
MSR Image Recognition Challenge (IRC)
@ACM Multimedia 2016

Import Dates/Updates:
- We have finished the latest challenges at ICCV 2017.
- Participants information disclosed in “Team Information” section below
- 6/21/2016: Evaluation Result Announced in “Evaluation Result ” section below.
- 6/17/2016: Evaluation finished. 14 teams finished the grand challenge!
- 6/13/2016: Evaluation started.
- 6/13/2016: Dry run finished, 14 out of 19 teams passed, see details in “Update Details” below
- 6/10/2016: Dry run update 3: 8 teams passed, 11 teams ongoing, see details in “Update Details” below.
- 6/9/2016: Dry run update 2: 7 teams passed, 11 teams ongoing, see details in “Update Details” below.
- 6/8/2016: Dry run update 1: 5 teams finished, 13 teams ongoing, see details in “Update Details” below.
- 6/7/2016: Dry run started, dev set are being sent to each recognizer, see details in “Update Details” below
- 6/3/2016: update about the dry run started on June 7, see details in “Update Details” below
- 5/27/2016: SampleCode/GUIDs/TestTool are released to each team, see details in “Update Details” below
- 5/9/2016: Development dataset is released for download, to be used during dry-run.
- 5/9/2016: Competition/paper registration is opened here, Please provide your Team Name (as the paper title), Organization (as the paper abstract), Team Members and Contact information (as the paper authors).
- 4/29/2016: Entity list is released for download
- 4/5/2016: Cropped and aligned faces are ready for download
- 4/4/2016: More data are available to for downloading: samples
- 4/1/2016: Ms-Celeb-V1 ImageThumbnails ready for downloading! More data coming soon
-
6/21/2016 Evaluation Result
Random Set:
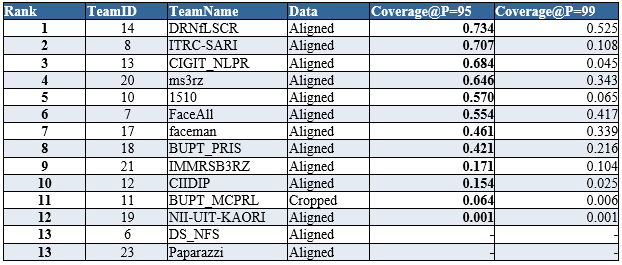
Hard Set:
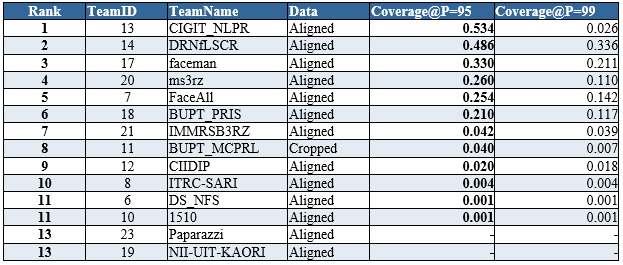
Remarks:
- For the teams processed both Aligned and Cropped faces, we use the best result of the two.
- Coverage = “-” means the precision does not reach 95%/99%, so the coverage number is undefined.
- We will announce team member list shortly.
-
10/11/2016 Team Information
TeamID TeamName Summary Algorithm Affiliation Team Member 5 HFUT_LMC Hefei University of Technology kecai wu
mingyu liou
6 DS_NFS Institute of Software, Chinese Academy of Science Chuan Ke
Zi Li
Rongrong Xiang
Wenbo Li
7 FaceAll Face Recogniton with A Simplified CNN and A Two-Stage Training Strategy We applied a simplified Googlenet-liked CNN with only 0.6B FLOPS and 4.8M parameters(ignoring the last fully-connected layer) for this evaluation. A two-stage training strategy was used. Firstly, 27,157 classes each with over 100 images(a total of 3,083,130 images) were choosed to train the network in the first stage. Secondly, we sampled 50 images from those classes with over 50 images(due to time limitation) and retained all the images of other classes(a total of 4,791,987 images of 99,891 classes). Only the last fully-connnected layer was finetuned. All the experiments were done in the last week. Beijing Faceall Technology Co., Ltd Fengye Xiong
Zhipeng Yu
Yu Guo
Hongliang Bai
Yuan Dong, Beijing University of Posts and Telecommunications
8 ITRC-SARI Face Recognition via Active Image Annotation and Learning we introduce an active annotation and learning framework for the face recognition task. Starting with an initial label deficient face image training set, we iteratively training a deep neural network and using this model for sampling the examples for further manual annotation. We follow the active learning strategy and derive an Value of Information criterion to actively select candidate annotation images. During these iterations, the deep neural network is incrementally updated. Experimental results conducted on LFW benchmark and MS-Celeb-1M Challenge demonstrate the effectiveness of our proposed framework. Shanghai Advanced Research Institute, Chinese Academy of Sciences Hao Ye
Weiyuan Shao
Hong Wang
Yingbin Zheng
9 FutureWorld Huazhong University of Science and Thechology Zhang Chuan 10 1510 Learning an identity distinguishable space for large scale face recognition We firstly use a deep convolutional neural network (CNN) to optimize a 128-bytes embedding for large-scale face retrieval. The embedding is trained via using triplets of aligned face patches from FaceScrub and CASIA-WebFace datasets. Secondly, we leverage the evaluation of MSR Image Recognition according to a cross-domain retrieval scheme. To achieve real-time retrieval, we perform the k-means clustering on the feature space of training data. Furthermore, in order to learn a better similarity measure, we apply a large-scale similary learning on the relevant face images in every cluster. Compared with a lot of existing networks of face recognition, our model is lightweight and our retrieval method is also promising. Beijing University of Posts and Telecommunications; Jie Shao
Zhicheng Zhao
Fei Su
Zhu Meng
Ting Yue
11 BUPT_MCPRL Not Disclosed 12 CIIDIP Tsinghua University Yao Zhuliang
Chen Dangdang
Wang Zhongdao
Ge Yunxiang
Zhao Yali
13 CIGIT_NLPR Weakly Supervised Learning for Web-Scale Face Recognition We propose a weakly supervised learning framework for web-scale face recognition. In this framework, a novel constrained pairwise ranking loss is effectively utilized to help alleviate the adverse influence from noise data. We also design an online algorithm to select hard negative image triplets from weakly labeled datasets for model training. Experimental results on MS-Celeb-1M dataset show the effectiveness of our method. Chongqing Institute of Green and Intelligent Technology and Institute of Automation, Chinese Academy of Sciences Cheng Cheng
Junliang Xing
Youji Feng
Pengcheng Liu
Xiao-Hu Shao
Xiang-Dong Zhou
14 DRNfLSCR A possible solution for large scale classification problem. The celebrity recognition is treated as a classification problem. Our approach is based on the Deep Residual Network. All the models used in our system are the 18-layer model. The reason we choose this small model is we don’t have enough GPUs and time to use larger models which obviously will get better performance. The data is first randomly split into training set and validation set. The training set contains 90% of all data and the validation set has the rest 10%. We utilize two models to generate the final result. The first model gives 71% and 49.6% coverage@P=95 on the development random set and hard set, respectively. The second model gives about 56.6% and 36.6% coverage@P=95 on the development random set and hard set, respectively. Usually, multi-scale testing gives better results. Considering the speed, we use two-crop testing which only takes the center crop of the original and flipped image. The final output is a tricky fusion of the two models. Our final submission achieves 76.2% and 52.4% coverage@P=95 on the development random set and hard set, respectively. Northeast University, USA Yue Wu
YUN FU
15 UESTC_BMI UESTC, KB541. Feng Wang 16 ZZKDY ShanghaiTech Xu Tang 17 faceman In this challenge, we use a two-stage approach for the face identification task: data cleaning and multi-view deep model learning. Our approach has two stages. The first stage is data cleaning due to the noisy data in the training set. We first train a ResNet-50 model on the Webface dataset using a classification loss. The activations from the penultimate layer are extracted as the features of images from the MsCeleb dataset. For each person, we apply an outlier detection to remove the noisy data. Specifically, with the feature vector for each image in one class, we calculate the centre of the feature vectors and the Euclidean distance of each feature vector to the centre. Based on the distances, a fix proportion of images in each class are regarded as outliers and are excluded from the training set. The second stage is multi-view deep model learning. Due to the diversity of MsCeleb, we use three deep models which have different structures and loss functions, i.e., ResNet-18, ResNet-50 and GoogLeNet. The ResNet-50 and GoogLeNet are trained with a logistic regression loss, and the ResNet-18 is trained with a triplet loss. These models provides distinct features to better characterize the data distribution from different “views”. Then a 2-layer neural network, whose input is the concatenated features from the penultimate layers of the three deep models, is used to perform multi-view feature fusion and classification. Prediction results with top-5 highest probability is regarded as the final identification result. NUS Jianshu Li
Hao Liu
Jian Zhao
Fang Zhao
18 BUPT_PRIS We train a Lightened CNN network supervised by Joint identification-verification signals and propose a robust object function to deal with this challenge. The task of Recognizing One Million Celebrities in the Real World is not like traditional task, in which case there are a large set of training data and a large set of identities. To save training time and disk memory, we use a Lightened CNN network and the Joint identification-verification supervisory signals are used throughout the training stage. As known, there are some noise images and this can decrease the recognition capacity of our deep model. So we modify the object function to handle noise data. Then we use the 8M aligned images of 100k identities and train a 100k-way softmax classifier. Beijing University of Posts and Telecommunications Binghui Chen,
Zhiwen Liu,
Mengzi Luo
19 NII-UIT-KAORI Video Processing Lab – National Institute of Informatics, Japan
Multimedia Communications Lab – University of Information Technology, VNU-HCM, Vietnam
Duy-Dinh Le, National Institute of Informatics; Benjamin Renoust, National Institute of Informatics;
Vinh-Tiep Nguyen, University of Information Technology, VNU-HCM;
Tien Do, University of Information Technology, VNU-HCM;
Thanh Duc Ngo, University of Information Technology, VNU-HCM;
Shin’ichi Satoh, National Institute of Informatics;
Duc Anh Duong, University of Information Technology, VNU-HCM
20 ms3rz Institute of Software, Chinese Academy of Sciences; 21 IMMRSB3RZ Institute of Software, Chinese Academy of Sciences; liu ji
Lingyong Yan
22 faceless CQU chen guan hao 23 Paparazzi Not Disclosed Remarks:
- Empty cell means these information are requested to be undisclosed by the participants;
- Team affiliation and member list are provided by the participants. IRC organizing team doesn’t verify them.
-
6/17/2016 Evaluation Finished
The final evaluation has been finished on 6/17. Among the 19 registered teams, 14 teams have successfully finished the task during the evaluation time window. We are now calculating the coverage/precision numbers and will send them out shortly (by 6/21) after verification, together with the final ranks.
6/13/2016 Evaluation Started
Final evaluation started on 6/13, more than half of the teams have finished the first round of evaluation requests. Please keep your recognizer online, for extra verification/retry requests.
If your recognizer has encountered issues during the first round of evaluation. Please ping us for another round of request. We can send you up to 3 rounds of evaluation traffic, as long as time allows. But keep in mind, you can only choose one of the results for ranking. By default, we will use your last result.
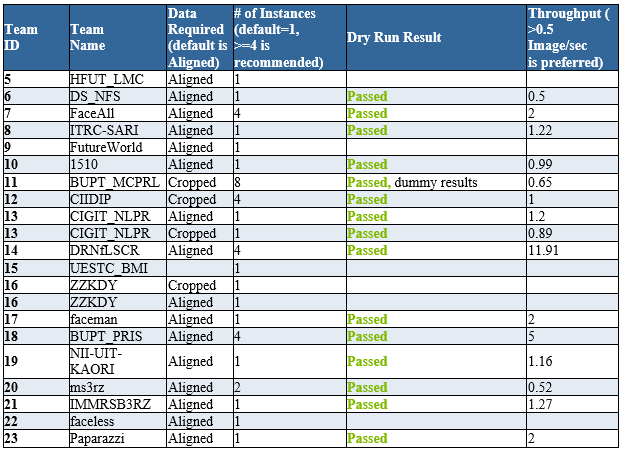
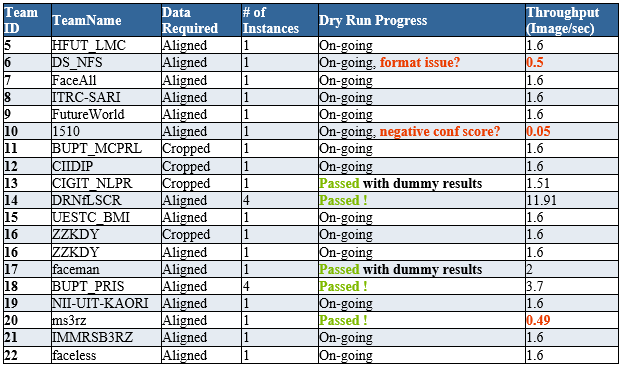
6/13/2016 Dry Run Update 4
14 out of 19 teams passed the connection, format and speed test within the dry run time window.
6/10/2016 Dry Run Update 3
One more team joined the competition, it is never too late to join IRCs.
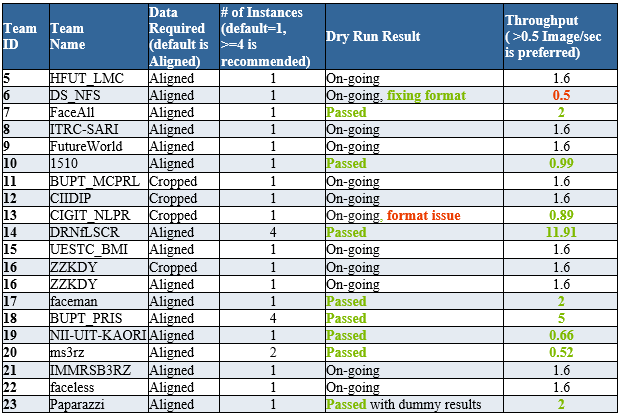
6/9/2016 Dry Run Update 2
More teams passed dry run (format, speed, and accuracy) and are ready for final evaluation. We are sending out the coverage/precision numbers to each passed team. Latest update about dry run progress is shown below.
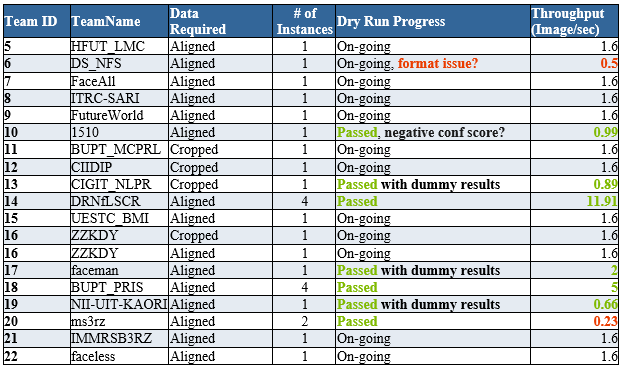
6/8/2016 Dry Run Update 1
There are 18 teams registered to IRC@MM16, from all over the world, including China, United States, Singapore, Japan, and etc.
We are conducting dry-run right now. I.e. sending the dev set data to all registered recognizers to measure their throughputs and accuracies. Here is the current progress:
- Format: Please double check your recognizer’s response and make sure they follow the format requirement, and there are no blank spaces, no LF/CR, no special characters in them.
- Speed: There will be around 50K images in the final evaluation. If your recognizer’s throughput is <0.5 image/sec, it will take > 1 day. I.e., you may not have enough time to finish the evaluation. So, Please consider either accelerating your recognizer (e.g. optimize the algorithm/code, run it on GPU), or simply start more recogServer instances to improve the overall throughput.
6/7/2016 Dry Run Started!
Dev data set is being sent to all recognizers in next several days. We will retry at 1 hour interval until all the images in dev set got recognized. Please keep your classifier running.
6/3/2016 Dry Run
IRC@MM16 dry run will start on June7 10AM (PST time) and last for several days if needed. The develop set will be sent to your recognizer to help you verify:
- Your recognizers are successfully connected to Prajna Hub and can response well: Please use the command line tool we shared with you earlier to test your recognizer and make sure it passed all the three steps;
- Your responses are in correct format: please carefully follow our instructions to format the recognition result string;
- The recognition accuracy are expected: we will send you the accuracy of dev set, measured by IRC Evaluation Service, which should be consistent to your local test result.
- The throughput of your system is more than 0.5 image/sec: Please keep in mind the final evaluation data will contain 50K test images. If your recognizer need more than 2 seconds to process an image (the command line tool shows the time cost), we suggest you to run multiple recognition server instances, to improve the overall throughput (our code will handle the load balance automatically);
- The stability of your system is good: during the dry-run, please keep an eye on the CPU/Memory/Disk consumption of your system and make sure they are stable enough, because the final evaluation will last several hours, or even several days.
- Most importantly, please let us know which data format your recognizer needs: (1) the cropped face images, or (2) the aligned face images. You can see “Data Download”section for their examples.
5/27/2016 Sample Code, GUIDs, Test Tool
As before, we will use an open multimedia hub (Prajna Hub) for evaluation. That is, you need to register your recognizer to Prajna Hub, which essentially turns your recognition program to a cloud service. Then your algorithm can be evaluated remotely.Note that your algorithm is still running on your local machine and you have full controls on it. This update provides:
- the Linux/Windows sample codes for you to connect your recognizer to Prajna Hub: download link (opens in new tab)
- two GUIDs to identify your team (providerGuid), and your recognizer (serviceGuid), see below.
- a command line tool to test your recognizer online, and the result format: download link (opens in new tab)
Detail Steps:
- The sample codes help you register your recognizer to Prajna Hub. Please refer to their readme files to choose the right way to integrate your recognizer, customize the sample codes as below to identify your team and recognizer, build and start it. Then you can use the tool described in next section to test the connection, before the dry-run started.

- Use the CommandLine tool to verify your recognizer (under Windows), please note that the serviceGuid below is specific for your recognizer, don’t change it or disclose it to others, before the evaluation is completed.
(1) ping IRC gateway, to verify it is up and running:
(2) ping the recognizer you registered in step#1:

You are expected to see the response like this: pinged xxxx and verified classifier xxxx is available, you can now send test request to it.
(3) send a single image and confirm the recognition response (format/value) is expected

You are expected to see the response in this format: Response: tag1:0.95;tag2:0.32;tag3:0.05;tag4:0.04;tag5:0.01
Please make sure that your recognition result string follow the format shown in the sample code: “tag1:0.95;tag2:0.32;tag3:0.05;tag4:0.04;tag5:0.01” , where
- Replace tag1,tag2…tag5 with the predicted celebrity label (FreeBase MID), which should be the same as the celebrity freeBase MIDs in MSCelebV1 dataset, we will use it to match the groundtruth;
- Replace the numbers after each tag with your prediction confidence;
- We will only evaluate (up to) the first 5 results for each image, please sort them by confidence score;If you have any questions, feel free to contact us. You can also refer to the FAQs for past IRCs for answers. We will work with you timely to solve the issues in registering your recognizers.
-
With the success of previous MSR Image Retrieval/Recognition Challenges (MSR IRC) at IEEE ICME, ACM Multimedia 2014 and 2015, Microsoft Research is happy to announce MSR IRC at ACM MM 2016, based on real world large scale dataset, and open evaluation system.
Thanks to the advance of deep learning algorithms, great progresses have been made in visual recognition in the past several years. But, there is still a big gap from these academic innovations and practical intelligent services, due to the lack of: (1) real world large scale data with better quality for training and evaluation. (2) public platform to conduct fair, efficient evaluations and make the recognition result reproducible and accessible.
To further motivate and challenge the academic and industrial research community, Microsoft is releasing MS-Celeb-1M, a large scale real world face image dataset to public, encouraging researchers to develop the best face recognition techniques to recognize one million people entities identified from Freebase. In its V1.0 version, the dataset contains 10M celebrity face images for the top 100K celebrities, which can be used to train and evaluate both face identification and verification algorithms.
Moreover, Microsoft Research has developed Prajna Hub, an open multimedia gateway, to convert latest algorithms into online services that can be accessed by anybody, from anywhere, and make the evaluation/test results repeatable and comparable.
By participating in this challenge, you can:
- Leverage real world large scale face dataset for celebrity recognition;
- Try out your image recognition system using real world data;
- See how it compares to the rest of the community’s entries;
- Get to be a contender for ACM Multimedia 2016 Grand Challenge;
-
This year we will focus on face recognition task. The contestants are asked to develop image recognition system based on, but not limited to, the datasets provided by the Challenge (as training data) to recognize 1M celebrities from their face images.
The 1M celebrities are obtained from Freebase based on their occurrence frequencies (popularities) on the web. Grounding the face recognition task to a knowledge base has many advantages. First, each people entity on Freebase is unique and clearly defined without disambiguation, making it possible to define such a large scale face recognition task. Second, each entity naturally has multiple properties (e.g. gender, date of birth, occupation), providing rich and valuable information for data collecting, cleaning, and multiple task learning.
The measurement set consists of 1000 celebrities sampled from the 1M celebrities, and for each celebrity we have manually labeled up to 20 images scrapped from commercial image search engines. But the identities of these 1000 celebrities will not be disclosed, so that the contestants cannot optimize just for these 1000 celebrities. To obtain high recognition recall and precision rates, the contestants will have to develop a recognizer to cover as many as possible celebrities, which will be of great value to help advance the state of the art in face recognition.
A contesting system is asked to produce 5 or less labels for a test image, ordered by confidence scores. Top one accuracies will be evaluated against a pre-labeled image dataset, which will be used during evaluation stage.
Note: Commercial/public intelligent services are not allowed to be called during the evaluation, e.g. Microsoft Cognitive Servcies, etc. We will detect and ban the contestants for this kind of behavior.
-
Guideline: You’re encouraged to build generic system for recognizing millions of people by face. The 1M celebrity names and about 10M face images with labels will be provided to the participants for data filtering and training. A development data set, which contains several hundreds of face images and ground truth labels will be provided to the participants for self-evaluations and verifications. Please note that above datasets are all optional to be used. That is, systems that based on MS-Celeb-1M and/or any other private/public datasets will all be evaluated for final award (as different tracks, if necessary), as long as the participants describe the datasets they have used.
Evaluation Metric: To match with real scenarios, we will measure the recognition recall at a given precision 95% (or 99% if there are a sufficient number of teams who can achieve this level of precision). That is, for N images in the measurement set, if an algorithm recognizes M images, among which C images are correct, we will calculate precision and recall as:
precision = C/M
coverage = M/N
By varying the recognition confidence threshold, we can determine the coverage when the precision is at 95%. Note that we also add distractor images to the measurement set. This will increase the difficulty of achieving a high precision, but is much closer to real scenarios.
Note: We will evaluate recognition algorithms on two different tracks:
For DevSet1, the face images with big variations are used intentionally, in order to test the robustness your algorithm on complex situations such as pose/age/resolution/special effects/etc.. This track encourages participants to develop robust algorithms with good generalization capability.
For DevSet2, the test images are randomly selected, which are highly likely to be covered by the training data, if that entity is covered. In this way, the overall coverage of your algorithm, i.e., how many entities your system can recognize, among the 1M entities, can be evaluated. This track encourages participants to collect and use as many as training data as possible, and focus on the scalabilities.
In summary here are the tables of the evaluation results:

Evaluation Platform: An open multimedia hub, Prajna Hub, will be used for the evaluation, which will turn your recognition program to a cloud service, so that your algorithm can be evaluated remotely. Similar methodology has been used in the last several IRCs and it was well-received. This time, we made it even easier, with extra bonus including:
- Your recognizer will be readily accessible by public users, e.g. web pages, mobile apps. But the core recognition algorithm will still be running on your own machine/clusters (or any other public clusters if preferred), so that you always have full controls;
- Sample codes for web/phone apps will also be available through open source, so that your recognition algorithms can be used across devices (PC/Tablet/Phone) and platforms (Windows Phone, Android, iOS). I.e., you will have a mobile app to demonstrate your face recognizer, but you won’t need to write mobile app codes or just need to make simple modifications.
- Sample codes will be provided to help participant to convert your existing recognition algorithms to a cloud service, which can be accessed from anywhere in the world, with load balance and geo-redundancy;
- The recognizer can run on either Windows or Linux platform.
-
The Challenge is a team-based contest. Each team can have one or more members, and an individual can be a member of multiple teams. No two teams, however, can have more than 1/2 shared members. The team membership must be finalized and submitted to the organizer prior to the Final Challenge starting date.
At the end of the Final Challenge, all entries will be ranked based on the metrics described above. The top three teams will receive award certificates. At the same time, all accepted submissions are qualified for the conference’s grand challenge award competition.
-
Please follow the guideline of ACM MULTIMEDIA 2016 Grand Challenge for the corresponding paper submission.
-
- March 19, 2016: details about evaluation announced/delivered
- March 31, 2016: MS-Celeb-1M.v1 ready for download
- June 7, 2016: Dry run starts (trial requests sent to participants)
- June 13, 2016: Evaluation starts (evaluation requests start at 8:00am PDT)
- June 17, 2016: Evaluation ends (5:00pm PDT)
- June 23, 2016: Evaluation results announced.
- July 6, 2016: Grand Challenge Paper and Data Submission deadline
- July 29, 2016: Notification of acceptance
- August 3, 2016, Camera-ready submission deadline
-
- Information about past IRCs: “MSR Image Retrieval Challenge (IRC)“
- Research paper about the dataset: “MS-Celeb-1M: Challenge of Recognizing One Million Celebrities in the Real World (opens in new tab)“
-
MsCeleb1M Grand Challenges are organized by :
- Yuxiao Hu, Microsoft Research
- Lei Zhang, Microsoft Research
- Yandong Guo, Microsoft Research
- Xiaodong He, Microsoft Research
- Jianfeng Gao, Microsoft Research
- Shiguang Shan, Chinese Academy of Sciences
-
Questions related to this challenge should be directed to:
- Yuxiao Hu (yuxiao.hu@microsoft.com), Microsoft Research
- Lei Zhang (leizhang@microsoft.com), Microsoft Research
- Yandong Guo (yag@microsoft.com), Microsoft Research
- Shiguang Shan (sgshan@ict.ac.cn), Chinese Academy of Sciences
-
Here are some frequently asked questions regarding IRC and clickture-dog data:
Q: Can I use ImageNet or other data for network pre-training?
A: Yes, you can use pre-trained CNN models (by ImageNet or other dataset), as long as you can fine tune that well to fit for the dog breed categories. Basically, we treat these pre-trained CNN models as feature extraction layer. Your system/algorithm output will be evaluated and compared with other team’s results.
But, if you use some data other than Clickture dataset as positive/negative examples during the training/tuning, please describe this clearly and notify us before the evaluation starts. Your algorithm/system will still be evaluated, we are considering to rank these systems in separate tracks for fairness.
Q: We found there are some noise/conflicting labels in Clickure-Dog dataset. Is this expected?
A: You may find that there are ~15K images appear in multiple dog breeds. The reason is as follows: we use the clicked queries as the “groundtruth” of dog breeds, but sometimes the same images are returned/clicked by multiple dog breed queries. We intentionally to NOT remove these 15K images from the data. Because we treat this as an important/interest topic to automatically remove the “wrong/conflicting” samples and keep the “correct” labels, during data collection and training.
Q: How is the evaluation data set constructed?
A: We extracted all the dog breeds that have matched names in
Q: How to extract the images and associating class labels from clickture_dog_thumb.tsv file?
A: For the Clickture-Dog dataset, there are 95119 lines in the clickture_dog_thumb.tsv files, each is a data sample. There are three columns (delimited by “\t”) in each line. A sample line from clickture_dog_thumb.tsv file is shown below:
affenpinscher /LUkKqfrtLwqEw /9j/4AAQSkZJRgABAQEAAAAAAAD/2wBDAAoHBwgHBgoICAgLCgoLDhgQDg0NDh0VFhEYIx8lJCI…
the first column (“affenpinscher”) is the dog breed label, If you count all the unique dog breed strings in the first column, there are 344 dog breeds in this Clickture-Dog dataset.
the second column (“/LUkKqfrtLwqEw”) is the unique key for this record (which can be used to locate the corresponded record in the Clickture-Full dataset).
the third column (“/9j/4AAQSkZJR…”) is the jpeg image encoded as base64, which can be saved to file by “File.WriteAllBytes (“Sample.jpg”, Convert.FromBase64String(ImageData))” in C#. You can also use this website (opens in new tab) to decode this base64Encoded image data and save it to a jpg file manually.
Q: We are trying to run the sample server on our Linux machine and we are getting an Unhandled System.TypeLoadException?
A: Please install FSharp first and give it a try again: “sudo apt-get install fsharp”. If it still doesn’t work, please run the program with: “MONO_LOG_LEVEL=debug mono [***the exe program***]” and send us all the output.
Q: We updated the sample code with team name and GUIDs, it compiled and started successfuly, we run the CommandLineTool to test it, both Ping and Check steps work well, butwe see “Error: Connected to Prajna Hub Gateway, but get empty response, please check classifier xxxx and its response format” when sending the Recog request in step 2.(3),
A: Please check:
-
- Use some network monitoring tool to check whether the CommandLineTool.exe send out the request. Since both 2.(1) and 2.(2) worked well, it is very unlikely that 2.(3) is blocked;
- Use some network monitoring tool to check whether your machine received the recognition request from the gateway, when you use 2.(3) to send the recognition. It is possible that your firewall blocked this incoming requests from Prajna Gateway;
- Put a break point in the PredictionFunc(), to see whether your classifier wrapper (the sample code) really received the request, and which exe or function (which should be your classifier) it called to recognizer the image, here you may have put a wrong exe file path, or your classifier DLL may have some issue, or you forgot to build the IRC.SampleRecogCmdlineCSharp.exe, which the sample code will call by default to return dummy results.
- If the image is sent to your classifier.exe, check your classifier side to see whether it get executed correctly and return the result string like “tag1:0.95;tag2:0.32;tag3:0.05;tag4:0.04;tag5:0.01”
Q: When we try to run the sample code on linux, we encountered error message containing: “Mono: Could not load file or assembly ‘FSharp.Core, Version=4.3.1.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a’ or one of its dependencies.”
A: For Linux/Ubuntu users, please follow the instructions we provided in the readme file to install the up-to-date version of mono and fsharp.
Please note that the sample code has to be run with the newest version of fsharp (4.3.1) . The default mono and fsharp packages you get from Ubuntu may not be up-to-date. Please follow the readme file provided with the sample codes to install the newest mono and fsharp package.
If you have already install the old version, please do the following to fix the problem.
sudo apt-get autoremove mono-completesudo apt-get autoremove fsharpsudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 3FA7E0328081BFF6A14DA29AA6A19B38D3D831EF echo "deb http://download.mono-project.com/repo/debian (opens in new tab) wheezy main" | sudo tee /etc/apt/sources.list.d/mono-xamarin.list sudo apt-get update esudo apt-get install mono-complete fsharp
Q: When we use CommandLineTest tool, we encountered error message when checking the the availability of our classifier:
Error: Connected to Prajna Hub Gateway vm-Hub.trafficManager.net, but get empty response, please check classifier 12345678-abcd-abcd-abcd-123456789abc and its response format.
A: Some teams confused serviceGuid with providerGuid, so they used the providerGuid to hit a classifier in step#2, which should be serviceGuid instead. ServiceGuid is used to identify your classifier, while providerGuid is used to identify your team. Please use the exact command lines we sent you in earlier email of update 3/3. No need to change anything.
step#2: CommandLineTool.exe Check -pHub vm-Hub.trafficManager.net -serviceGuid "GUID_Of_Your_Classifier" Step#3: CommandLineTool.exe Recog -pHub vm-Hub.trafficManager.net -serviceGuid "GUID_Of_Your_Classifier" -providerGuid "GUID_Of_Your_Team" -infile c:\dog.jpg
-
People
Jianfeng Gao
Technical Fellow & Corporate Vice President