

At the 2005 Conference on Neural Information Processing Systems, researcher Hanna Wallach found herself in a unique position—sharing a hotel room with another woman. Actually, three other women to be exact. In the previous years she had attended, that had never been an option because she didn’t really know any other women in machine learning. The group was amazed that there were four of them, among a handful of other women, in attendance. In that moment, it became clear what needed to be done. The next year, Wallach and two other women in the group, Jennifer Wortman Vaughan and Lisa Wainer, founded the Women in Machine Learning (WiML) Workshop (opens in new tab). The one-day technical event, which is celebrating its 15th year, provides a forum for women to present their work and seek out professional advice and mentorship opportunities. Additionally, the workshop aims to elevate the contributions of female ML researchers and encourage other women to enter the field. In its first year, the workshop brought together 100 attendees; today, it draws around a thousand.
In creating WiML, the women had tapped into something greater than connecting female ML researchers; they asked whether their machine learning community was behaving fairly in its inclusion and support of women. Wallach and Wortman Vaughan are now colleagues at Microsoft Research, and they’re channeling the same awareness and critical eye to the larger AI picture: Are the systems we’re developing and deploying behaving fairly, and are we properly supporting the people building and using them?


Azure AI Foundry Labs
Get a glimpse of potential future directions for AI, with these experimental technologies from Microsoft Research.
Senior Principal Researchers Jennifer Wortman Vaughan (left) and Hanna Wallach (right), co-founders of the Women in Machine Learning Workshop, bring a people-first approach to their work in responsible AI. The two have co-authored upward of 10 papers together on the topic, and they each co-chair an AI, Ethics, and Effects in Engineering and Research (Aether) working group at Microsoft.
Wallach and Wortman Vaughan each co-chair an AI, Ethics, and Effects in Engineering and Research (Aether) working group—Wallach’s group is focused on fairness, Wortman Vaughan’s on interpretability. In those roles, they help inform Microsoft’s approach to responsible AI, which includes helping developers adopt responsible AI practices (opens in new tab) with services like Azure Machine Learning (opens in new tab). Wallach and Wortman Vaughan have co-authored upward of 10 papers together around the topic of responsible AI. Their two most recent publications in the space address the AI challenges of fairness and interpretability through the lens of one particular group of people involved in the life cycle of AI systems: those developing them.
“It’s common to think of machine learning as a fully automated process,” says Wortman Vaughan. “But people are involved behind the scenes at every step, making decisions about which data to use, what to optimize for, even which problems to solve in the first place, and each of these decisions has the potential to impact lives. How do we empower the people involved in creating machine learning systems to make the best choices?”
Their findings are presented in “Co-Designing Checklists to Understand Organizational Challenges and Opportunities around Fairness in AI” and “Interpreting Interpretability: Understanding Data Scientists’ Use of Interpretability Tools for Machine Learning.” The publications received ACM CHI Conference on Human Factors in Computing Systems (CHI 2020) (opens in new tab) best paper recognition and honorable mention, respectively.
A framework for thinking about and prioritizing fairness
When Wallach took the lead on the Aether Fairness working group, she found herself getting the same question from industry colleagues, researchers in academia, and people in the nonprofit sector: Why don’t you just build a software tool that can be integrated into systems to identify issues of unfairness? Press a button, make systems fair. Some people asked in jest; others more seriously. Given the subjective and sociotechnical nature of fairness, there couldn’t be a single tool to address every challenge, and she’d say as much. Underlying the question, though, was a very real truth: Practitioners needed help. During a two-hour car ride while on vacation, Wallach had an aha moment listening to a Hidden Brain podcast episode about checklists. What practitioners wanted was a framework to help them think about and prioritize fairness.
“I’m getting this question primarily from people who work in the technology industry; the main way they know how to ask for structure is to ask for software,” she recalls thinking of the requests for a one-size-fits-all fairness tool. “But what they actually want is a framework.”
Wallach, Wortman Vaughan, Postdoctoral Researcher Luke Stark, and PhD candidate Michael A. Madaio (opens in new tab), an intern at the time of the work, set out to determine if a checklist could work in this space, what should be on it, and what kind of support teams wanted in adopting one. The result is a comprehensive and customizable checklist that accounts for the real-life workflows of practitioners, with guidelines and discussion points for six stages of AI development and deployment: envision, define, prototype, build, launch, and evolve.

During the first of two sets of workshops, researchers presented participants with an initial AI fairness checklist culled from existing lists, literature, and knowledge of fairness challenges faced by practitioners. Participants were asked to give item-level feedback using sticky notes and colored dots to indicate edits and difficulty level of accomplishing list items, respectively. The researchers used the input to revise the checklist.
Co-designing is key
AI ethics checklists and principles aren’t new, but in their research, Wallach, Wortman Vaughan, and their team found current guidelines are challenging to execute. Many are too broad, oversimplify complex issues with yes/no–style items, and—most importantly—often appear not to have included practitioners in their design. Which is why co-designing the checklist with people currently on the ground developing AI systems formed the basis of the group’s work.
The researchers conducted semi-structured interviews exploring practitioners’ current approaches to addressing fairness issues and their vision of the ideal checklist. Separately, Wallach, Wortman Vaughan, and others in the Aether Fairness working group had built out a starter checklist culled from existing lists and literature, as well as their own knowledge of fairness challenges faced by practitioners. The researchers presented this initial checklist during two sets of workshops, revising the list after each based on participant input regarding the specific items included. Additionally, the researchers gathered information on anticipated obstacles and best-case scenarios for incorporating such a checklist into workflows, using the feedback, along with that from the semi-structured interviews, to finalize the list. When all was said and done, 48 practitioners from 12 tech companies had contributed to the design of the checklist.
During the process, researchers found that fairness efforts were often led by passionate individuals who felt they were on their own to balance “doing the right thing” with production goals. Participants expressed hope that having an appropriate checklist could empower individuals, support a proactive approach to AI ethics, and help foster a top-down strategy for managing fairness concerns across their companies.
A conversation starter
While offering step-by-step guidance, the checklist is not about rote compliance, says Wallach, and intentionally omits thresholds, specific criteria, and other measures that might encourage teams to blindly check boxes without deeper engagement. Instead, the items in each stage of the checklist are designed to facilitate important conversations, providing an opportunity to express and explore concerns, evaluate systems, and adjust them accordingly at natural points in the workflow. The checklist is a “thought infrastructure”—as Wallach calls it—that can be customized to meet the specific and varying needs of different teams and circumstances.
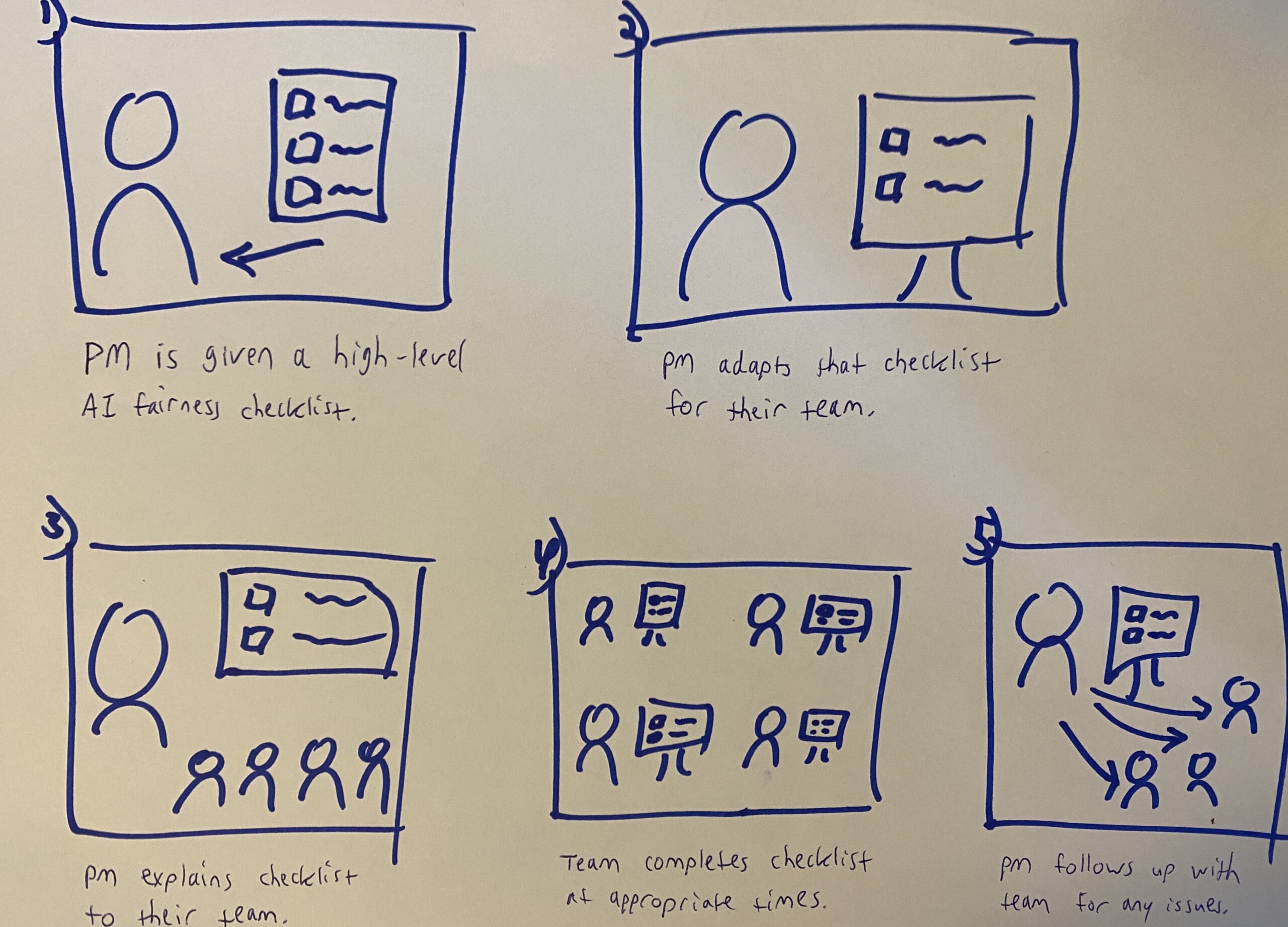
During their co-design workshops, researchers used a series of storyboards based on participant feedback to further understand the challenges and opportunities involved in incorporating AI fairness checklists into workflows.
And just as the researchers don’t foresee a single tool solving all fairness challenges, they don’t view the checklist as a solo solution. The checklist is meant to be used alongside other methods and resources, they say, including software tools like Fairlearn (opens in new tab), the current release of which is being demoed this week at the developer event Microsoft Build (opens in new tab). Fairlearn is an open-source Python package that includes a dashboard and algorithms to support practitioners in assessing and mitigating unfairness in two specific scenarios: disparities in the allocation of opportunities, resources, and information offered by their AI systems and disparities in system performance. Before Fairlearn can help with such disparities, though, practitioners have to identify the groups of people they expect to be impacted by their specific system.
The hope is the checklist—with such guidance as “solicit input on system vision and potential fairness-related harms from diverse perspectives”—will aid practitioners in making such determinations and encourage other important conversations.
“We can’t tell you exactly who might be harmed by your particular system and in what way,” says Wallach. “But we definitely know that if you didn’t have a conversation about this as a team and really investigate this, you’re definitely doing it wrong.”
Tackling the challenges of interpreting interpretability
As with fairness, there are no easy answers—and just as many complex questions—when it comes to interpretability.
Wortman Vaughan recalls attending a panel discussion on AI and society in 2016 during which one of the panelists described a future in which AI systems were so advanced that they would remove uncertainty from decision-making. She was confounded and angered by what she perceived as a misleading and irresponsible statement. The uncertainty inherent in the world is baked into any AI systems we build, whether it’s explicit or not, she thought. The panelist’s comment weighed on her mind and was magnified further by current events at the time. The idea of “democratizing AI” was gaining steam, and models were forecasting a Hillary Rodham Clinton presidency, an output many were treating as a done deal. She wondered to the point of obsession, how well do people really understand the predictions coming out of AI systems? A dive into the literature on the ML community’s efforts to make machine learning interpretable was far from reassuring.
“I got really hung up on the fact that people were designing these methods without stopping to define exactly what they mean by interpretability or intelligibility, basically proposing solutions without first defining the problem they were trying to solve,” says Wortman Vaughan.
That definition rests largely on who’s doing the interpreting. To illustrate, Wallach provides the example of a machine learning model that determines loan eligibility: Details regarding the model’s mathematical equations would go a long way in helping an ML researcher understand how the model arrives at its decisions or if it has any bugs. Those same details mean little to nothing, though, to applicants whose goal is to understand why they were denied a loan and what changes they need to make to position themselves for approval.
In their work, Wallach and Wortman Vaughan have argued for a more expansive view of interpretability (opens in new tab), one that recognizes that the concept “means different things to different people depending on who they are and what they’re trying to do,” says Wallach.
As ML models continue to be deployed in the financial sector and other critical domains like healthcare and the justice system—where they can significantly affect people’s livelihood and well-being—claiming ignorance of how an AI system works is not an option. While the ML community has responded to this increasing need for techniques that help show how AI systems function, there’s a severe lack of information on the effectiveness of these tools—and there’s a reason for that.
“User studies of interpretability are notoriously challenging to get right,” explains Wortman Vaughan. “Doing these studies is a research agenda of its own.”
Not only does designing such a study entail qualitative and quantitative methods, but it also requires an interdisciplinary mix of expertise in machine learning, including the mathematics underlying ML models, and human–computer interaction (HCI), as well as knowledge of both the academic literature and routine data science practices.
The enormity of the undertaking is reflected in the makeup of the team that came together for the “Interpreting Interpretability” paper. Wallach, Wortman Vaughan, and Senior Principal Researcher Rich Caruana have extensive ML experience; PhD student Harmanpreet Kaur (opens in new tab), an intern at the time of the work, has a research focus in HCI; and Harsha Nori (opens in new tab) and Samuel Jenkins (opens in new tab) are data scientists who have practical experience building and using interpretability tools. Together, they investigated whether current tools for increasing the interpretability of models actually result in more understandable systems for the data scientists and developers using them.
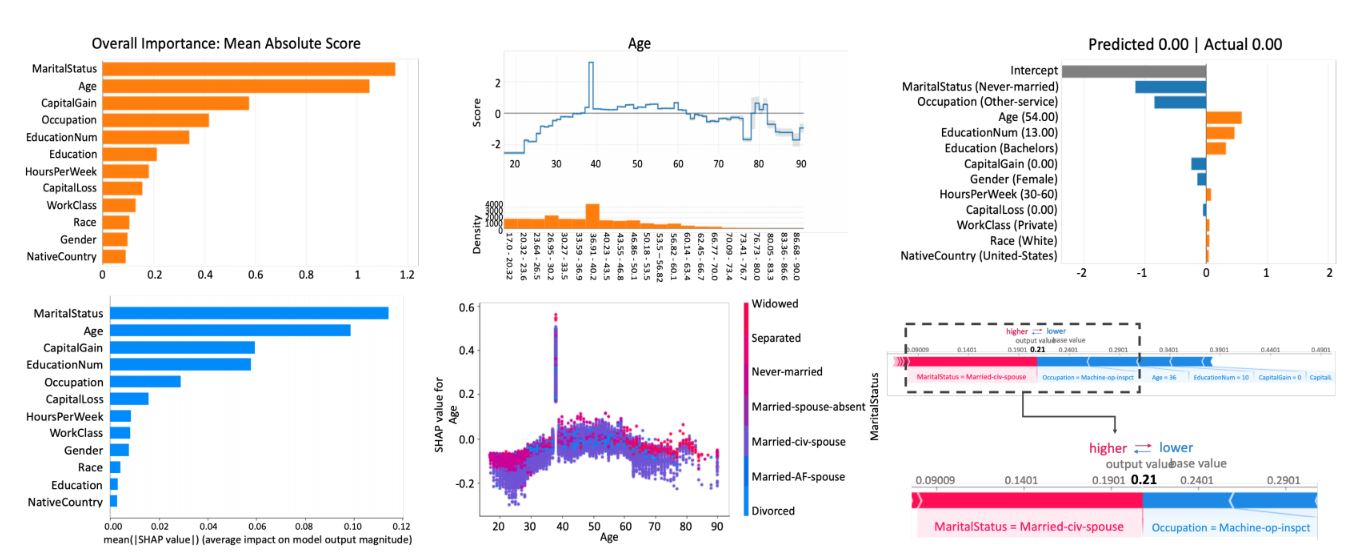
Three visualization types for model evaluation are output by the popular and publicly available InterpretML implementation of GAMs (top) and the implementation of SHAP in the SHAP Python package (bottom), respectively. Left column: global explanations. Middle column: component (GAMs) or dependence plot (SHAP). Right column: local explanations.
Tools in practice
The study focuses on two popular and publicly available tools, each representative of one of two techniques dominating the space: the InterpretML implementation of GAMs, which uses a “glassbox model” approach, by which models are designed to be simple enough to understand, and the implementation of SHAP in the SHAP Python package, which uses a post-hoc explanation approach for complex models. Each tool outputs three visualization types for model evaluation.
Through pilot interviews with practitioners, the researchers identified six routine challenges that data scientists face in their day-to-day work. The researchers then set up an interview study in which they placed data scientists in context with data, a model, and one of the two tools, assigned randomly. They examined how well 11 practitioners were able to use the interpretability tool to uncover and address the routine challenges.

The researchers found participants lacked an overall understanding of the tools, particularly in reading and drawing conclusions from the visualizations, which contained importance scores and other values that weren’t explicitly explained, causing confusion. Despite this, the researchers observed, participants were inclined to trust the tools. Some came to rely on the visualizations to justify questionable outputs—the existence of the visualizations offering enough proof of the tools’ credibility—as opposed to using them to scrutinize model performance. The tools’ public availability and widespread use also contributed to participants’ confidence in the tools, with one participant pointing to its availability as an indication that it “must be doing something right.”
Following the interview study, the researchers surveyed nearly 200 practitioners, who were asked to participate in an adjusted version of the interview study task. The purpose was to scale up the findings and gain a sense of their overall perception and use of the tools. The survey largely supported participants’ difficulty in understanding the visualizations and their superficial use of them found in the interview study, but also revealed a path for future work around tutorials and interactive features to support practitioners in using the tools.
“Our next step is to explore ways of helping data scientists form the right mental models so that they can take advantage of the full potential of these tools,” says Wortman Vaughan.
The researchers conclude that as the interpretability landscape continues to evolve, studies of the extent to which interpretability tools are achieving their intended goals and practitioners’ use and perception of them will continue to be important in improving the tools themselves and supporting practitioners in productively using them.
Putting people first
Fairness and interpretability aren’t static, objective concepts. Because their definitions hinge on people and their unique circumstances, fairness and interpretability will always be changing. For Wallach and Wortman Vaughan, being responsible creators of AI begins and ends with people, with the who: Who is building the AI systems? Who do these systems take power from and give power to? Who is using these systems and why? In their fairness checklist and interpretability tools papers, they and their co-authors look specifically at those developing AI systems, determining that practitioners need to be involved in the development of the tools and resources designed to help them in their work.
By putting people first, Wallach and Wortman Vaughan contribute to a support network that includes resources and also reinforcements for using those resources, whether that be in the form of a community of likeminded individuals like in WiML, a comprehensive checklist for sparking dialogue that will hopefully result in more trustworthy systems, or feedback from teams on the ground to help ensure tools deliver on their promise of helping to make responsible AI achievable.