
Over the last five years, deep learning-based methods have revolutionised a wide range of applications, for example those requiring understanding of pictures (opens in new tab), speech and natural language (opens in new tab). For computer scientists, a naturally arising question is whether computers learn to understand source code? It appears to be a trivial question at first glance because programming languages indeed are designed to be understood by computers. However, many software bugs are in fact instances of Do what I mean, not what I wrote. In other words, small typos can have big consequences.
Consider a simple example such as:
float getHeight { return this.width; }.
In this example, the problem is obvious to a human, or a system that understands the meaning of the terms “height” and “width”. The key insight here is that source code serves two functions. First, it communicates to the computer precisely which hardware instructions to execute. Second, it communicates to other programmers (or to the authors themselves six weeks later) how the program works. The latter is achieved by the choice of names, code layout and code comments. By identifying cases in which the two communication channels seem to diverge, an automatic system can point to likely software bugs.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Program analysis in the past has largely focused on either the formal, machine-interpretable semantics of programs or it has viewed programs as a (somewhat odd) instance of natural language. Approaches from the former are rooted in mathematical logic and require extensive engineering effort for every new case that needs to be handled. On the other hand, natural language approaches involve applications of natural language processing tools that work well on purely syntactic tasks but so far have not been able to learn semantics of programs.
In a new paper (opens in new tab) presented at ICLR 2018 (opens in new tab), researchers from Microsoft Research and from Simon Fraser University Vancouver present a new way to combine these two worlds and show how to find bugs in released software.
Program Graphs
To be able to learn from the rich structure of source code, it is first transformed into a program graph. The nodes of the graph include the tokens of the program (that is, variables, operators, method names, and so on) and the nodes of its abstract syntax tree (elements from the grammar defining the language syntax such as IfStatement). The program graph contains two different types of edges: syntactic edges, representing only how the code should be parsed, such as while loops and if blocks; and semantic edges that are the result of simple program analyses.
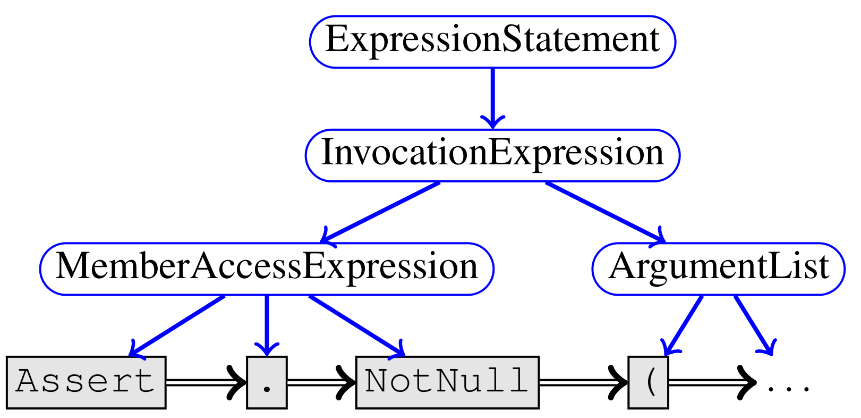
Figure 1: Syntactic Edges
Syntactic edges include simple “NextToken” edges, “Child” edges that are used to represent the abstract syntax tree and “LastLexicalUse” edges that connect a token to the last time it occurred in the source code text. Figure 1 shows a partial example of such edges for the statement Assert.NotNull(clazz), in which nodes corresponding to tokens are gray boxes and nodes corresponding to non-terminals of the program grammar are blue ovals. Child edges are shown as blue, solid edges, whereas NextToken edges are black double edges.
Semantic edges include “LastUse” edges that connect a variable to the last time it may have been used in program execution (which in the case of loops can be later in the source code), “LastWrite” edges that connect a variable to the last time it was written to, as well as “ComputedFrom” edges, that connect a variable to the values it was computed from. Many more semantic edges are possible, leveraging other tools from the program analysis toolbox, such as aliasing and points-to analyses, as well as path conditions. Figure 2 illustrates some semantic edges on a small snippet of code (in black).

Figure 2. Semantic Edges
LastUse relationships are shown as green edges; and so for example y is linked to the last use of y before the loop as well as to itself. Similarly, LastWrite relationships are shown as red edges, and so the use of x in the while condition is linked to the assignment of x before the loop as well to the assignment of x inside the loop. Finally, ComputedFrom relationships are indicated by blue edges, linking a variable to those variables that it is computed from.
Syntactic edges roughly correspond to what a programmer sees when reading the source code. On the other hand, semantic edges correspond to aspects of how the program is executed. By combining these concepts in a single graph, the system can learn from more information sources at the same time than in prior approaches.
Learning from Graphs
Learning from graph-structured data has received some attention recently as graphs are a standard way to represent data and its relationships. Knowledge about an organization can be organized in a graph (opens in new tab)just as drug molecules can be viewed as a graph of atoms. Two successful recent approaches to deep learning on graphs are graph convolutional networks (an extension of convolution networks that are the key to image understanding) and gated graph neural networks (an extension of recurrent neural networks that are widely used in natural language processing).
Both approaches first process each node independently to obtain an internal representation (that is, a vector in a low-dimensional space) of the node itself. They then repeatedly combine the representation of each node with the representation of nodes it is connected to (the two methods differ in how this combination works.) Thus, after one step, each node has information about itself and its direct neighbors; after two steps, it additionally has information about nodes two steps away, and so on. As all steps of the method are (small) neural networks, they can be trained to extract the information relevant for the overall task from data.
Finding Bugs
Learning on program graphs can be used to find bugs such as the one shown in the example at the beginning of this post. For this, the model is given a program, a location in that program and a list of variables that could be used in that location. The model is then asked to predict which variable should be used. To handle this task, the program is transformed into a graph, with a special node corresponding to the location to consider. By considering the computed representation of that special node, as well as the representations of the nodes corresponding to the allowed variables, the network can compute how likely each variable is. Such a model can easily be trained by feeding it millions of lines of existing code and does not require specially annotated datasets.
When the model is run on new code and predicts a var1 with very high probability, whereas the programmer has chosen var2, this may indicate a bug. By flagging these issues for review by a human expert, actual bugs have been found. As an example, consider the following example taken from Roslyn, the Microsoft C# compiler:
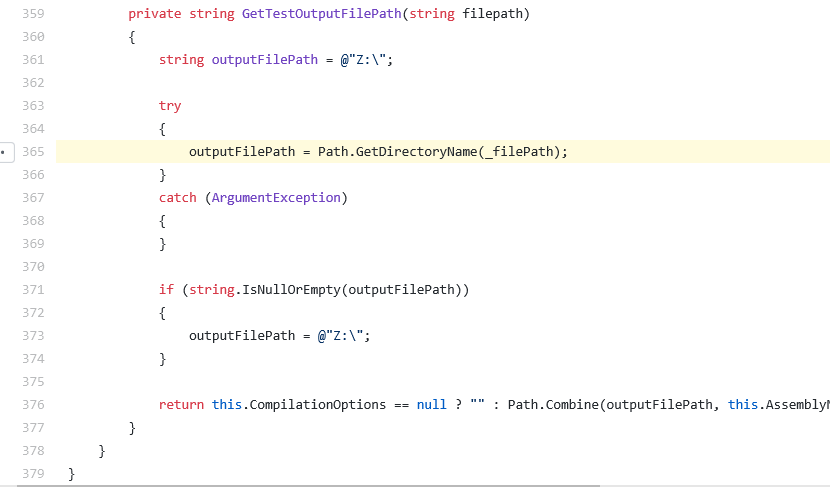
Note the highlighted uses of the parameter filepath and the field _filePath, which are easily mistaken for each other. However, the use of _filePath was just a typo, which the developers fixed (opens in new tab) after researchers reported this and similar issues. Similar bugs were found, reported and fixed in a range of other C# projects as well.
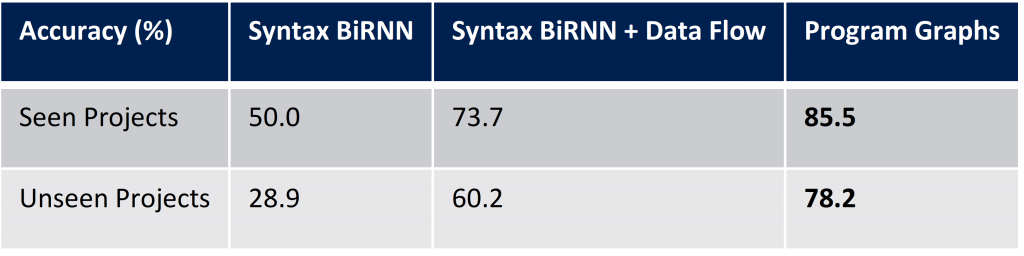
In a larger quantitative evaluation, the new approach fares far better than traditional machine learning techniques. As baselines, a bidirectional recurrent neural network (BiRNN) working directly on the source code and a simple extension of the BiRNN accessing some information about the flow of data were considered. To evaluate the different models, open-source C# projects containing 2.9 million lines of source code in total were analysed. The different machine learning models were shown the source code in which a single variable was blanked out and were asked to predict the originally used variable (assumed to be almost always correct, as the code was well-tested). In a first experiment, the models were tested on held-out files from projects that contributed other files to the training data. In a second experiment, the models were tested on data from entirely new projects. The results are shown in the following table, where learning on the newly proposed program graphs leads to substantially better results.
Future Applications
Program graphs are a versatile tool for applying deep learning methods on programs. Microsoft’s incoming AI residents will continue to study their applications over the next year.