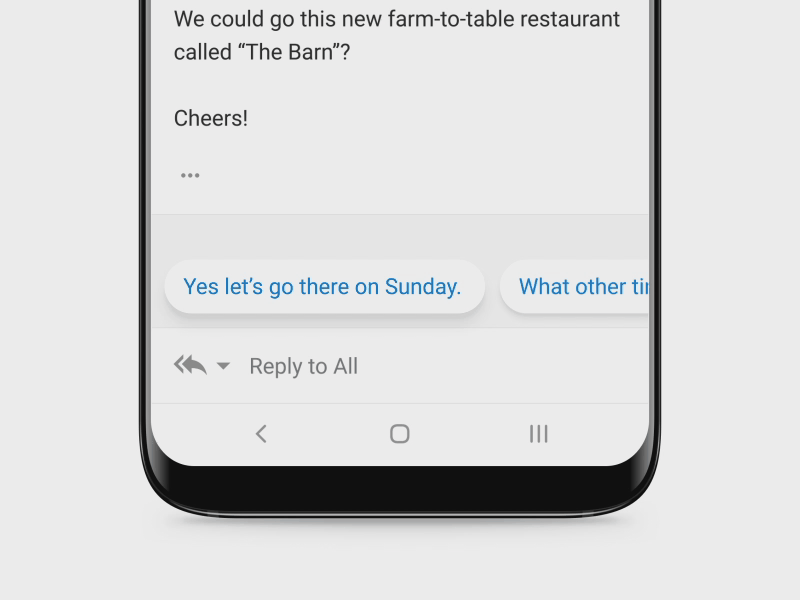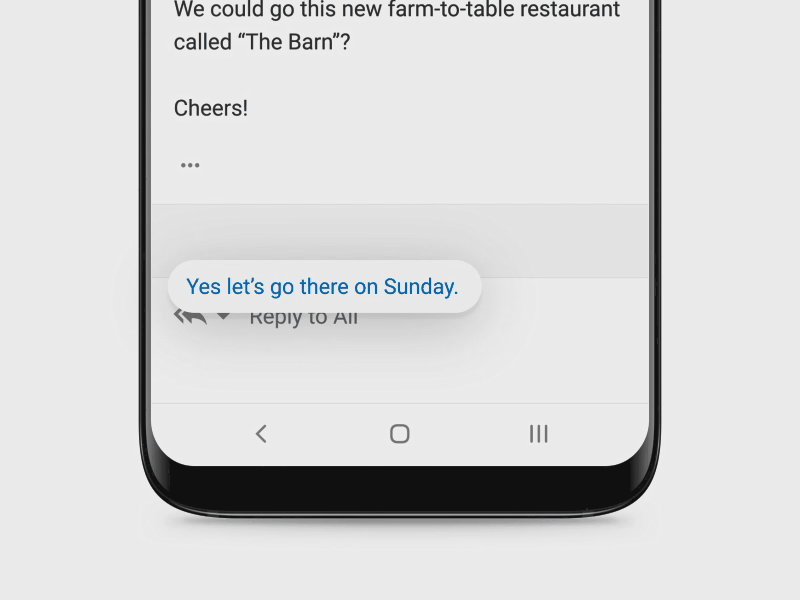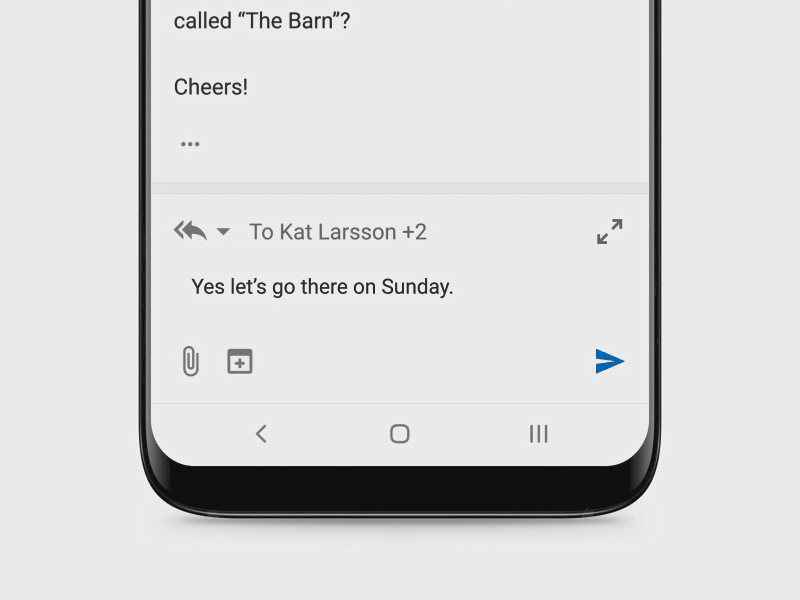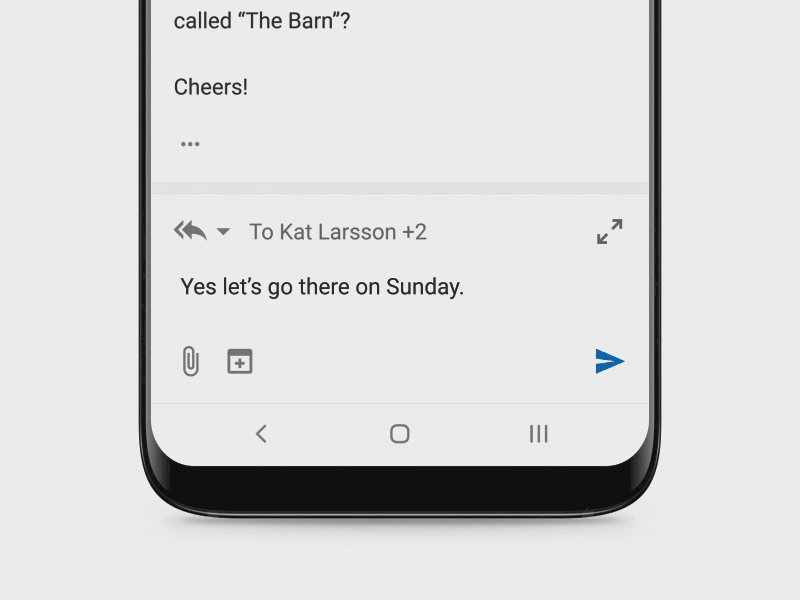
This feature is powered by a deep neural network trained on hundreds of millions of Messages (Emails or chats) and their Replies called Message-Reply (MR) pairs. Since all the data for training the model is user content, the models are trained in an eyes-off fashion by leveraging an experimentation stack (opens in new tab) built on top of Office 365 and Azure technologies which is fully compliant with user privacy and enterprise contractual obligations. The platform offers complete data security and GDPR compliance for customer data. For evaluation, we use a variant of Rouge (opens in new tab)for comparing the model predictions and the ground truth reply and assign a score for each prediction. Using this automated metric allows us to run the evaluation in an eyes-off fashion. In addition to the eyes-off evaluation, we also do some qualitative evaluations on public and personal emails to get a better understanding of the model predictions and to improve quality of suggestions.
Our system models the problem of suggesting responses to messages as an Information Retrieval task (opens in new tab) where given a message, suggestions are selected from a fixed list of responses called the Response set. The messages and responses are encoded with parallel networks and the system is trained to match them for real Message-Response pairs using a Symmetric loss (opens in new tab) function. We use Transformer (opens in new tab)encoder networks for encoding the Messages & Responses. Since the Response side encoder is pre-computed, we use larger number of layers (12) there compared to the Message side (6). The entire model is initialized using Microsoft Turing model for natural language representation (NLR) (opens in new tab), a large-scale model pioneered by Microsoft and then fine-tuned for the task of matching Messages and Responses. As we train large models on millions of MR pairs, we are leveraging optimization breakthroughs like ZeRO to fit larger batch sizes in memory and obtain impressive gains in training speed and model performance. Overall, Suggested replies is a great example of AI at Scale (opens in new tab) powering next generation AI experiences.

Generating an appropriate set of possible responses is a critical step in training our Suggested replies models. Our response set generation algorithms are built to ensure strict privacy protections. First, among hundreds of millions of replies that are present in the datasets we only consider short popular responses that are syntactically void of any personally identifiable information. Next, we employ state of the art Differentially Private algorithms (opens in new tab) to further narrow the set of response to those that can be exposed while adhering to rigorous privacy requirements[1]. Later, the chosen snippets of text are brought outside of compliance boundary and further curated by humans to ensure that the content is generic, grammatical and fair (i.e., does not include offensive, inappropriate or biased statements).
We are committed to honoring your trust and continuing to improve our system in a privacy-preserving and compliant manner. We are actively working on making the suggestions align to users unique writing style and making the feature available across multiple languages worldwide. Stay tuned for more and in the meantime please let us know if you have any feedback, we always love to hear from you.
[1] Currently we use differentially private algorithms with privacy parameters (ε=4, δ< 10-7)