Large AI models are transforming the digital world. Generative language models like Turing-NLG, ChatGPT, and GPT-4, powered by large language models (LLMs), are incredibly versatile, capable of performing tasks like summarization, coding, and translation. Similarly, large multimodal generative models like DALL·E, Microsoft Designer, and Bing Image Creator can generate art, architecture, videos, and other digital assets, empowering content creators, architects, and engineers to explore new frontiers of creative productivity.
However, training these large models requires considerable memory and computing resources across hundreds or even thousands of GPU devices. For instance, training the Megatron-Turing NLG 530B model utilized over 4,000 NVidia A100 GPUs. Efficiently leveraging these resources requires a complex system of optimizations to partition the models into pieces that fit into the memory of individual devices, and to efficiently parallelize the computing across these devices. At the same time, to make large model training easily accessible to the deep learning community, these optimizations must be easy to use.
- Tutorials DeepSpeed ZeRO tutorials
The ZeRO family of optimizations (opens in new tab) from DeepSpeed offers a powerful solution to these challenges, and has been widely used to train large and powerful deep learning models TNLG-17B, Bloom-176B, MPT-7B, Jurrasic-1, etc. Despite its transformative capabilities, there are critical scenarios where ZeRO incurs high data transfer overhead across GPUs, making it challenging to achieve high training efficiency. This happens specifically when a) training on a large number of GPUs relative to the global batch size, which results in small per-GPU batch size, requiring frequent communication, or b) training on low-end clusters, where cross-node network bandwidth is limited, resulting in high communication latency. In these scenarios, ZeRO’s ability to offer accessible and efficient training is limited.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
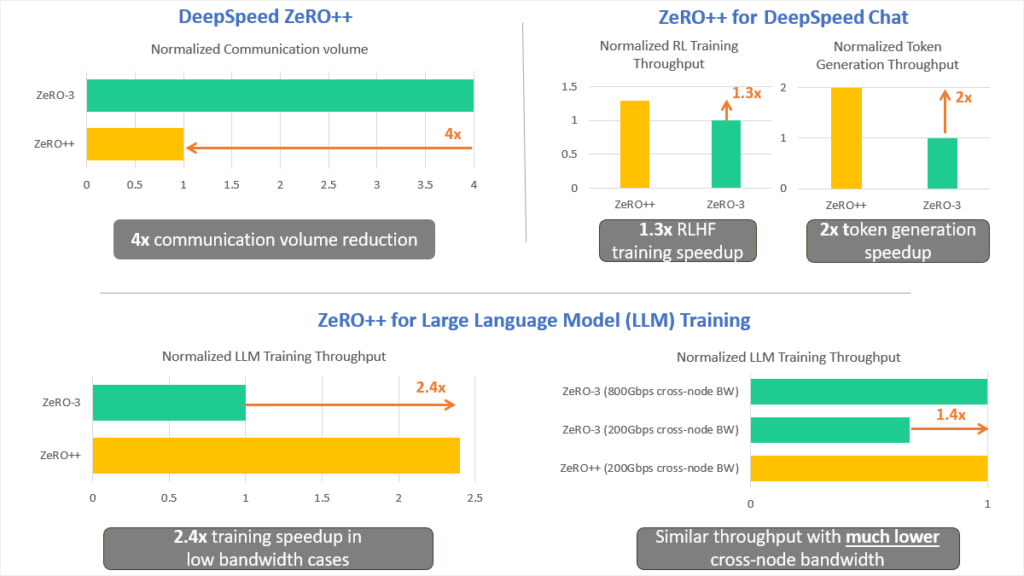
To address these limitations, we are releasing ZeRO++, a system of communication optimization strategies built on top of ZeRO to offer unmatched efficiency for large model training, regardless of batch size limitations or cross-device bandwidth constraints. ZeRO++ leverages quantization, in combination with data, and communication remapping, to reduce total communication volume by 4x compared with ZeRO, without impacting model quality. This has two key implications:
- ZeRO++ accelerates large model pre-training and fine-tuning
- Small batch-size per GPU: Whether pre-training large models on thousands of GPUs or fine-tuning them on hundreds or even dozens of GPUs, when batch-size per GPU is small, ZeRO++ offers up to 2.2x higher throughput compared to ZeRO, directly reducing training time and cost.
- Low-bandwidth clusters: ZeRO++ enables low-bandwidth clusters to achieve similar throughput as those with 4x higher bandwidth. Therefore, ZeRO++ makes efficient large model training accessible across a wider variety of clusters.
- ZeRO++ accelerates ChatGPT-like model training with RLHF
While ZeRO++ was designed primarily for training, its optimizations automatically also apply to ZeRO-Inference (opens in new tab), as the communication overheads are common to training and inference with ZeRO. Consequently, ZeRO++ improves efficiency of workloads like reinforcement learning from human feedback (RLHF) used in training dialogue models, which combines both training and inference.
Through integration with DeepSpeed-Chat (opens in new tab), ZeRO++ can improve the generation phase of RLHF training by up to 2x and reinforcement learning training phase by up to 1.3x compared to original ZeRO.
Next, we’ll take a deeper dive into ZeRO and its communication overheads and discuss the key optimizations in ZeRO++ for addressing them. Then we’ll demonstrate the impact of ZeRO++ on training throughput for different model sizes, batch sizes, and bandwidth constraints. We’ll also discuss how ZeRO++ applies to DeepSpeed-Chat for accelerating the training of dialogue models using RLHF.
Deep dive into ZeRO++
ZeRO is a memory efficient variation of data parallelism where model states are partitioned across all the GPUs, instead of being replicated, and reconstructed using gather/broadcast-based communication collectives on the fly during training. This allows ZeRO to effectively leverage the aggregate GPU memory and compute across all devices, while offering simplicity and ease-of-use of data-parallel training.
Assume the model size as M. During the forward pass, ZeRO conducts all-gather/broadcast operations to collect parameters for each model layer right before it is needed (in total of size M). In the backward pass, ZeRO adopts a similar communication pattern for parameters at each layer to compute its local gradients (in total of size M). In addition, ZeRO averages and partitions each local-gradient immediately after it is computed using a reduce or reduce-scatter communication collective (in total of size M). In total, ZeRO has a communication volume of 3M, spread evenly across two all-gather/broadcast and one reduce-scatter/reduce operation.
To reduce these communication overheads, ZeRO++ has three sets of communication optimizations, targeting each of the above-mentioned three communication collectives, respectively:
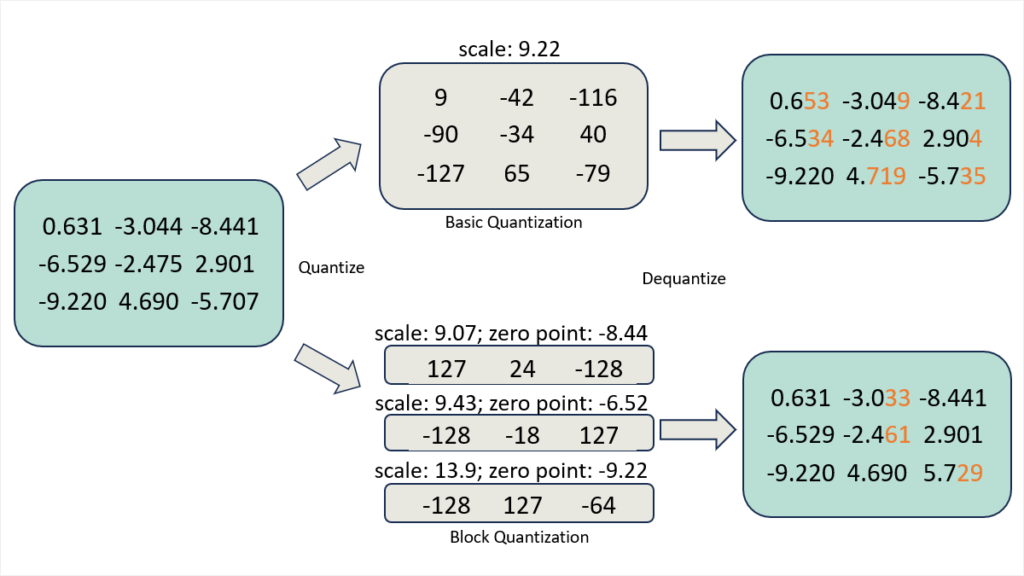
Quantized weight communication for ZeRO (qwZ)
First, to reduce parameter communication volume during all-gather, we adopt quantization on weights to shrink down each model parameter on the fly from FP16 (two bytes) to INT8 (one byte) data type before communicating, and dequantize weights after the communication. However, naively conducting quantization on weights may reduce model training accuracy. To preserve decent model training precision, we adopt block-based quantization, which conducts independent quantization on each subset of model parameters. There is no existing implementation for high performance, block-based quantization. Thus, we implement highly optimized quantization CUDA kernels from scratch that is 3x more accurate and 5x faster compared with basic quantization.
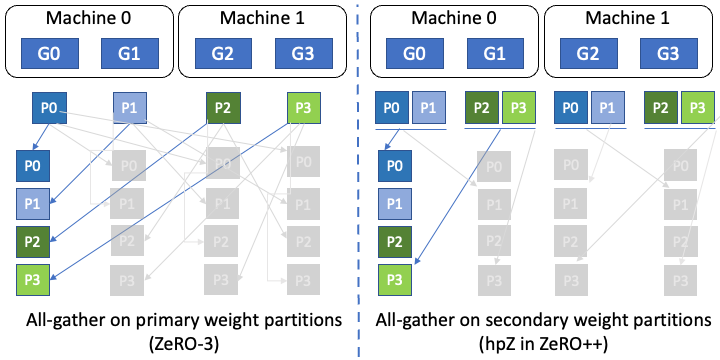
Hierarchical weight partition for ZeRO (hpZ)
Second, to reduce communication overhead of all-gather on weights during backward pass, we trade GPU memory for communication. More specifically, instead of spreading whole model weights across all the machines as in ZeRO, we maintain a full model copy within each machine. At the expense of higher memory overhead, this allows us to replace the expensive cross-machine all-gather/broadcast on weights with intra-machine all-gather/broadcast, which is substantially faster due to much higher intra-machine communication bandwidth.
Quantized gradient communication for ZeRO (qgZ)
Third, reducing communication cost of gradients using reduce-scatter is even more challenging. Directly applying quantization to reduce communication volume is infeasible. Even if we incorporate block-based quantization as low-precision, the gradient reduction accumulates and amplifies quantization error. To address this, we only quantize gradients before communication, but dequantize them to full precision before any reduction operation. To do this efficiently, we invented an all-to-all-based, novel quantized gradient communication paradigm called qgZ, which is functionally equivalent to compressed reduce-scatter collective operation.
qgZ is designed to solve two challenges: i) overcome significant accuracy loss that would result from low-precision reduction if we were to simply implement reduce-scatter in INT4/INT8, and ii) avoid accuracy degradation and significant latency overhead that would result from a long sequence of quantization and dequantization steps that would be needed by traditional approach to reduce-scatter that are ring- or tree-based, even if we did the reductions in full-precision. Instead of using a ring- or tree-based reduce-scatter algorithm, qgZ is based on a novel hierarchical all-to-all approach.
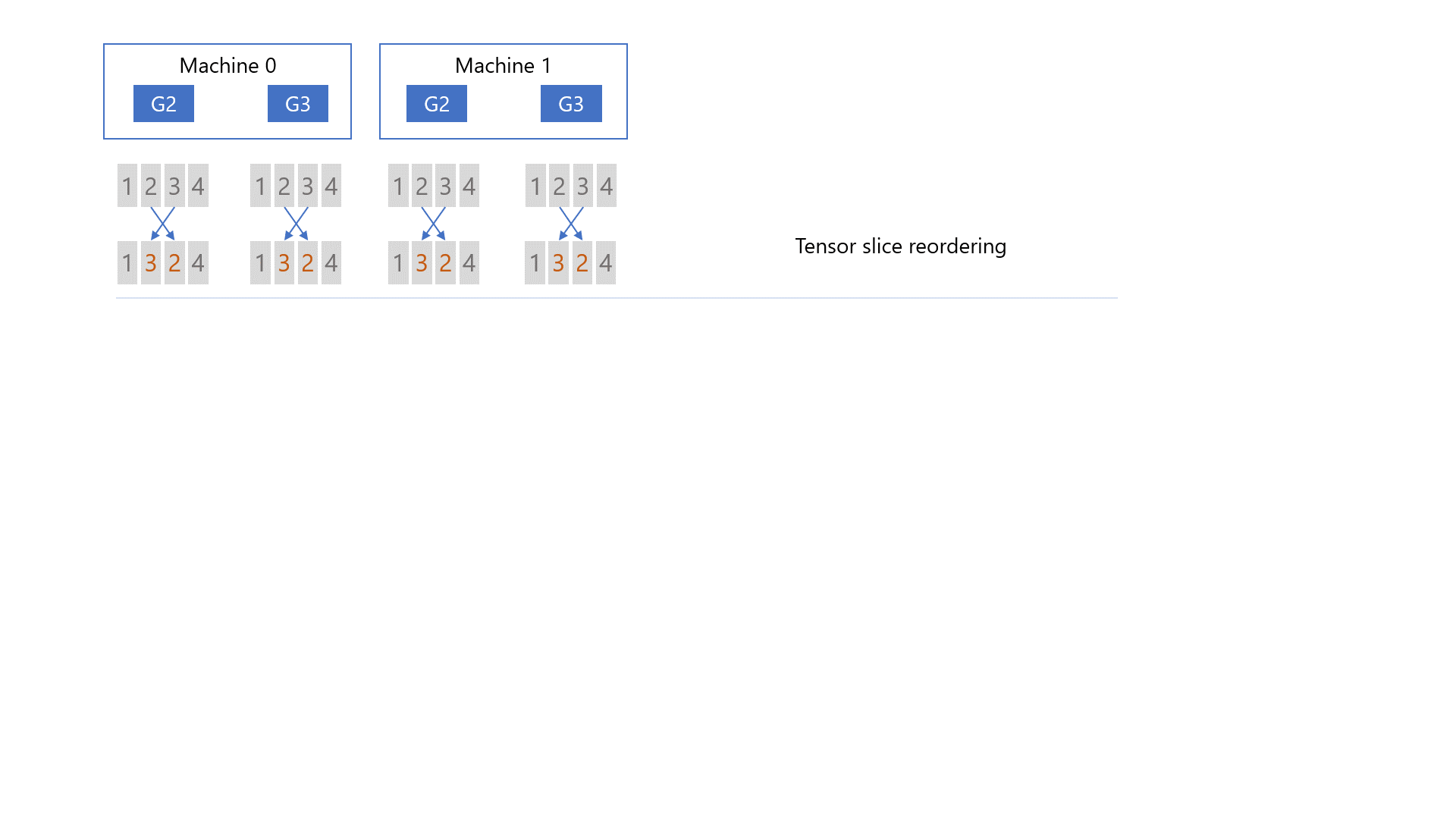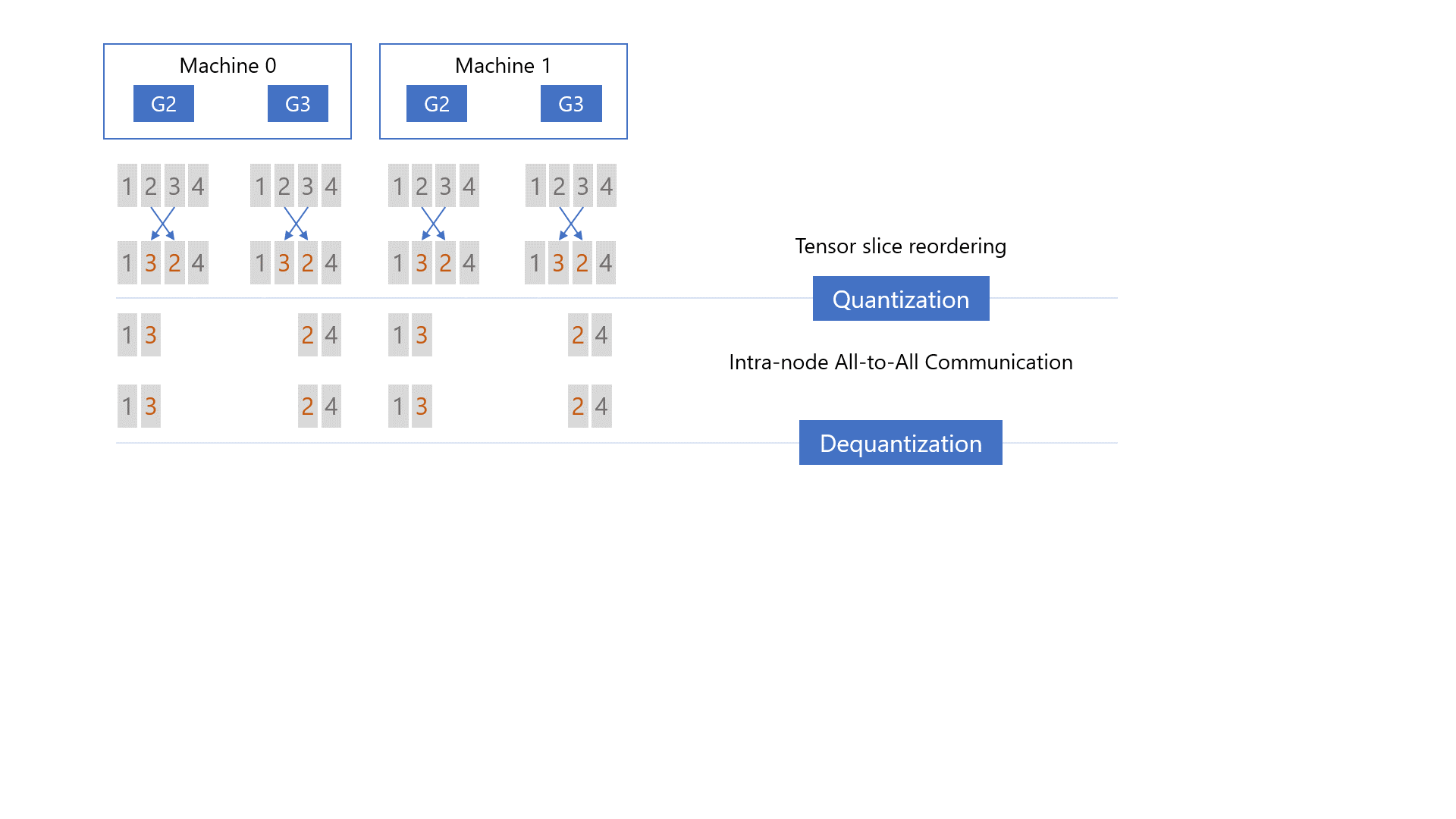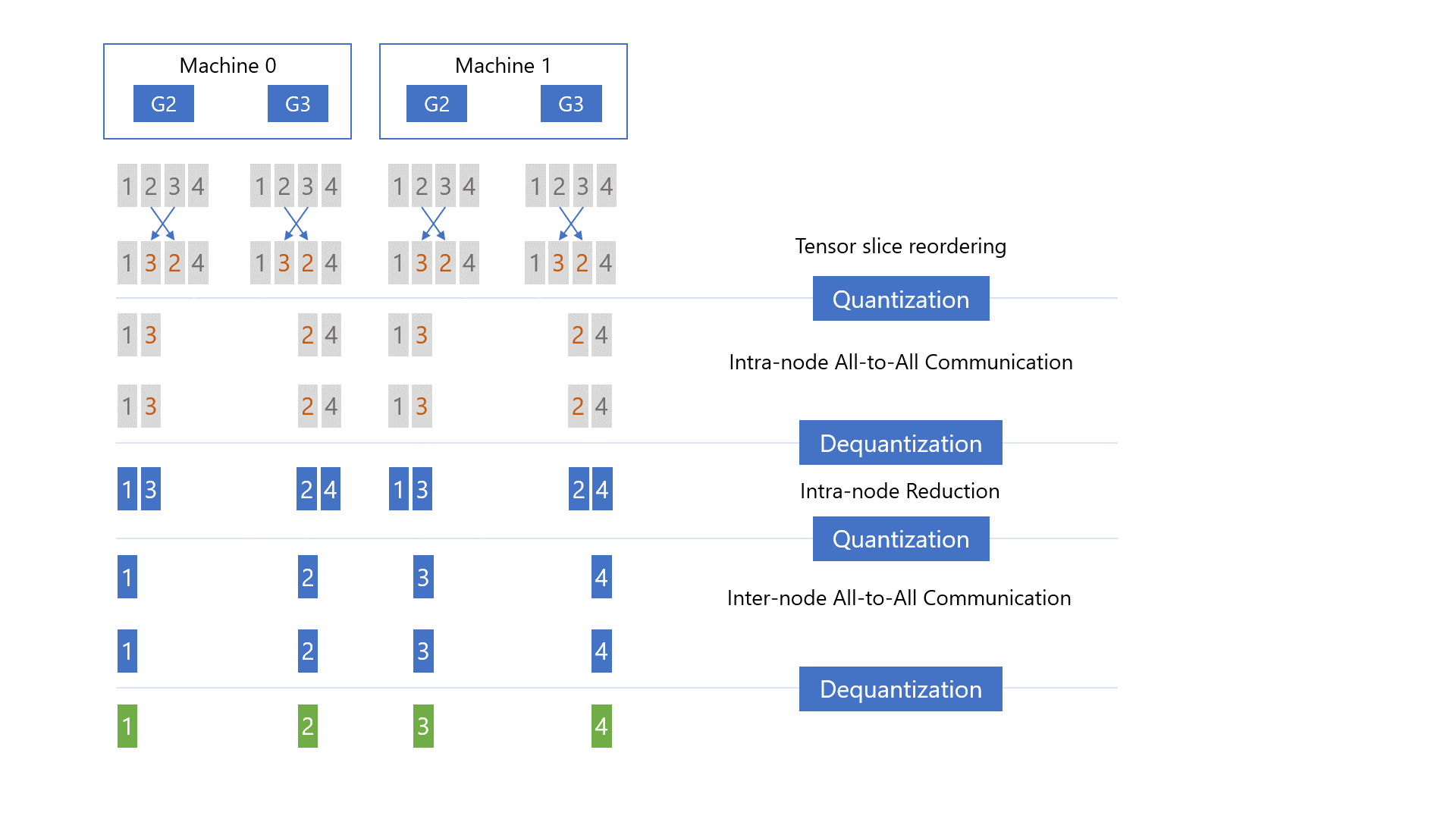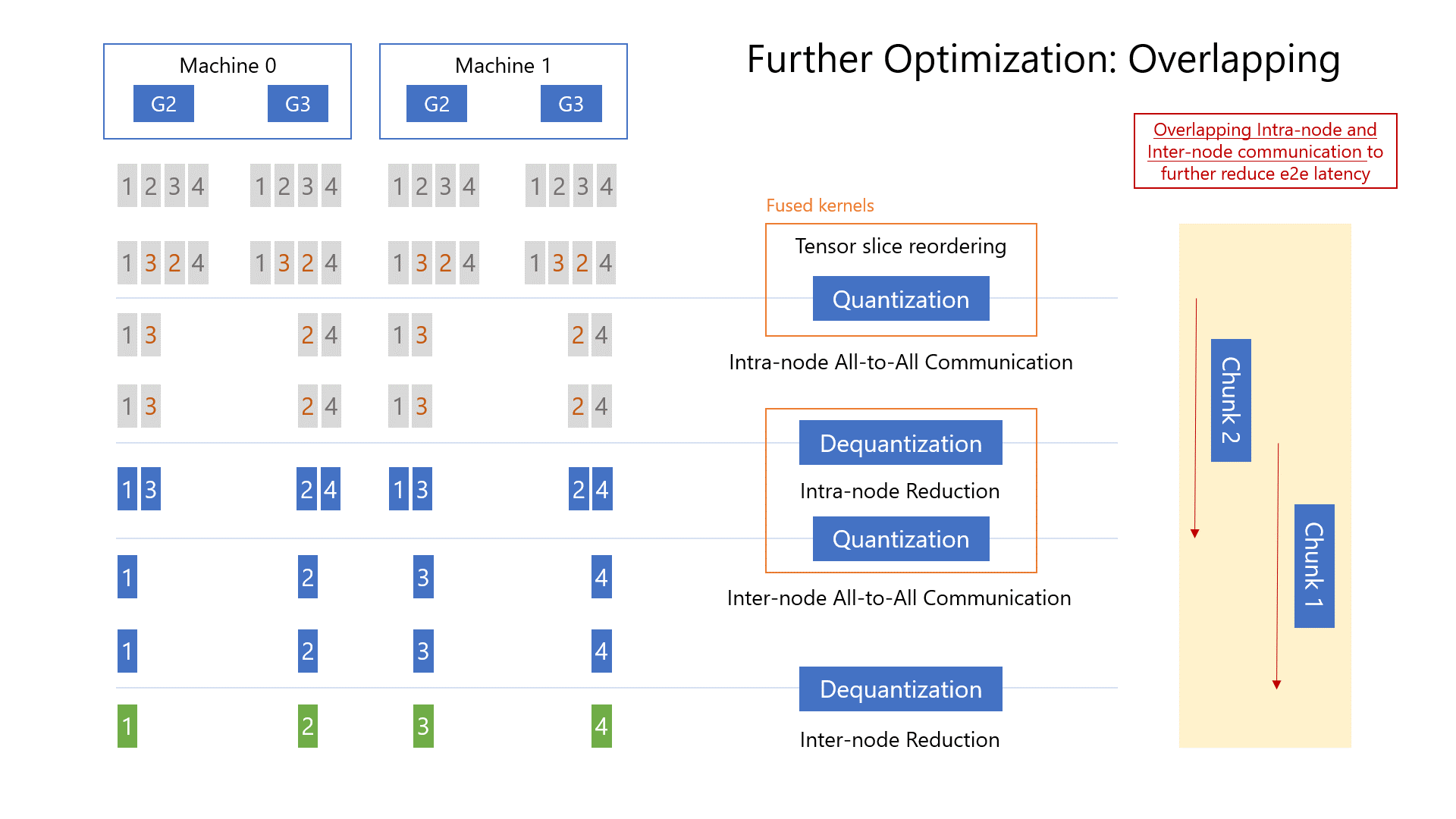
There are three major steps in qgZ: i) gradient slice reordering, ii) intra-node communication and reduction, and iii) inter-node communication and reduction. First, before any communication happens, we slice the gradient and do tensor slice reordering to guarantee the final gradient placement (i.e., green chunks in Figure 5) is correct on each GPU at the end of the communication. Second, we quantize the reordered gradient slices, conduct all-to-all communication within each node, dequantize the received gradient slices from the all-to-all, and do local reductions. Third, we quantize the local reduced gradients again, conduct inter-node all-to-all communication, dequantize the received gradients again, and compute the final high-precision gradient reduction to get the results as green chunks in Figure 5.
The reason for this hierarchical approach is to reduce cross-node communication volumes. More precisely, given N GPUs per node, model size of M and quantization ratio of Z, single hop all-to-all will generate M*N/Z cross-node traffic. In comparison, with this hierarchical approach, we reduce the cross-node traffic of each GPU from M/Z to M/(Z*N). Thus, the total communication volume is reduced from M*N/Z to M*N/(Z*N) = M/Z. We further optimize end-to-end latency of qgZ by overlapping intra-node and inter-node communication as well as fusing the CUDA kernel for (tensor slice reordering + intra-node quantization) and (intra-node dequantization+ intra-node reduction + inter-node quantization).
| Communication Volume | Forward all-gather on weights | Backward all-gather on weights | Backward reduce-scatter on gradients | Total |
| ZeRO | M | M | M | 3M |
| ZeRO++ | 0.5M | 0 | 0.25M | 0.75M |
Communication volume reduction
By incorporating all three components above, we reduce the cross-node communication volume from 3M down to 0.75M. More specifically, we reduce forward all-gather/broadcast on model weights from M to 0.5M using qwZ. We eliminate the cross-node all-gather during backward propagation using hpZ, reducing the communication from M to 0. Finally, we reduce cross-node reduce-scatter communication during backward-pass from M to 0.25M using qgZ.
ZeRO++ accelerates LLM training
Here we show our evaluation results of ZeRO++ with real-world LLM training scenarios in 384 Nvidia V100 GPUs.
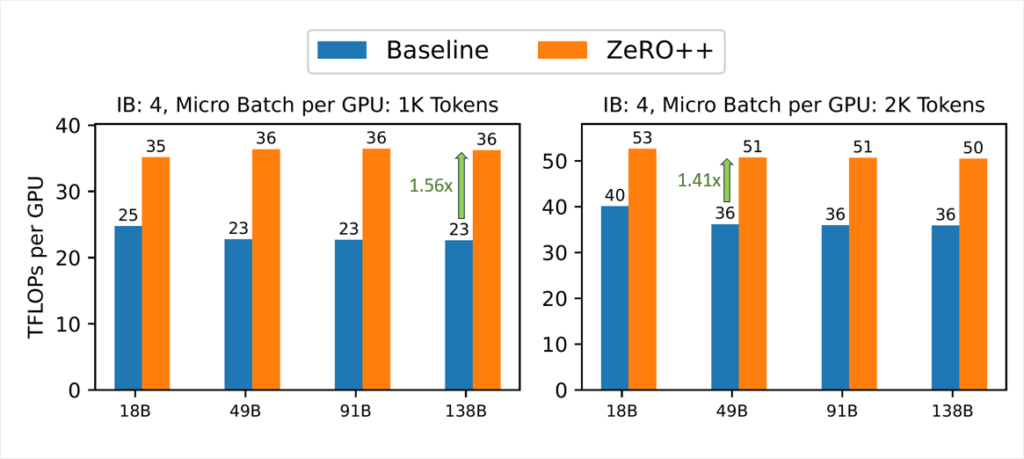
High efficiency with small batch per-GPU
High-bandwidth cluster: As shown in Figure 6, we first show ZeRO++ throughput improvement over ZeRO for different model sizes and micro batch sizes with 400Gbps cross-node interconnects using 4x Infiniband (IB), each running at 100Gbps. With 1k token per GPU, ZeRO++ achieves 28% to 36% throughput improvement over ZeRO-3. For 2k micro batch sizes, ZeRO++ achieves 24% to 29% throughput gain over ZeRO-3.
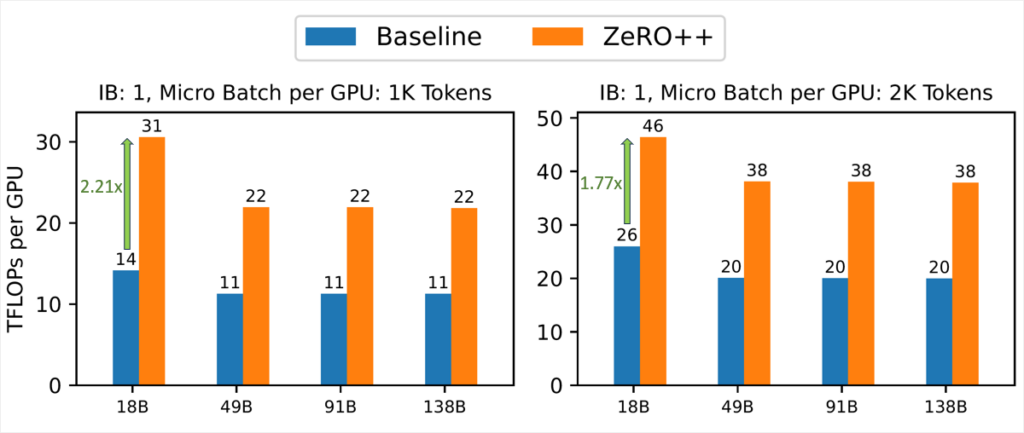
Low-bandwidth cluster: In low network environments like a 100Gbps network, ZeRO++ performs significantly better than ZeRO-3. As shown in Figure 7, ZeRO++ achieves up to 2.2x speedup in end-to-end throughput, compared to ZeRO-3. On average, ZeRO++ achieves around 2x speedup over ZeRO-3 baseline.
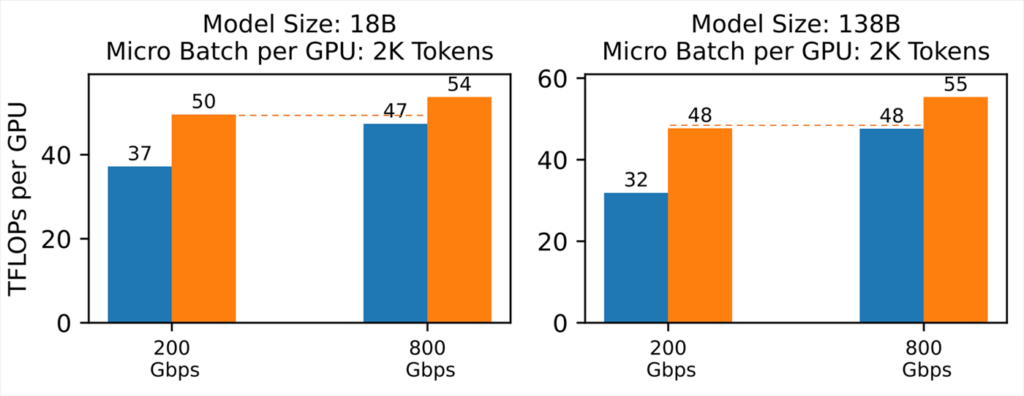
Enabling efficiency equivalence between high and low bandwidth clusters
In addition, ZeRO ++ can achieve comparable system throughput in a low-bandwidth cluster compared with ZeRO in a much higher bandwidth setting. As shown in Figure 8, for both 18B and 138B models, ZeRO++ with 200Gbps cross-node link can reach similar TFLOPs compared with ZeRO-3 in 800 Gbps cross-node link settings.
Given the excellent scalability of ZeRO++, we envision ZeRO++ as the next generation of ZeRO for training large AI models.
ZeRO++ for RLHF training with DeepSpeed-Chat
RLHF training background
ChatGPT-like models are powered by LLMs and fine-tuned using RLHF (opens in new tab). RLHF consists of generation (inference) phases and training phases. During the generation phase, the actor model takes a partial conversation as input and generates responses using a sequence of forward passes. Then during the training phase, the critic model ranks the generated responses by quality, providing reinforcement signals for the actor model. The actor model is fine-tuned using these rankings, enabling it to generate more accurate and appropriate responses in subsequent iterations.
RLHF training brings a non-trivial amount of memory pressure as it utilizes four models (actor, reference, critic, reward). Low-rank adaptation (LoRA) is employed to address the memory pressure of RLHF. LoRA freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, significantly reducing the number of trainable parameters. LoRA speeds up RLHF by reducing memory usage, allowing for larger batch sizes, and thus greatly improves throughput.
DeepSpeed-Chat with ZeRO++ for RLHF training
RLHF with LoRA is a unique application for ZeRO++ since most model weights are frozen. This means ZeRO++ can keep these frozen weights quantized in INT4/8 instead of storing them in FP16 and quantizing them before each communication operation. The dequantization after communication is still done to get the weights ready for computation, but the dequantized weights are simply discarded after computation.
Using ZeRO++ for RLHF training in this way reduces both memory usage and communication volume. This boosts training throughput by reducing communication as well as by enabling larger batch sizes due to reduced memory usage. During the generation phase, ZeRO++ uses hpZ to keep all weight communication within each node to utilize the higher intranode communication bandwidth with reduced communication volume, further improving the generation throughput.
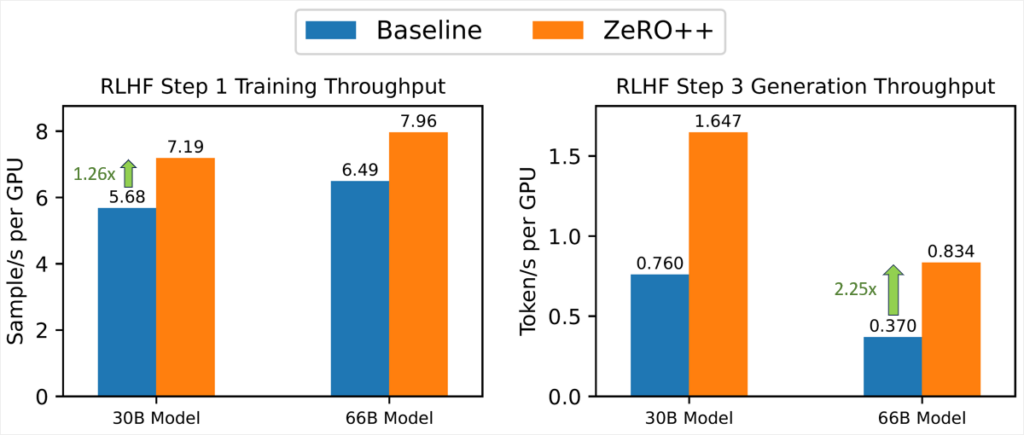
ZeRO++ is integrated into DeepSpeed-Chat to power RLHF training of ChatGPT-like models. In Figure 9, we compare RLHF generation throughput for different sizes of actor models comparing ZeRO with ZeRO++ for 30B and 66B actor models on 32 V100 GPUs. The results show that ZeRO++ enables up to 2.25x better RLHF generation throughput than ZeRO. We also present the speedup for the training phase on 16 V100 GPUs, where ZeRO++ achieves 1.26x better throughput than ZeRO as a result of lower communication and larger batch sizes enabled by ZeRO++.
Release: Try DeepSpeed ZeRO++ today
We are super excited to release DeepSpeed ZeRO++ and make it available for anyone in the AI community. To get started, please visit our GitHub page for LLM training (opens in new tab). ZeRO++ for DeepSpeed-Chat will be released in the coming weeks.
DeepSpeed-ZeRO++ is part of the DeepSpeed ecosystem. To learn more, please visit our website (opens in new tab), where you’ll find detailed blog posts, tutorials, and helpful documentation.
For the latest DeepSpeed news, please follow us on social media:
DeepSpeed welcomes your contributions. We encourage you to report issues, contribute PRs, and join discussions on the DeepSpeed GitHub page. Please see our contributing guide for more details. We are open to collaborations with universities, research labs, and companies. For such requests (and other requests unsuitable for GitHub), please directly email to deepspeed-info@microsoft.com.
Contributors
This project was made possible by the contributions of the following people from the DeepSpeed Team:
Guanhua Wang, Heyang Qin, Sam Ade Jacobs, Connor Holmes, Samyam Rajbhandari, Olatunji Ruwase, Ammar Ahmad Awan, Jeff Rasley, Michael Wyatt, Yuxiong He (team lead)