

At a glance
- Problem: Adapting large language models to specialized, high-stakes domains is slow, expensive, and hard to reproduce.
- What we built: AutoAdapt automates planning, strategy selection (e.g., RAG vs. fine-tuning), and tuning under real deployment constraints.
- How it works: A structured configuration graph maps the full scope of the adaptation process, an agentic planner selects and sequences the right steps, and a budget-aware optimization loop (AutoRefine) refines the process within defined constraints.
- Why it matters: The result is faster, automated, more reliable domain adaptation that turns weeks of manual iteration into repeatable pipelines.
Deploying large language models (LLMs) in real-world, high-stakes settings is harder than it should be. In high-stakes settings like law, medicine, and cloud incident response, performance and reliability can quickly break down because adapting models to domain-specific requirements is a slow and manual process that is difficult to reproduce.
The core challenge is domain adaptation, which entails turning a general-purpose model into one that consistently follows domain rules, draws on the right knowledge, and meets constraints such as latency, privacy, and cost. Today, that process typically involves guesswork, choosing among approaches like retrieval-augmented generation (RAG) and fine-tuning, tuning hyperparameters, and iterating through evaluations with no clear path to a good outcome. An operations team responding to an outage can’t afford a model that drifts from domain requirements or a tuning process that takes weeks with no guarantee of a reproducible result.
To tackle this, we’re pleased to introduce AutoAdapt. In our paper, “AutoAdapt: An Automated Domain Adaptation Framework for Large Language Models,” we describe an end-to-end, constraint-aware framework for domain adaptation. Given a task objective, available domain data, and practical requirements like accuracy, latency, hardware, and budget, AutoAdapt plans a valid adaptation pipeline, selecting among approaches like RAG and multiple fine-tuning methods, and tunes key hyperparameters using a budget-aware refinement loop. The result is an executable, reproducible workflow for building domain-ready models more quickly and consistently, helping make LLMs dependable in real-world settings.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
How it works
AutoAdapt starts from a practical observation: teams don’t just need a better prompt or more data, they need a decision process that reliably maps a task, its domain data, and real constraints to an approach that works. To do this, AutoAdapt treats domain adaptation as a constrained planning problem. Given an objective provided in natural language, dataset size and format, and limits on latency, hardware, privacy, and cost, it provides an end-to-end pipeline that teams can execute and deploy.
Domain adaptation often feels like trial and error because the design space is large and complex. Teams must choose among approaches such as RAG, supervised fine-tuning, parameter-efficient methods (such as LoRA), and alignment steps, each with many hyperparameters. These choices interact in nonobvious ways, and not all combinations are valid, making it difficult to identify a reliable strategy. The problem is compounded by the high cost of LLM training, which limits how many configurations can be explored.
AutoAdapt addresses this with the Adaptation Configuration Graph (ACG), a structured representation of the system’s configuration space that enables efficient search while guaranteeing valid pipelines.
Building on the ACG, AutoAdapt uses a planning agent to make and justify decisions. It proposes strategies, evaluates them against user requirements, and iterates until the plan is feasible and well-grounded. Rather than optimizing in an unconstrained black box, AutoAdapt roots each decision in best practices and explicit constraints, producing an executable workflow with parameter ranges.
Finally, AutoAdapt introduces AutoRefine, a budget-aware refinement loop that optimizes hyperparameters by strategically selecting which experiments to run next, even under limited feedback. AutoRefine replaces weeks of manual tuning with a more disciplined, reproducible process that is easier to audit and compare across projects. In real-world systems such as healthcare documentation, legal workflows, or incident response, this level of rigor is essential. Figure 1 illustrates the end-to-end workflow.
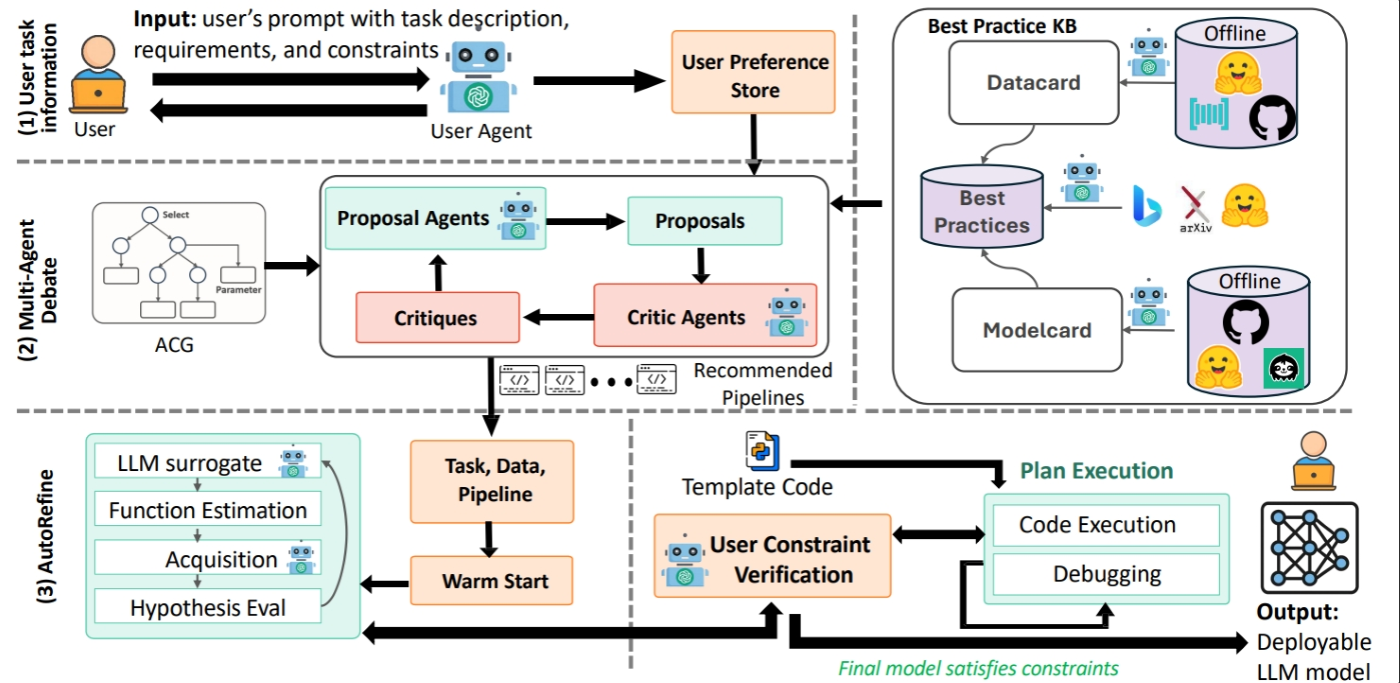
Evaluation
In experiments, AutoAdapt consistently identifies effective adaptation strategies and delivers improvements across a range of benchmark and real-world tasks, including reasoning, question answering, coding, classification, and cloud-incident diagnosis. It uses constraint-aware planning and budgeted refinement to find better-performing configurations with minimal added time and cost, making the process practical for production teams. Figures 2 and 3 show aggregate performance against competitive baselines.
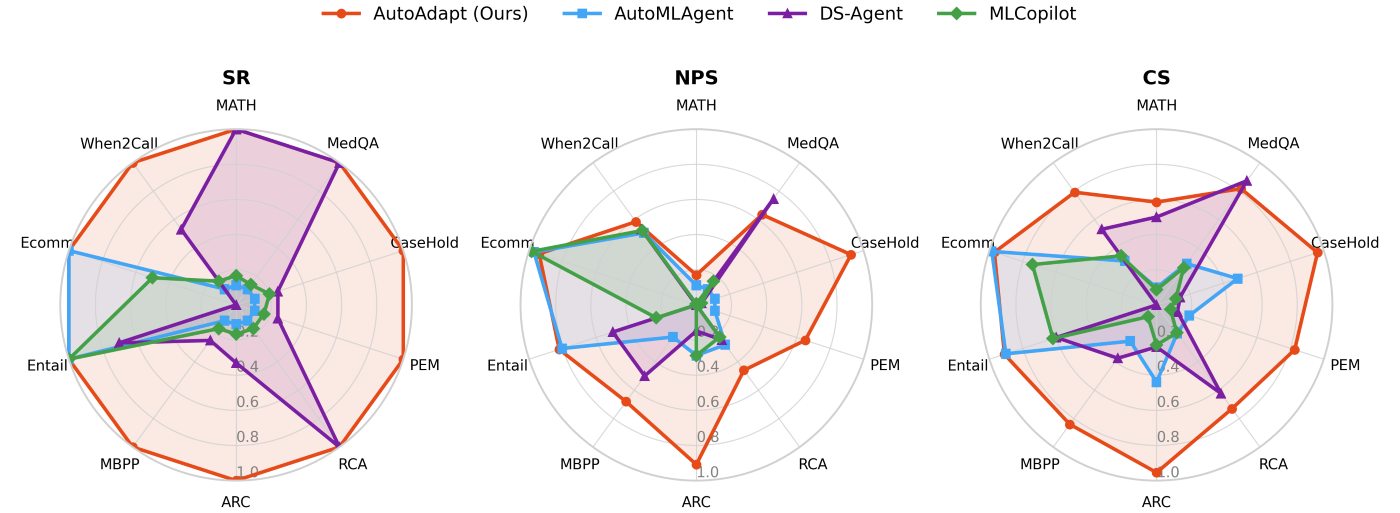
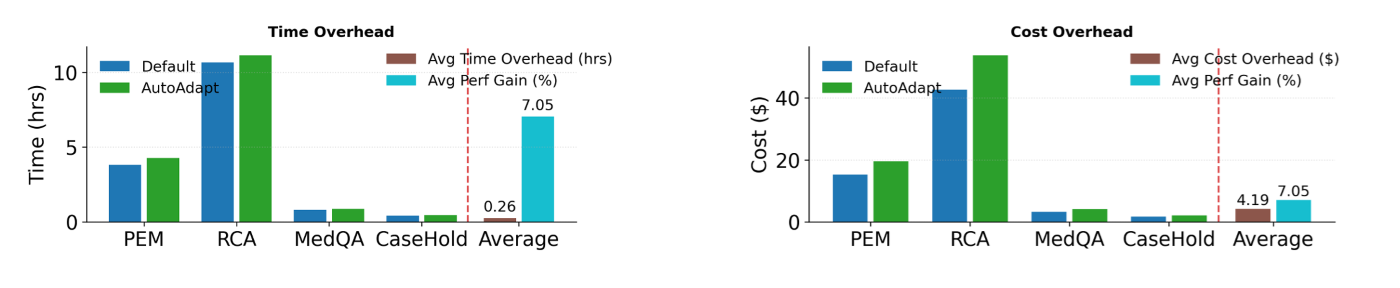
Implications and looking forward
The broader significance of AutoAdapt is that domain adaptation can become an engineering discipline, not an ad hoc process. By making key choices explicit—what to adapt, how to adapt it, and which constraints the system must satisfy—AutoAdapt helps teams reach results faster, reproduce them more easily, and audit them more rigorously. This shift is especially important in domains where drift from pretrained knowledge is common and failures are costly. When LLMs are used to draft clinical notes, triage support incidents, or summarize regulatory language, organizations need a clear, repeatable path from data to models that behave predictably under latency, privacy, and budget requirements.
Because domain adaptation is a prerequisite for deploying LLMs in real-world settings, we’re making the AutoAdapt framework open source (opens in new tab) to give teams a concrete starting point. The README (opens in new tab) file provides installation and quick-start instructions.