Project Alexandria
From big data to big knowledge
The aim of Project Alexandria is to automatically extract business knowledge into a single, consistent knowledge base. This powers human-centric experiences that enable people to work effectively with organisational knowledge.
Our work helps address a number of known challenges in the knowledge domain:
- Extracting knowledge: Knowledge in organisations is often represented in different forms and formats and across different silos, which are distributed across both public and private data. This makes it difficult to answer basic questions, such as ‘Who has worked with this client before?’ We automatically extract business knowledge into a single, consistent knowledge base, made up of the entities that really matter to each organisation.
- Sharing knowledge: Making content available to other people within an organisation creates work for organisation members; it can be hard to find the time to post to internal repositories or add appropriate metadata. Generating enterprise knowledge bases through machine learning reduces this effort.
- Surfacing knowledge: Organisation members can be unaware of knowledge that could support them in their current activity, or struggle to apply it in practice. We are exploring how to surface relevant content in context and in a form that is appropriate to the task in hand.
- Knowledge workflows: The experience of work often entails dealing with information overload, interruptions and distractions, and workflows that are fragmented across different tools. We are researching how knowledge of a user’s activity can be used to aid focus, support task resumption, and streamline a workflow across apps.
The project brings together researchers with diverse backgrounds in machine learning, social science, design and engineering. From a computer science perspective, we focus on using unsupervised machine learning to automatically create entities and their associated schema from an organisation’s data. We operate in an eyes-off environment, allowing our work to be applied in enterprise settings, where data sits behind compliance boundaries.
In parallel we undertake human-centred research to understand how storage silos additionally reflect social norms and practices, how presenting work through intelligent systems invites curation and contribution from authors, what it means to make organisational knowledge available in a form that can be applied in practice, and how knowledge of a person’s activity can be used to support focused work.
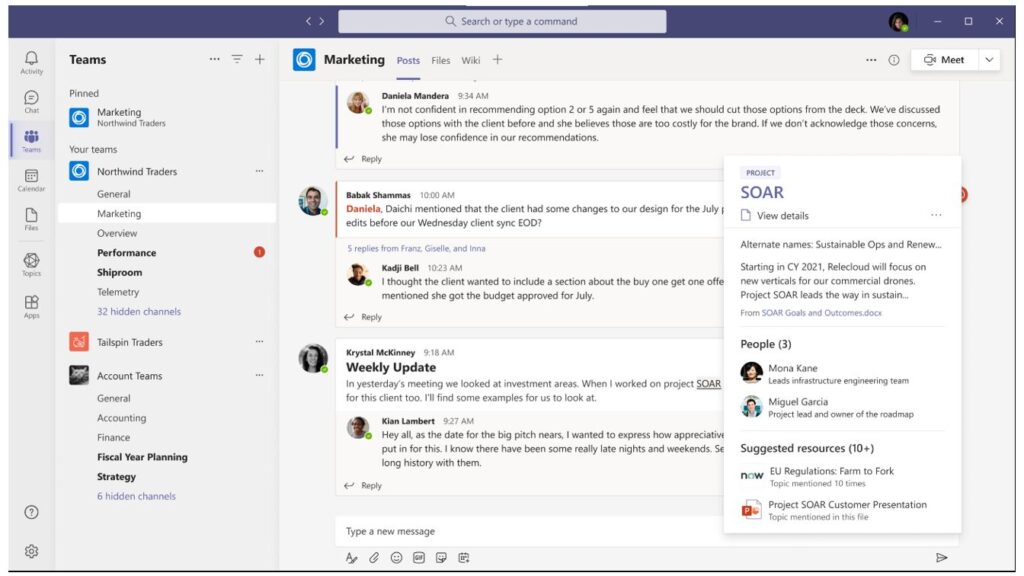
Project Alexandria in Viva Topics
Alexandria plays a pivotal role in Viva Topics, a new product announced by Microsoft in February 2021. The Alexandria team is responsible for identifying topics and rich metadata and combining other innovative Microsoft knowledge mining technologies to enhance the end user experience of this product. You can read more about our work on Viva Topics on the Microsoft Research Blog.