
Federated learning has become a major area of machine learning (ML) research in recent years due to its versatility in training complex models over massive amounts of data without the need to share that data with a centralized entity. However, despite this flexibility and the amount of research already conducted, it’s difficult to implement due to its many moving parts—a significant deviation from traditional ML pipelines.
The challenges in working with federated learning result from the diversity of local data and end-node hardware, privacy concerns, and optimization constraints. These are compounded by the sheer volume of federated learning clients and their data and necessitates a wide skill set, significant interdisciplinary research efforts, and major engineering resources to manage. In addition, federated learning applications often need to scale the learning process to millions of clients to simulate a real-world environment. All of these challenges underscore the need for a simulation platform, one that enables researchers and developers to perform proof-of-concept implementations and validate performance before building and deploying their ML models.
A versatile framework for federated learning
Today, the Privacy in AI team at Microsoft Research is thrilled to introduce Federated Learning Utilities and Tools for Experimentation (opens in new tab) (FLUTE) as a framework for running large-scale offline federated learning simulations, which we discuss in detail in the paper, “FLUTE: A Scalable, Extensible Framework for High-Performance Federated Learning Simulations.” In creating FLUTE, our goal was to develop a high-performance simulation platform that enables quick prototyping of federated learning research and makes it easier to implement federated learning applications.
There has been a lot of research in the last few years directed at tackling the many challenges in working with federated learning, including setting up learning environments, providing privacy guarantees, implementing model-client updates, and lowering communication costs. FLUTE addresses many of these while providing enhanced customization and enabling new research on a realistic scale. It also allows developers and researchers to test and experiment with certain scenarios, such as data privacy, communication strategies, and scalability, before implementing their ML model in a production framework.

One of FLUTE’s main benefits is its native integration with Azure ML workspaces, leveraging the platform’s features to manage and track experiments, parameter sweeps, and model snapshots. Its distributed nature is based on Python and PyTorch, and the flexibly designed client-server architecture helps researchers and developers quickly prototype novel approaches to federated learning. However, FLUTE’s key innovation and technological differentiator is the ease it provides in implementing new scenarios for experimentation in core areas of active research in a robust high-performance simulator.
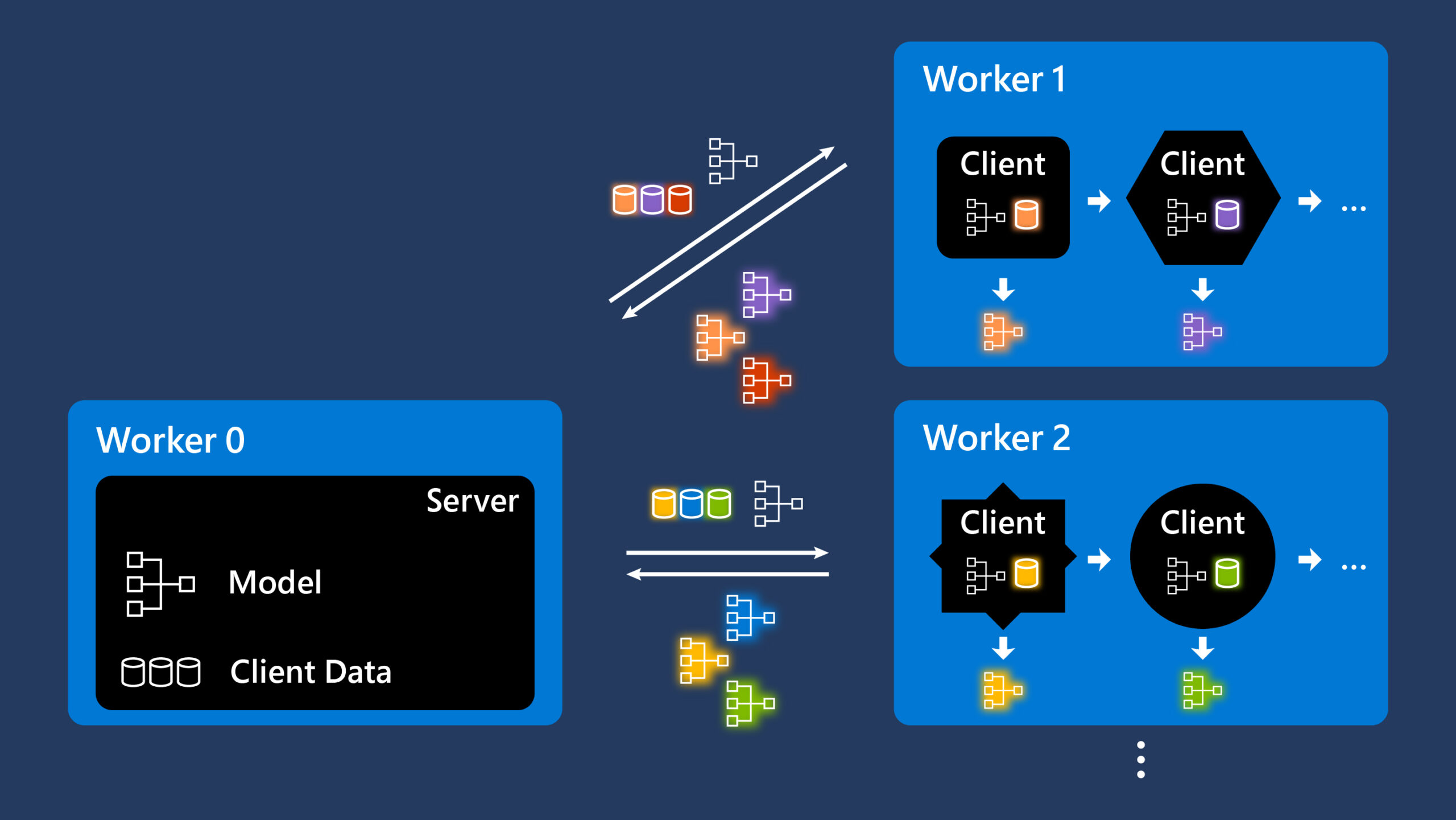
FLUTE offers a platform where all clients are implemented as isolated object instances, as shown in Figure 1. The interface between the server and the remaining workers relies on messages that contain client IDs and training information, with MPI (opens in new tab) as the main communication protocol. Local data on each client stays within local storage boundaries and is never aggregated with other local sources. Clients only communicate gradients to the central server.
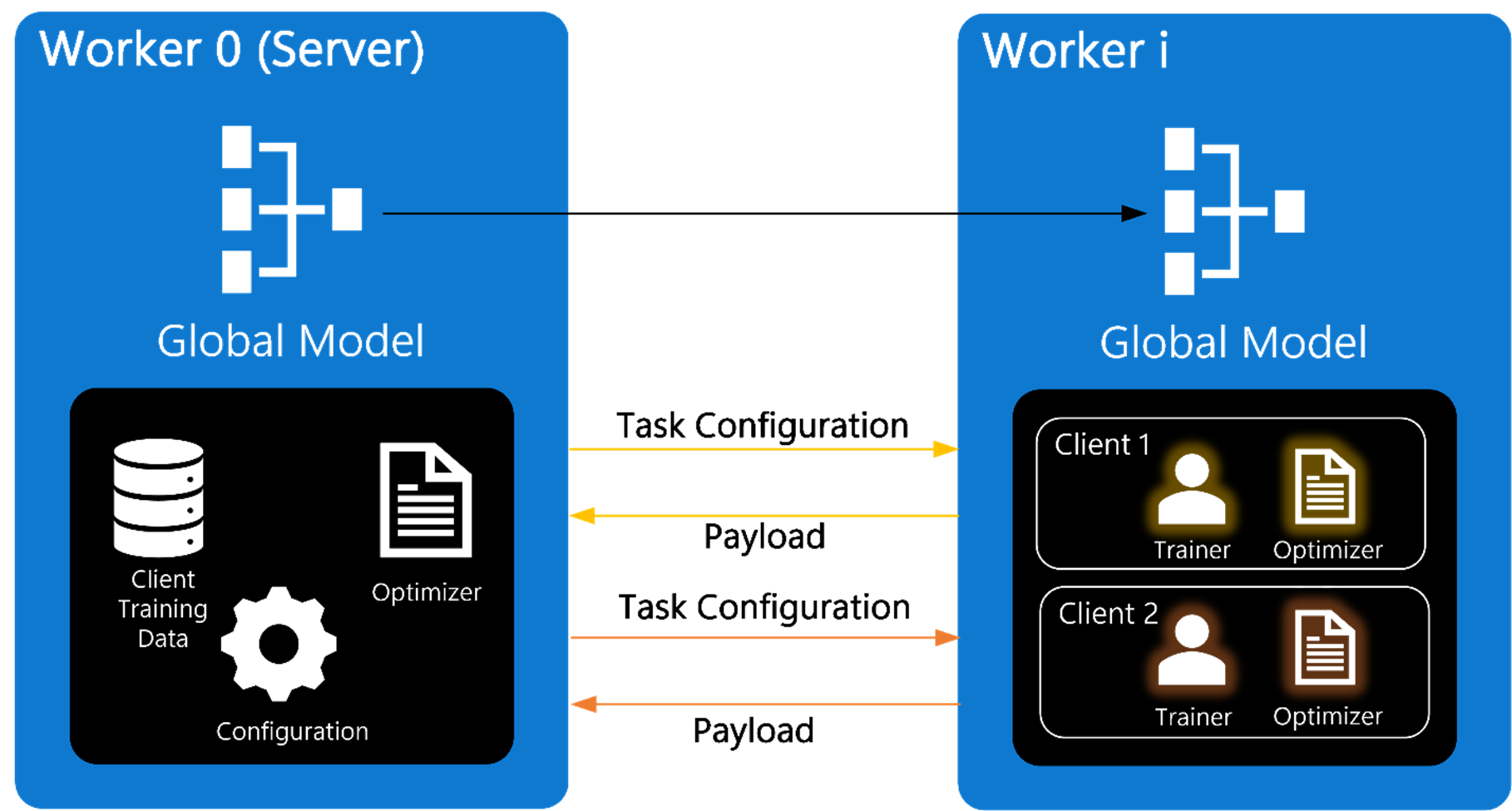
The following features contribute to FLUTE’s versatile framework and enable experimentation with new federated learning approaches:
- Scalability: Scale is a critical factor in understanding practical metrics, such as convergence and privacy-utility tradeoffs. Researchers and developers can run large-scale experiments using tens of thousands of clients with a reasonable turnaround time.
- Flexibility: FLUTE supports diverse federated learning configurations, including standardized implementations such as DGA and FedAvg (opens in new tab).
- Versatility: FLUTE’s generic API helps researchers and developers easily implement new models, datasets, metrics, and experimentation features, while its open architecture helps them add new algorithms in such areas as optimization, privacy, and robustness.
Available as an open-source platform
As part of this announcement, we’re making FLUTE available as a versatile open-source platform (opens in new tab) for rapid prototyping and experimentation. It comes with a set of basic tools to help kickstart experiments. We hope researchers and developers take advantage of this framework by exploring new approaches to federated learning.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
Looking ahead
FLUTE’s innovative framework offers a new paradigm for implementing federated learning algorithms at scale, and this is just the beginning. We’re making improvements with the view toward making FLUTE the standard federated learning simulation platform. Future releases will include algorithmic enhancements in optimization and support for additional communication protocols. We’re also adding features to make it easier to set up experiments when including tailored features in new tasks and the ability to easily incorporate FLUTE as a library into Azure ML pipelines.
Additional resources
Check out this video (opens in new tab) for a deep dive into FLUTE architecture and a tutorial on how to use it. Our documentation (opens in new tab) also explains how to implement FLUTE.
You can learn more about the FLUTE project by visiting our project page, and discover more about our current federated learning research as well as other projects related to privacy in AI on our group page.
Explore More
FLUTE (Federated Learning Utilities for Testing and Experimentation) is a platform for conducting high-performance federated learning simulations.