
This research was presented as a demonstration at the 40th IEEE International Conference on Data Engineering (opens in new tab) (ICDE 2024), one of the premier conferences on data and information engineering.

Since the inception of cloud computing, autoscaling has been an essential technique for optimizing resources and performance. By dynamically adjusting the number of computing resources allocated to a service based on current demand, autoscaling ensures that the service can handle the load efficiently while optimizing costs. However, developing and fine-tuning autoscaling algorithms, which govern this process, present significant challenges. The complexity and cost associated with testing these algorithms can lead to inefficient resource management and impede the development of more effective autoscaling strategies.
- Publication VASIM: Vertical Autoscaling Simulator Toolkit
In our paper, “VASIM: Vertical Autoscaling Simulator Toolkit,” presented at ICDE 2024, we introduce a tool designed to address the complexities involved in assessing autoscaling algorithms. While existing simulation tools cover a range of capabilities, such as energy efficiency and fault tolerance, VASIM stands out by evaluating the critical recommender component within the algorithm and suggesting optimal resource scaling actions based on usage data, balancing performance and cost. This enables developers to iterate more rapidly, enhancing algorithmic performance, and improving resource efficiency and cost savings.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
VASIM’s user-friendly interface simplifies the evaluation of autoscaling policies, as illustrated in Figure 1. First steps entail uploading historical data and defining autoscaling policies, including the algorithm and its parameters, shown in the left panel. The Simulation Run feature enables the modification of algorithm parameters, imported via a configuration file, and the execution of simulations based on the selected trace. A results screen displays the CPU limits determined by the selected policies as well as the actual CPU usage tailored to these limits. Additionally, VASIM provides fundamental metrics like throttling incidents, number of scaling operations, and amount of unused capacity, or slack, for the current simulation.
![[On the left] Image of VASIM user interface. On the left panel, it has options to select from “Simulation Run”, “Simulation Tuning”, “Simulation Tuning History”. Option “Simulation Run” is selected. Below user has loaded a trace from csv file on disk (c_26742_perf_event_log.csv), algorithm C, metadata config json file from disk. Button “Visualize workload” was clicked and loaded trace is displayed.
[On the right] On the right panel, user picked other parameters for simulation run (lag – how often recommender gives decision and initial core count) and algorithm parameter from json are shown for edit.
Image of VASIM UI when simulation was run for selected algorithm, trace and parameter setting. It shows a graph with cpu usage in blue and the limit calculated by selected algorithm in red. It is different from the trace plot that was shown before because calculated limits were below cpu utilization, so the latter was cut off. On top of the plot it shows metrics of the simulation like average slack, average insufficient CPU, sum slack, sum insufficient CPU, number of scalings, number of times of insufficient CPU etc.](https://www.microsoft.com/en-us/research/uploads/prodnew/2024/04/VASIM_Fig1.png)
VASIM achieves several important goals:
Resource efficiency and cost reduction. VASIM reduces costs by removing the need to test scaling operations in real-time, which would be resource intensive. This enables developers to adjust algorithms iteratively in a controlled, cost-efficient environment, accelerating development cycles. Because the tool allows users to upload CPU performance history and algorithm parameters, it delivers the results of scaling operations across the entire workload in minutes rather than hours.
Multi-objective optimization. It’s challenging to develop an autoscaling method that handles conflicting parameters. VASIM makes this easier by applying Pareto optimization techniques (opens in new tab), helping developers to find a balance among key metrics. Figure 2 depicts scatter plots for two metrics: average slack and average insufficient CPU. It also shows three optimization objectives: the optimal amount of slack, throttling, and number of scaling operations.
![[On the left] A graph that plots the average slack on the Y axis and the average insufficient cpu on the X axis. It shows that the more average insufficient cpu decreases, the more average slack increases. There are six points in red that are pareto frontier points, all on the very edge of the graph but not too close to each other, showing some possible choices of configuration.
[On the right] A 3D scatter plot displays the total slack on the X axis, cpu total throttle on the Y axis, and the amount of scalings in Z axis. It shows that as you aim to lower total slack and throttle, the amount of scalings increases.](https://www.microsoft.com/en-us/research/uploads/prodnew/2024/04/VASIM_Fig2.png)
Recommender algorithm testing. VASIM simplifies the process of testing and evaluating recommendation algorithms across diverse workloads. With all tuning jobs running in parallel, computation occurs more quickly, allowing users to efficiently adjust their recommender parameters as necessary. To assess the algorithm’s generalizability, we ran VASIM against 11 available open cluster traces (opens in new tab) for benchmarking and internal product workload traces. This enabled us to evaluate the algorithms’ robustness across a variety of workload types, including cyclical, bursty, and monotonic variations, demonstrating their reliability across different scenarios.
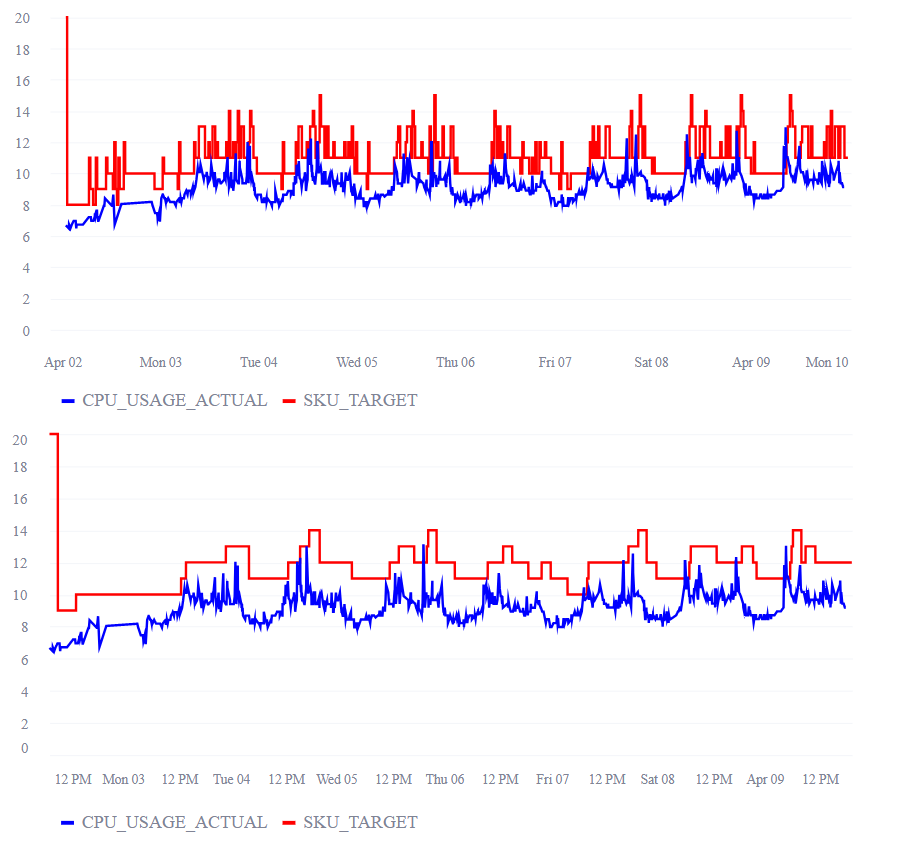
Versatility and adaptability. VASIM provides users with the flexibility to modify components, experiment with recommendation strategies, and evaluate the impact of changes in a controlled and customizable environment. Figure 3 shows the results of a simulation run on the same algorithm and historical performance data but with different parameters. This versatility ensures that infrastructure engineers can tailor the system to meet their needs, enhancing the overall effectiveness of their autoscaling strategies.
Optimizing scalability and costs in Kubernetes environments
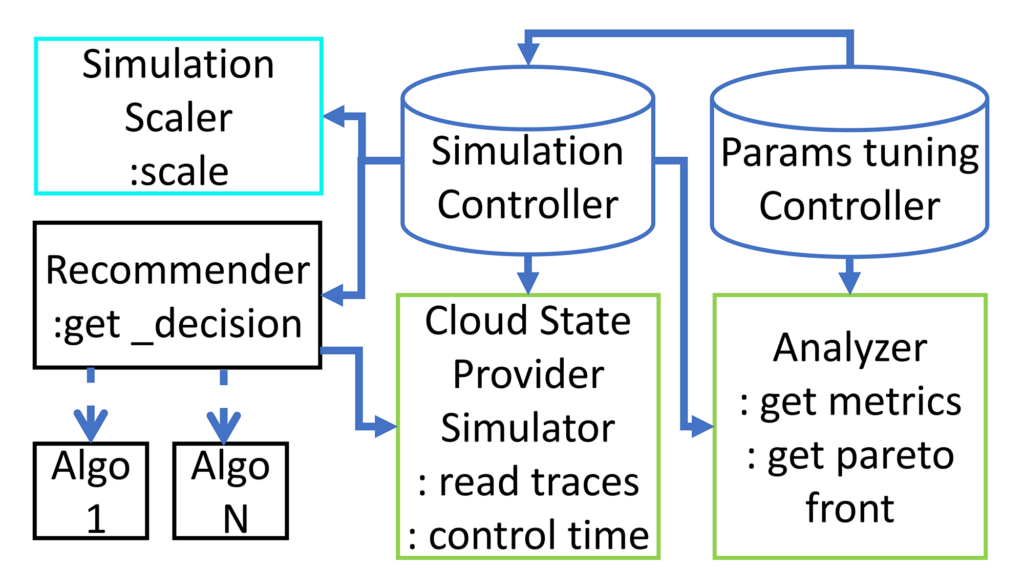
Our research on vertically autoscaling monolithic applications with a container-as-a-service algorithm (opens in new tab) helped us to better understand the tradeoffs between cost and availability that different algorithm variations introduce. Because VASIM is similar to standard autoscaling architecture (as in the Kubernetes Vertical Pod Autoscaler (opens in new tab) [VPA]) it allows us to test autoscaling algorithms for pods, applications, and virtual machine (VM) capacity. This is possible because these systems share similar components, including resource updaters, controllers, and recommenders. Despite differences in specific systems, their underlying architectures are sufficiently similar, enabling VASIM to effectively mimic them, as shown in Figure 4.
Implications and looking ahead
Looking forward, we plan to broaden the scope of VASIM’s support beyond just CPUs to include a wide range of resources, such as memory, disk I/O, and network bandwidth. This expansion will provide future users with a comprehensive understanding of system performance and enable them to make more accurate decisions regarding system management and resource optimization. Additionally, a deeper understanding of system performance will help inform proactive optimization strategies focused on maximizing system efficiency and performance.



