

Over the past 6 months we’ve been experimenting with a host of changes to Microsoft Academic’s search experience, and now that the last of those experiments has shipped we’re excited to finally discuss them.
Before we jump in, if you’re interested in a deeper technical analysis of the new capabilities please review the following resources:
- A Review of Microsoft Academic Services for Science of Science Studies (opens in new tab)
A comprehensive scientific review of the different technologies and algorithms used to create Microsoft Academic Services, which power Microsoft Academic - Microsoft Academic Knowledge Exploration Service (MAKES) technical documentation (opens in new tab)
MAKES is a version of both the search API and search index behind Microsoft Academic, freely available to use in Azure
No room for interpretation?
From the initial release of Microsoft Academic in 2016, up until 6 months ago, our semantic search algorithm focused on generating results that best matched semantically coherent interpretations of user queries, informed by the Microsoft Academic Graph (MAG) (opens in new tab).
To better explain, let’s examine the query “covid-19 science”. Traditional search engines based on keyword search (i.e. Google Scholar, Semantic Scholar, Lens.org, etc.) do an excellent job of retrieving relevant results that have keyword matches for “covid-19” and variations of “science” (science, sciences, scientific, etc.) Our system, however, prefers to interpret “covid-19” as a shorthand reference (synonym) of the topic “Coronavirus disease 2019 (COVID-19)” (opens in new tab) and “science” as the journal “Science” (opens in new tab) because MAG suggests this interpretation will turn up more highly cited and relevant papers than treating the query as simple paper full-text (title/abstract/body) keywords. This distinction is important, as it allows our semantic search algorithm to leverage semantic inference to retrieve seminal publications that do not strictly contain “covid-19” as keywords, yet are nevertheless relevant and important.
Regardless, we still previously allowed for rudimentary keyword matching, namely, prefix and literal unigram matching of publication titles (with no support for stemming or spelling corrections). Unfortunately, the outcome of this limited keyword matching was frequently encounters with the dreaded “no results” page.
For example, assume you were looking for a paper that you thought was named “heterogeneous network embeddings via deep architectures”. Entering this phrase as a query would result in no suggestions and an error page if executed on the site:
![]()
This is a classic case of users knowing what they want but having difficulty getting an algorithm to understand. A common problem with keyword search is it puts the burden of choosing the “right” keywords for a query squarely on the shoulder of the user.
Now with our newest search implementation this same query will work exactly as intended:
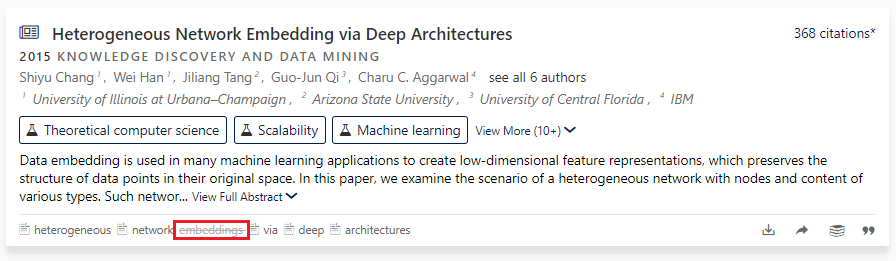
To understand why this now works we first need to explain how our semantic search implementation works.
Ok, maybe a little room for interpretation
To put it simply, we’ve changed our semantic search implementation from a strict form where all terms must be understood to a looser form where as many terms as possible are understood.
The formulation of semantic interpretations (as explained above) remains unchanged, in that the knowledge in MAG still plays the central role in guiding how a query should be interpreted. What has changed is that when a portion of a query is thought to refer to full-text properties (i.e. title, abstract), the algorithm can now dynamically switch to a new scoring function that is more appropriate than literal unigram matching and hence less brittle as the example above shows.
Going a bit deeper, let’s define what “as many terms as possible are understood” means. By its nature, loose semantic query interpretation will produce interpretations with the highest coverage first and fastest, and as interpretations with less coverage (i.e. terms are dropped from consideration) are generated the relevance and speed decrease. The reasons for this are technical and have to do with the search space growing exponentially as the query considered becomes less specific. So in practice “as many as possible” is better defined as “as many as possible in a fixed amount of time”.
This means that factoring in variables such as query complexity and service load, the results generated from a fixed timeout where terms are more loosely matched (aka the result “tail”) could vary between sessions. However because the interpretations with highest coverage are generated first, the results they cover (aka the “head”) are very stable.
While this change is a great remedy for queries with full-text matching intent, the loosened interpretation does also impact semantic search results as they are no longer as concise as before due to a longer result “tail” that includes full-text matches.
As always, an example speaks a thousand words:
 |
|
BEFOREShow results matching top interpretations where all query terms are understood, ranked only by paper salience (static rank, aka importance)
|
AFTERShow results matching top interpretations where as many query terms as possible are understood, ranked first by number of terms matched then by paper salience
…
|



Let’s take a closer look at the new “loose” semantic search algorithm, as it comes with a new user interface that illustrates how each search result is understood in the context of the user query:
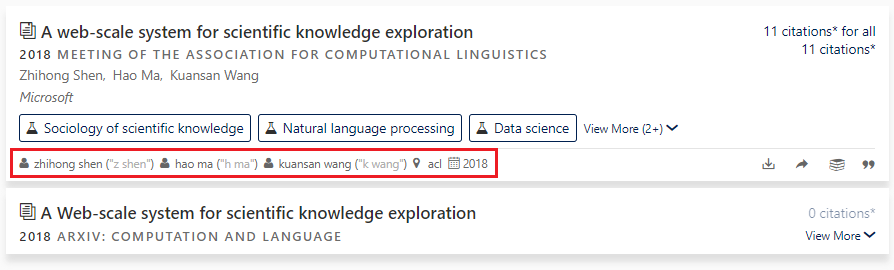
|


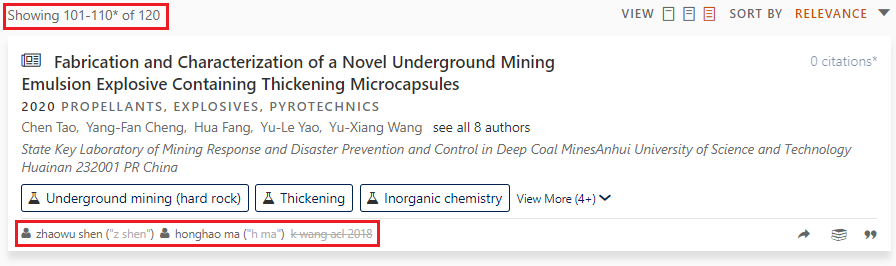
Matching phrases
Historically Microsoft Academic has support for matching queries to values in a few different ways:
- Matching exact values, e.g.
“a web scale system for scientific knowledge exploration” => “a web scale system for scientific knowledge exploration” - Matching the beginning of values (aka prefix completions, only available as query suggestions), e.g.
“a web scale system for scientific” => “a web scale system for scientific knowledge exploration“ - Literally matching words from the value, e.g.
“microsoft academic overview” => “an overview of microsoft academic service mas and applications“
In addition we now support a new form of partial value matching based on phrases. This is a common feature frequently seen in keyword search, where query interpretation prefers interpretations with closer term proximity. For example, comparing results for the query “deep learning brain images” based on simple word matching and phrase matching:
Top 5 papers using word matching, where results are based on matching words and ranking based on paper static rank:
- Classification of CT brain images based on deep learning networks
(Static rank = -18.994, Distance = 4) - Unsupervised Deep Feature Learning for Deformable Registration of MR Brain Images
(Static rank = -19.036, Distance = 8) - Application of deep transfer learning for automated brain abnormality classification using MR images
(Static rank = -19.305, Distance = 10) - Age estimation from brain MRI images using deep learning
(Static rank = -19.727, Distance = 6) - Exploring deep features from brain tumor magnetic resonance images via transfer learning
(Static rank = -20.06, Distance = 13)
Top 5 papers using phrase matching, where results are based on first matching words and then re-ranking based on edit distance (opens in new tab) between query and value (ignoring stop words):
- Deep Learning on Brain Images in Autism: What Do Large Samples Reveal of Its Complexity?
(Static rank = -20.372, Distance = 0) - Deep learning of brain images and its application to multiple sclerosis
(Static rank = -20.534, Distance = 0) - Classification of CT brain images based on deep learning networks
(Static rank = -18.994, Distance = 4) - Unsupervised Deep Feature Learning for Deformable Registration of MR Brain Images
(Static rank = -19.036, Distance = 8) - A deep learning-based segmentation method for brain tumor in MR images
(Static rank = -20.171, Distance = 6)
This new ability to re-rank based on query-value edit distance also allows us to support quoted phrases in queries:

The rules for quoted values are:
- A quoted value can only be matched to a single field, i.e. title, author name, journal name, etc.:
Works: “deep learning” (matches field of study)
Works: “microsoft research” (matches affiliation)
Doesn’t work: “deep learning microsoft research” - For attributes that support partial matching (title, abstract), all quoted words must have a term-based edit distance (opens in new tab) of zero, ignoring stop words (opens in new tab):
Works: “deep learning brain images”
Doesn’t work: “brain deep images learning” - Queries can contain multiple quoted values, each being evaluated using the rules defined above:
Works: “deep learning” “microsoft research” - A quoted value is treated as a single query term and can be dropped accordingly based on the new search algorithm:
Doesn’t work: “deep learning at microsoft research rocks!”
Works: deep learning “at microsoft research rocks!” - All terms in a quoted value are normalized in exactly the same fashion (opens in new tab) as non-quoted terms
Support for searching paper abstract
We have finally added support for a long requested feature: searching paper abstracts! This is an important addition that significantly expands the reach of our partial-term matching for papers.
Abstracts are treated like all other semantic values, meaning they can be matched implicitly or explicitly using the “abstract:” scope, e.g.:
- title: “microsoft academic” abstract: “heterogeneous entity graph”
- “microsoft academic” “heterogeneous entity graph”
Scoped queries
Microsoft Academic has always supported query “hints” that require subsequent terms to match a specific attribute, i.e. the classic “papers about
The rules for scopes are simple: the query term immediately after the scope must be matched with that scopes attribute type. A query “term” is defined as a single word or a quoted phrase. For example, if you wanted to match papers with “heterogeneous”, “entity” and “graph” in their abstracts but didn’t care about them being part of a sequence you would issue the query “abstract: heterogeneous abstract: entity abstract: graph”.
Supported scopes and their corresponding triggers:
| Scope | Description | Example |
| abstract: | Match term or quoted value from the paper abstract | abstract: “heterogeneous entity graph comprised of six types of entities” |
| affiliation: | Match affiliation (institution) name | affiliation: “microsoft research” |
| author: | Match author name | author: “darrin eide” |
| conference: | Match conference series name | conference: www |
| doi: | Match paper Document Object Identifier (DOI) | doi: 10.1037/0033-2909.105.1.156 |
| journal: | Match journal name | journal: nature |
| title: | Match term or quoted value from the paper title | title: “an overview of microsoft academic service mas and applications” |
| topic: | Match paper topic (field of study) | topic: “knowledge base” |
| year: | Match paper publication year | year: 2015 |
Feedback welcome
These changes have been in the works for over 6 months, and as always we’d love to hear your feedback, be it suggestions, critiques, bug reports or kudos. To provide feedback, navigate to Microsoft Academic (opens in new tab) and click the “feedback” icon in the lower right-hand corner.
Stay tuned in the coming weeks for another search-oriented post about how you can accomplish reference string parsing using Microsoft Academic Services!