

Mathematics
Gaussian Sampling over the Integers: Efficient, Generic, Constant-Time
Sampling integers with Gaussian distribution is a fundamental problem that arises in almost every application of lattice cryptography, and it can be both time consuming and challenging to implement. Most previous work has focused on…

Uniformization of distributional limits of graphs
Benjamini and Schramm (2001) showed that distributional limits of finite planar graphs with uniformly bounded degrees are almost surely recurrent. The major tool in their proof is a lemma which asserts that for a limit…

Accelerating Stochastic Gradient Descent
There is widespread sentiment that it is not possible to effectively utilize fast gradient methods (e.g. Nesterov’s acceleration, conjugate gradient, heavy ball) for the purposes of stochastic optimization due to their instability and error accumulation,…

Foundations of Optimization
Optimization methods are the engine of machine learning algorithms. Examples abound, such as training neural networks with stochastic gradient descent, segmenting images with submodular optimization, or efficiently searching a game tree with bandit algorithms. We…
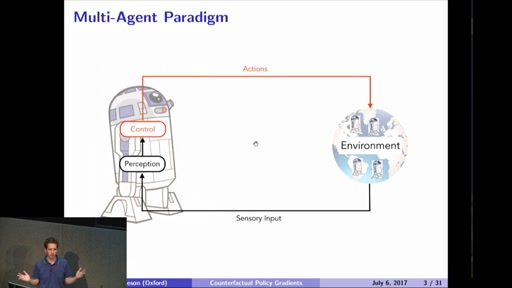
Counterfactual Multi-Agent Policy Gradients
Many real-world problems, such as network packet routing and the coordination of autonomous vehicles, are naturally modelled as cooperative multi-agent systems. In this talk, I overview some of the key challenges in developing reinforcement learning…
Policy Gradient Methods: Tutorial and New Frontiers
In this tutorial we discuss several recent advances in deep reinforcement learning involving policy gradient methods. These methods have shown significant success in a wide range of domains, including continuous-action domains such as manipulation, locomotion,…
