Ever since it was released in the 1980s, Microsoft Excel has changed how people organize, analyze, and visualize their data, providing a basis for decision-making for the millions of people who use it each day. It’s also the world’s most widely used programming language. Excel formulas are written by an order of magnitude more users than all the C, C++, C#, Java, and Python programmers in the world combined. Despite its success, considered as a programming language Excel has fundamental weaknesses. Over the years, two particular shortcomings have stood out: (1) the Excel formula language really only supported scalar values—numbers, strings, and Booleans—and (2) it didn’t let users define new functions.
Until now.
The Calc Intelligence project at Microsoft Research Cambridge has a long-standing partnership with the Excel team to transform spreadsheet formulas into a full-fledged programming language. The fruits of that partnership are starting to appear in the product itself. At the 2019 ACM SIGPLAN Symposium on Principles of Programming Languages (POPL 2019), we announced two significant developments: data types (opens in new tab) take Excel beyond text and numbers and allow cells to contain first-class records, including entities linked to external data, and dynamic arrays (opens in new tab) allow ordinary formulas to compute whole arrays that spill into adjacent cells. These changes are a substantial start on our first challenge: rich, fully-first-class structured data in Excel.
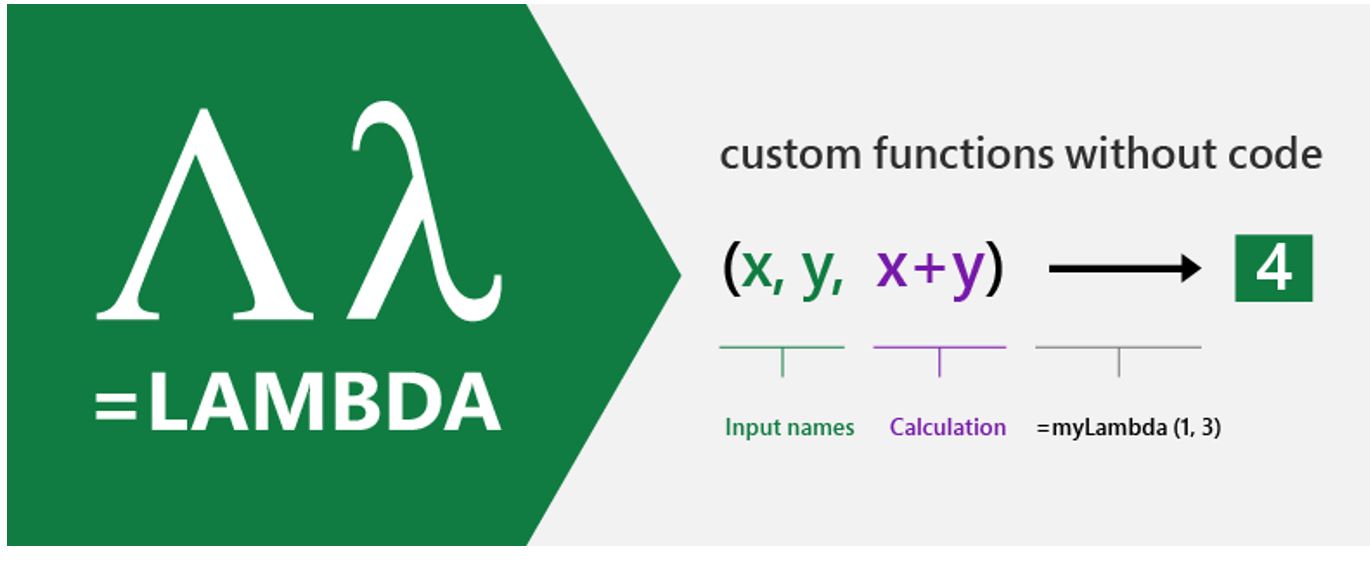
In December 2020, we announced LAMBDA (opens in new tab), which allows users to define new functions written in Excel’s own formula language, directly addressing our second challenge. These newly defined functions can call other LAMBDA-defined functions, to arbitrary depth, even recursively. With LAMBDA, Excel has become Turing-complete. You can now, in principle, write any computation in the Excel formula language. LAMBDA is available to members of the Insiders: Beta program. The initial release has some implementation restrictions that we expect to lift in the future. We discussed LAMBDA and some of our research on spreadsheets in a sponsored video presented at POPL 2021.
The power of LAMBDA
Researchers have known since the 1960s that Church’s lambda notation is a foundation for a wide range of programming languages and hence is a highly expressive programming construct in its own right. Its incorporation into Excel represents a qualitative shift, not just an incremental change.
To illustrate the power of LAMBDA, here’s a function written using the notation to compute the length of the hypotenuse of a right-angled triangle:
=LAMBDA( X, Y, SQRT( X*X+Y*Y ) )LAMBDA complements the March 2020 release of LET, which allows us to structure the same example like this:
=LAMBDA( X, Y, LET( XS, X*X, YS, Y*Y, SQRT( XS+YS ) ) )The function takes two arguments named X and Y, binds the value of X*X to the name XS, binds the value of Y*Y to YS, and returns SQRT( XS+YS) as its result.
The existing Name Manager in Excel allows any formula to be given a name. If we name our function PYTHAGORAS, then a formula such as PYTHAGORAS(3,4) evaluates to 5. Once named, you call the function by name, eliminating the need to repeat entire formulas when you want to use them.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
Moreover, LAMBDA is the true lambda that we know and love: a lambda can be an argument to another lambda or its result; you can define the Church numerals; lambdas can return lambdas, so you can do currying; you can define a fixed-point combinator using LAMBDA and hence write recursive functions; and so on. (Additionally, since lambdas can be named, they can directly call themselves recursively, which is much more convenient than using a fixed-point combinator.)
Examples: Recursively reversing a string and fixed-point combinator
Reversing a string is beyond the built-in functions of Excel and could only previously be written outside the formula language, by using Visual Basic or JavaScript. Here is a definition of REVERSE as a recursive LAMBDA, which makes use of a couple of auxiliary functions—HEAD and TAIL—to compute the first character and everything but the first character, respectively.

Even without relying on a recursively defined name, the formula language is Turing-complete because we can encode recursive function definitions using the classic call-by-value fixed-point combinator. In fact, running this combinator was one of the early stress tests of LAMBDA in the Excel codebase. Here it is, applied to define a factorial function.

(In contrast, Felienne Hermans’s lovely blog post about writing a Turing machine in Excel (opens in new tab) doesn’t, strictly speaking, establish Turing completeness because it uses successive rows for successive states, so the number of steps is limited by the number of rows.)
What’s next?
There’s plenty more to come. In the short term, we expect to see fully nestable arrays and efficient implementations of array-processing combinators, such as MAP and REDUCE, that take lambda functions as their arguments. Beyond that, we hope to define functions not just by a single formula but by a whole worksheet, so-called sheet-defined functions, or even elastic sheet-defined functions. In practical terms, sheet-defined functions will “go with the flow” of typical spreadsheet design by allowing users to define a larger function via multiple formulas spread out over multiple cells.
Response from the community
A programming language is only successful if its user base can readily and effectively use its power. One might wonder whether LAMBDA might be good for programming language enthusiasts but just too hard for end users to make sense of. In releasing LAMBDA, Microsoft has effectively launched a global-scale experiment on end-user programming with higher-order functions.
Early feedback is encouraging. Within 24 hours of LAMBDA’s release in December, there were multiple videos, including one on splitting data across columns (opens in new tab) and one on using LAMBDA and LET to create single-cell reports (opens in new tab), and blog posts, such as this one on calculating axis scales (opens in new tab), from the Excel community describing applications of LAMBDA that we had never thought of. A trade article describes the transition of Excel into a Turing-complete programming language (opens in new tab).
Moreover, even if it takes greater skill and knowledge to author a lambda, it takes no extra skill to call it. LAMBDA allows skilled authors to extend Excel with application-domain-specific functions that appear seamlessly part of Excel to their colleagues, who simply call them.
It will be interesting to see how users continue to experiment with and apply not only LAMBDA but also data types and dynamic arrays. We believe these new functional programming features will transform how people make decisions with Excel.
From research to product and back to research
Our partnership with the product team exemplifies a symbiosis between research and practice. For example, like many long-lived programming systems, the only really precise documentation of Excel semantics is its source code. So to understand what Excel really does, we developed a written semantics for it and a reference implementation of formula evaluation in TypeScript, Calc.ts.
We initially thought the Excel formula language was quite simple—that is part of what makes it so attractive to end users—but we found that it embodies a variety of interesting and little-known features. For example, in Excel, a range—a rectangular area of the grid—is a first-class value. The function ROW( range ) returns the row number of the first row of the range, so ROW( A7:A99 ) returns 7. But since ranges are first class, they can be returned by functions: INDEX( A7:A99, 3 ), for instance, returns a reference to the third cell of the range A7:A99—namely the range A9:A9—and not the value of cell A9. So ROW( INDEX( A7:A99, 3 ) ) returns 9. Excel has quite a few functions that take or return ranges, including union and intersection operators. It even has an INDIRECT function, which takes a string and interprets it as a range: INDIRECT( “A9” & “9”) returns the range A99:A99 (here & is string concatenation).
We also discovered that Excel has a mechanism for “auto-lifting” functions over arrays. For example, SUM( A2:A100 + 1 ) takes the range A2:A100, dereferences it to a vector of 99 values (since (+) doesn’t accept references), then adds one to each element (lifting (+) over the array), and sums up the result. It took us some time to understand the precise rules that drive this behavior, but they turned out to be simple and systematic.
The act of writing an independent semantics of the Excel formula language led to some extended dialogues with the Excel team, a lot of experimental validation, and—on occasion—conversations with Excel engineers, who checked the source code.
Our independent reference implementation not only fleshed out and brought the semantics to life, but it also serendipitously turned out to be incredibly useful for the web version of Excel, which needs to evaluate formulas in the browser. Read the story of Calc.ts, which powers client-side calculations for the web version of Excel, on the Microsoft Garage Wall of Fame. Beyond its product impact, Calc.ts is a fantastic research asset, too, as it allows variations of formula evaluation to be prototyped for rapid experimentation, for intern or university projects, for example. Let us know if you’d like access to Calc.ts for research purposes.
More broadly, we’ve built on our partnership to develop a research program around the theme of end-user programming, specifically involving a research crossover between programming languages, human-computer interaction, and machine learning, as demonstrated by this selection of papers:
- End-User Probabilistic Programming (QEST 2019): We examine how RAND() already allows probabilistic programming in spreadsheets and consider how sheet-defined functions and other features can enhance probabilistic modeling by end users.
- Understanding and Inferring Units in Spreadsheets (VL/HCC 2020): We combine a formal type system with machine learning to predict the units of numbers in spreadsheets.
- Gridlets: Reusing Spreadsheet Grids (CHI 2020; late-breaking work): We present a new abstraction over calculation and presentation applicable to spreadsheet reuse.
- Higher-Order Spreadsheets with Spilled Arrays (ESOP 2020): We present a formal semantics for dynamic arrays and propose the grid calculus, an extension of formula evaluation to implement gridlets.
- Spreadsheet Comprehension: Guesswork, Giving up and Going back to the Author (CHI 2021): We examine how people go about understanding how an unfamiliar spreadsheet works, and we generalize to discover common problems.
- TweakIt: Supporting End-User Programmers Who Transmogrify Code (CHI 2021): We investigate how live previews of code snippet output can support end users who copy and modify code from the web to process data in their spreadsheets.
Join our team!
Calc Intelligence is hiring. We aim to be a diverse and inclusive (opens in new tab) team representing a range of disciplines, including human-computer interaction, machine learning, and programming languages. Your work in our team could have a real impact on the world’s most popular programming language! Learn more about 2021 internship opportunities in human-computer interaction (opens in new tab) and in programming languages (opens in new tab) and about the Calc Intelligence project (opens in new tab).