
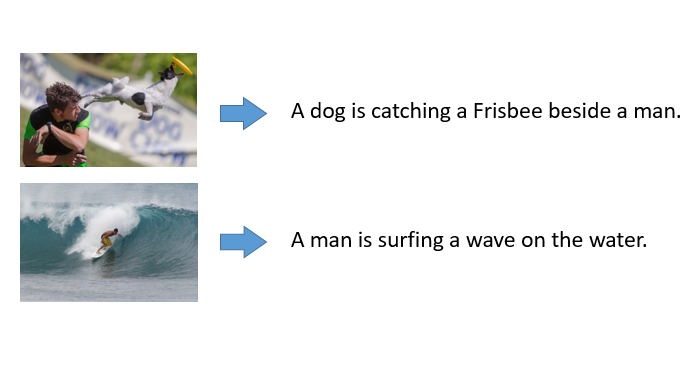
We study the problem of image captioning, i.e., automatically describing an image by a sentence. This is a challenging problem, since different from other computer vision tasks such as image classification and object detection, image captioning requires not only understanding the image, but also the knowledge of natural language. We formulate this problem as a multimodal translation task, and develop novel algorithms to solve this problem.