

Imitation learning has proven to be effective for learning sequential decision-making policies directly from expert demonstrations, reducing the need for costly and risky environmental interactions. Behavioral cloning is a simple form of imitation learning and learns a policy by solving a supervised learning problem over state-action pairs from expert demonstrations. Despite its simplicity, behavioral cloning has been successful in a wide range of tasks in artificial intelligence.
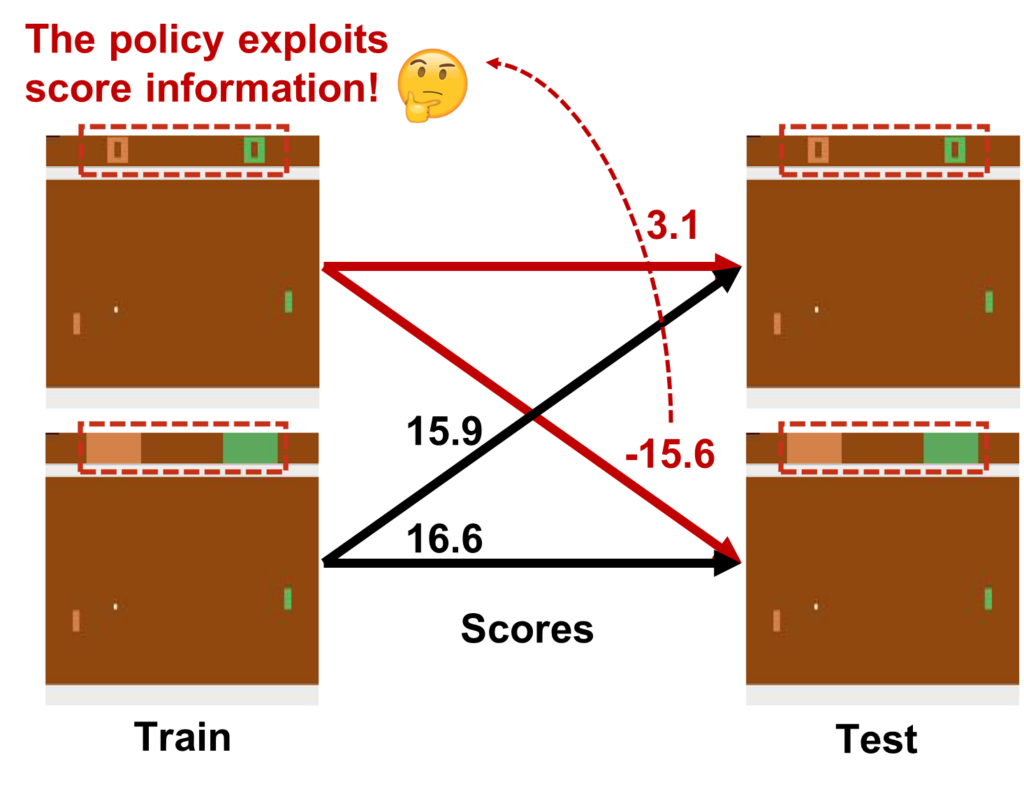
Figure 1. An Atari Pong environment with original images (top) and images where scores are masked out (bottom). The policy trained with original images suffers in both environments (red), which shows that the policy attends to score indicators for predicting expert actions instead of learning the underlying rule of the environment.
However, recent evidence shows that behavioral cloning often suffers from the causal confusion problem, where the policy relies on the effect of expert actions and not on the causes we desire. Figure 1 shows an example of this. In an Atari Pong environment, score indicators are located at the top of image observations. The policy trained in this environment was unable to work when the score was masked out. This is because the policy was trained to attend to the score indicators (as the spurious causes for actions) and not the paddles and the ball, which are the true causes for actions here.
One possible solution for addressing this problem is the causal discovery approach, which can deduce cause and effect from observational data. However, it is difficult to apply this approach to high-dimensional inputs/environments such as images, because it usually does not satisfy the assumption that inputs are structured into random variables connected by a causal graph [1]. To address this limitation, the interventional discovery method [2] was recently proposed. This method learns a policy on top of representations from a beta-VAE [3] and infers a causal graph by using environmental interactions. However, it requires a substantial amount of interactions, which could be often unavailable or incur additional costs.
Professor Jinwoo Shin at KAIST in South Korea and his collaborators, Chang Liu, Li Zhao, Tao Qin, and Tie-Yan Liu of Microsoft Research Asia, along with KAIST Ph.D. students Jongjin Park and Younggyo Seo, have been investigating a new regularization technique to address the causal confusion problem without having costly environmental interactions. Their pioneering idea is described in a paper entitled “Object-Aware Regularization for Addressing Causal Confusion in Imitation Learning” and was presented at the 35th Conference on Neural Information Processing Systems (NeurIPS 2021) that was held Nov. 29-Dec. 9. In the paper, they proposed object-aware regularization, a simple technique that regularizes an imitation policy in an object-aware manner. See Figure 2.
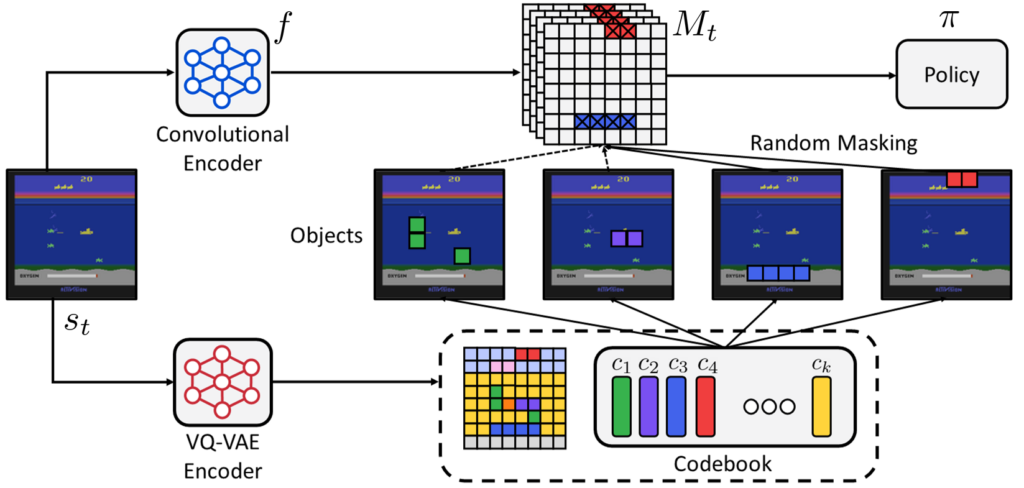
Figure 2. Overview of Object-aware Regularization. The researchers first trained a VQ-VAE model that encodes images into discrete codes from a codebook, then regularize a policy by randomly dropping units that share the same discrete code together, i.e., random objects, throughout training.
Paper link: https://arxiv.org/abs/2110.14118 (opens in new tab)
Motivation behind this technique stemmed from the existing failings of behavioral cloning: in the Atari example in Figure 1, researchers observed that the encoder trained with behavioral cloning was missing information on important objects because it was primarily focusing on the effects of previous actions. To prevent the policy from exploiting such information strongly correlated with expert actions, object-aware regularization encourages the policy to uniformly attend to all semantic objects in images. To achieve this, the researchers introduced a two-stage approach: they first trained a VQ-VAE [4] model that encodes images into discrete codes, i.e., objects, then learned the policy with their regularization scheme of randomly dropping units that share the same discrete codes.
Examples of learned discrete codes are shown in Figure 3. Each code is represented by a different color, and one can observe that similar objects (e.g., the paddles in the Pong environment) exhibit similar colors, i.e., they are mapped into the same or similar discrete codes. Then, during behavioral cloning, those codes are dropped randomly for regularization. In such a way, object-aware regularization randomly masks out semantically similar objects, which allows object-aware regularization of the policy.

Figure 3. Visualization of the discrete codes from a VQ-VAE model trained on eight confounded Atari environments, where previous actions are augmented to the images. The odd columns show images from environments, and even columns show the corresponding quantized feature maps (visualized by 1D t-SNE).
The researchers empirically demonstrated that object-aware regularization improves behavioral cloning in various environments such as Atari games and self-driving environments [5], and outperforms existing baselines including regularization [6,7], data augmentation [8,9], and causality-based methods [2,10] without having any environmental interactions. Also, experimental results show that object-aware regularization even outperforms inverse reinforcement learning methods [11,12] trained with a considerable amount of environmental interaction. They further investigated the possibility of applying object-aware regularization to other imitation learning methods and demonstrated that their method can also be applied to inverse reinforcement learning methods that involve behavioral cloning.
References
[1] Pearl, Judea. “Causality”. Cambridge University Press, 2009.
[2] de Haan, Pim, Dinesh Jayaraman, and Sergey Levine. “Causal confusion in imitation learning.” In NeurIPS, 2019.
[3] Irina Higgins et al., “Higgins, Irina, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. “beta-vae: Learning basic visual concepts with a constrained variational framework.” (2016).”, In ICLR, 2017.
[4] Oord, Aaron van den, Oriol Vinyals, and Koray Kavukcuoglu. “Neural discrete representation learning.” In NeurIPS, 2017.
[5] Dosovitskiy, Alexey, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. “CARLA: An open urban driving simulator.” In Conference on robot learning, 2017.
[6] Srivastava, Nitish, Hinton, Geoffrey, Krizhevsky, Alex, Sutskever, Ilya, and Salakhutdinov, Ruslan. “Dropout: a simple way to prevent neural networks from overfitting”. The Journal of Machine Learning Research, 15(1):1929–1958, 2014.
[7] Ghiasi, Golnaz, Lin, Tsung-Yi, and Le, Quoc V. “Dropblock: A regularization method for convolutional networks”. In NeurIPS, 2018.
[8] DeVries, Terrance and Taylor, Graham W. “Improved regularization of convolutional neural networks with cutout”. arXiv preprint arXiv:1708.04552, 2017.
[9] Yarats, Denis, Kostrikov, Ilya, and Fergus, Rob. “Image augmentation is all you need: Regularizing deep reinforcement learning from pixels”. In ICLR, 2021.
[10] Shen, Zheyan, Cui, Peng, Kuang, Kun, Li, Bo, and Chen, Peixuan. “Causally regularized learning with agnostic data selection bias”. In ACM international conference on Multimedia, 2018.
[11] Ho, Jonathan and Ermon, Stefano. “Generative adversarial imitation learning”. In NeurIPS, 2016.
[12] Brantley, Kiante, Sun, Wen, and Henaff, Mikael. “Disagreement-regularized imitation learning”. In ICLR, 2020.