

Humans play an indispensable role in many modern AI-enabled services – not just as consumers of the service, but as the actual intelligence behind the artificial intelligence. From news portals to e-commerce websites, it is people’s ratings, clicks, and other interactions which provide a teaching signal used by the underlying intelligent systems to learn. While these human-in-the-loop systems improve through user interaction over time, they must also provide enough short-term benefit to people to be helpful.
Progress in AI has been rapid in the last decade due in large part to advances in machine learning, the power of cloud computing and the availability of big data. But the understanding of how AI technology can and should interact with people in human-in-the-loop systems is still in its infancy.
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the latest episodes on demand.
Ideally, a human-in-the-loop system should get better at knowing what a person is interested in, but this requires that the system is able to try out new and possibly uninteresting options. This process is known as exploration in machine learning. Imagine you have a personal chef who knows your likes and always presents you with a menu of your five favorite dishes – you may always be satisfied with dinner but miss out on learning about new and delicious unfamiliar dishes.
Without exploration, an intelligent system is likely to get stuck in a self-enforcing loop in which it just presents people with options that it already knows are interesting to them. From the user’s perspective, this often shows up in the form of a phenomenon called the filter bubble. A filter bubble serves information based on a user’s previous click behavior and search history. Exploration helps burst this bubble. However, exploration can also expose people to irrelevant options. For instance, when our hypothetical chef designs an entirely new menu, you may find that you dislike every dish and end up with heartburn.
Practitioners who develop AI systems must balance the need to let systems explore (and learn) with the risk of failures – possibly hurting the service and even losing customers. To avoid this, they often turn to solutions that focus on short-term satisfaction and neglect exploration which is crucial to longer-term system improvements.
So how much can exploration impact people’s short-term satisfaction? In looking at a movie recommender system in our current study, the answer is: not much at all, as long as the system doesn’t explore too much. This is good news for improved learning in AI-enabled services. The system can introduce unexplored options with minimal impact on the short-term experience. However, there appears to be a fairly sharp threshold beyond which too much exploration becomes intolerable. To return to our beleaguered chef, it turns out that putting one or two new options on the menu outside of your usual comfort zone is typically okay – you still have several appealing options and can choose to ignore the new dishes. But an entirely new menu could be a disaster. Our research seeks to answer these tradeoffs in a scientifically well-founded way that will inform a variety of learning algorithms that rely on exploration feedback to improve.
The paper examining this question will be presented by Tobias Schnabel (opens in new tab), a current PhD student at Cornell and former MSR intern at this year’s International Conference on Web Search and Data Mining (WSDM) (opens in new tab). This is the first paper to study the effects of exploration on users in a personalized setting.
Using the interface shown below, we asked over 600 people in our study to find a movie they would like to watch from a made-up movie streaming provider. To help them keep track of interesting movies, people could add them to a shortlist before making their final choice. A panel of recommended movies was presented to people based on what was on their shortlist, as shown in the image below.
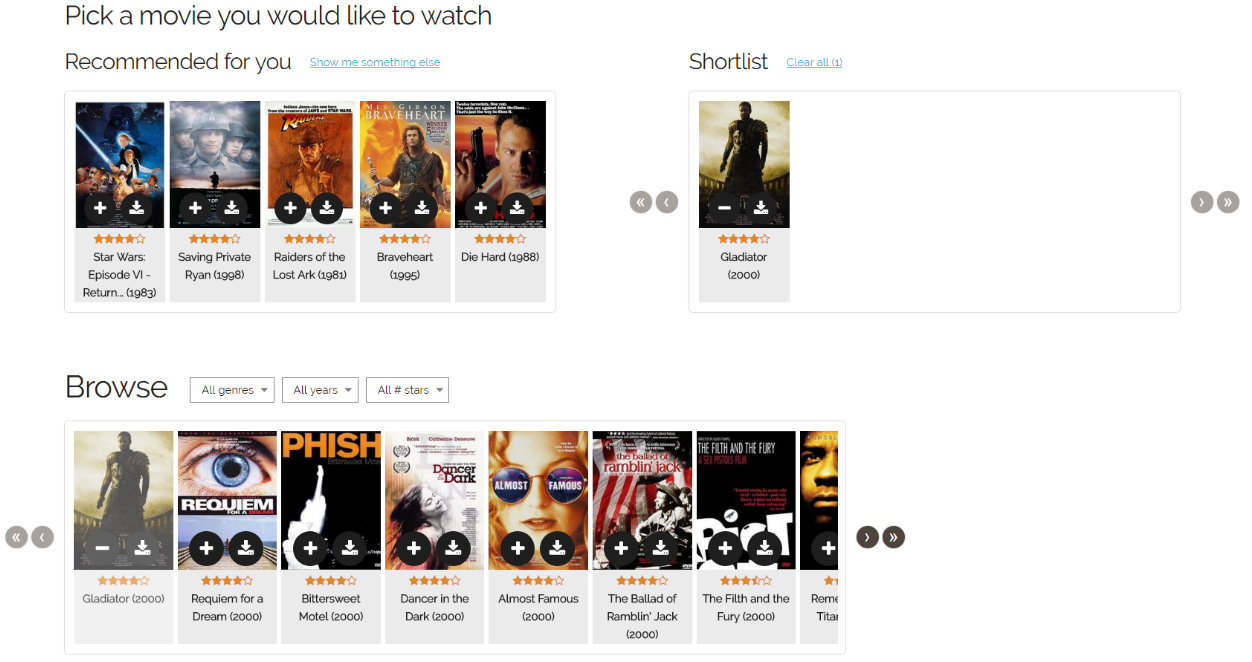
This represents a typical intelligent-system-supported recommendation panel and, therefore, one where we could better understand the impact of exploration. In the study, we varied the number of recommended movies generated from AI system exploration. Since there were five slots that could be filled with recommended movies, we created six different conditions: In the first one, there was no exploration, then one slot was used for exploration, and so on up to the sixth condition, where all slots were filled with movies for exploration. While there are existing approaches for intelligent selection of exploration options, we wanted to understand the worst harm the exploration could do. We therefore chose the exploration items at random. After the participants had chosen a movie to watch, they were asked about their experience with the system.
As expected, when the AI system was allowed to fill a large number of the recommendation slots with movies to explore, participants found the recommendations to be significantly less relevant, less helpful and less transparent. However, when only one or two slots were used for exploration, people did not report any significant effects on relevance, helpfulness or transparency. This suggests that as long as most of the items in the recommendations are relevant, people can tolerate some less appealing options as well. This approach enables the system to improve the underlying intelligence more generally and to better meet each person’s long-term needs – while still helping the person make a more intelligent, short-term selection as well!
We also measured how people interacted with the items that were recommended. For example, how often they clicked on them or how often they added recommendations to their shortlist. Not only is the amount of interaction an important user engagement indicator, but the data contains valuable information for the AI to infer what a user is interested in. User engagement measured by interaction showed the same trends we observed with reported satisfaction. When only a few recommendation slots were filled with movies selected for exploration, impact on interaction was minimal. With a greater number of exploration slots, interaction sharply decreased, rendering any learning algorithms less efficient and hindering long-term improvement.
This study shows if we control the amount of exploration, the impact on short-term satisfaction and engagement is minimal. This is encouraging for many real-world AI-enabled systems, since it means that they can effectively learn from human interaction by showing some options that are outside of people’s known preferences. In our study, the exploration component picked movies at random, inspired by common exploration strategies in machine learning. This is clearly just one possible strategy, and we are keen to study more sophisticated ones, such as only showing popular movies to people.
This is a great example of a research project that came out of a long-term collaboration between Microsoft Research and academia. The collaboration grew out of Tobias Schnabel’s internship at Microsoft Research in 2016 and has led to multiple publications at premier conferences.
In addition to Tobias Schnabel (opens in new tab) from Cornell University, the team of authors includes principal researcher Paul N. Bennett, distinguished scientist Susan T. Dumais from Microsoft Research AI, and professor Thorsten Joachims from Cornell University.

From left to right: Susan T Dumais, Tobias Schnabel, Paul Bennett