Editor’s note, Dec. 11, 2023 – The section regarding fabrication and incoherence was updated for accuracy.
Large language models (LLMs) are profoundly useful for a vast array of difficult tasks. But they sometimes make unpredictable mistakes or perpetuate biased language. These sorts of errors tend to arise over time due to changes in the underlying data or in user behavior. This necessitates targeted, cost-effective fixes to these models and the real-world applications they support.
Repeated pretraining or finetuning might be used to achieve these fixes. However, these solutions are often too computationally expensive. For example (opens in new tab), LLAMA 1 was trained for 21 days on 2,048 A100 GPUs, costing over $2.4 million. Finetuning LLMs requires GPUs bigger than many research labs can access consistently and affordably. Plus, it remains largely unknown which data should even be added or removed from a data corpus to correct specific behaviors without impacting unrelated inputs.
Spotlight: blog post

GraphRAG auto-tuning provides rapid adaptation to new domains
GraphRAG uses LLM-generated knowledge graphs to substantially improve complex Q&A over retrieval-augmented generation (RAG). Discover automatic tuning of GraphRAG for new datasets, making it more accurate and relevant.
To keep LLMs up to date without expensive training, model editing has recently been proposed as a paradigm for making targeted updates to big models. Most model editors update a model once, injecting a batch of corrections. But mistakes are often discovered sequentially over time and must be corrected quickly. In other words, lifelong model editing where a stream of mistakes are encountered and must be addressed immediately is essential when the models are deployed. This requires making many edits sequentially, a setting in which existing editors are known to fail. Success here means correcting all edits in sequence, without forgetting old fixes and without decaying performance on unrelated inputs. But what exactly is an edit? In Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors, three types of edits are considered:
- Updating factual knowledge. Let’s say we have a pre-trained question-answering model: We pass questions in, and the model returns answers. But as the world changes, these answers become outdated. For example, the answer to “Who is the president of the U.S.?” should change after an election. Therefore, an edit is a tuple – or an ordered sequence of values – containing a question (e.g., “Who is the president of the U.S.?”) and the correct answer (e.g., “Biden”) for the question.
- Keeping up with flipping labels. Ground truth in classification tasks can change over time. For example, when U.S. courts use new language to describe existing topics, a document’s correct label can change. In such a case, a model trained on the old labels must be corrected. Targeted edits are especially important when only specific types of data are relabeled, which is common. In this case, an edit is a paired input (e.g., court document) and a new label (e.g., topic).
- Fabrication and incoherence in LLMs. A key challenge in using LLMs is avoiding instances where they generate language that is ungrounded in the context or reality. But this might happen more in some models than others. Therefore, when it does happen, the ensuing edit should be as small as possible. To explore the effectiveness of this approach, mitigating this problem when generating biographies of famous people was considered. Upon identifying hand-annotated fabrications, the LLM was edited to instead produce corresponding sentences from real Wikipedia articles. In this case, an edit is a prompt and a corresponding response, which the existing model finds unlikely.
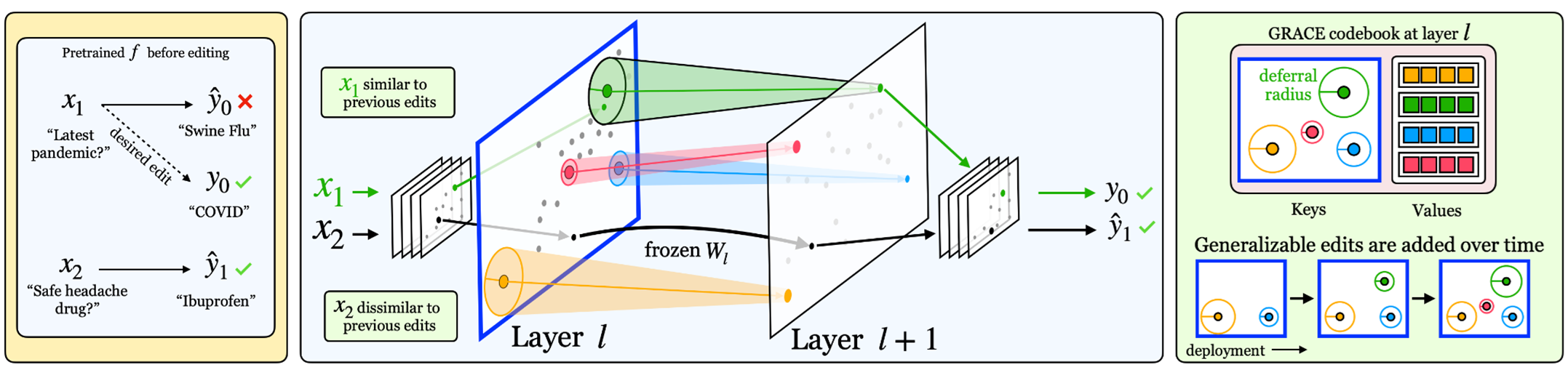
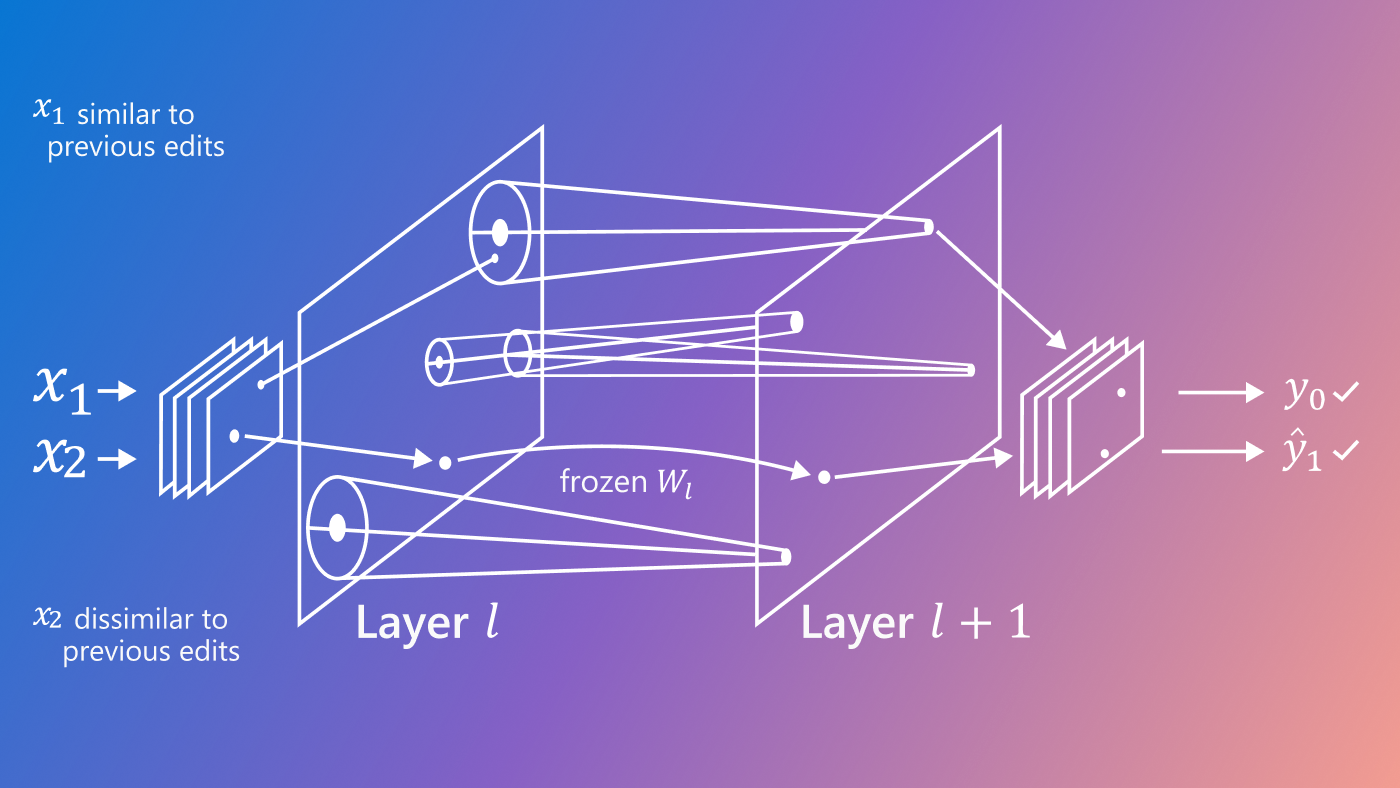
To make cost-effective edits to LLMs, we propose an approach referred to as General Retrieval Adaptors for Continual Editing, or GRACE. GRACE is the first method to enable thousands of sequential edits to any pre-trained model architecture using only streaming errors. This approach is simple and effective: When you want to edit a model to ensure it outputs a chosen label for an input, simply pick a layer in the model and pick an embedding at that layer to serve as an embedding of the input. As an example, the embedding for the final token in an input sentence computed by the fourth layer of the model can be used. Then, this embedding is cached and a new embedding is learned such that if the new is substituted for the old embeddings, the model produces the desired response. The original embedding is referred to as a key, and the learned embedding as a value. Learning the value is straightforward via gradient descent. The key and value are then stored in a codebook, which acts as a dictionary. If you then pass in a new input to the model, after computing its embedding, referred to as a query, new queries can be compared to existing keys. If a query matches a key, one can look up the value and apply the edit. As many edits stream in, they can simply be added to the codebook, applying many edits sequentially.
But isn’t this just memorization? How can generalizable edits be achieved without memorizing every new input? Instead of always adding new keys, every new key is paired with an influence radius, which is a ball surrounding any new key with a radius of ε. Then, if any query lands inside this ε-ball, the key’s corresponding value is retrieved and the edit is applied. Thus, inputs that are similar to any cached edits will also be updated. Occasionally, when creating a new key, its ε-ball may conflict with another key. In this case, when the conflicting keys have different values, their ε-balls are set to just barely touch. If they have the same values, the existing key’s ε are increased to include the new input. Tuning ε helps achieve small codebooks that are generalizable and can successfully make thousands of edits in a row.
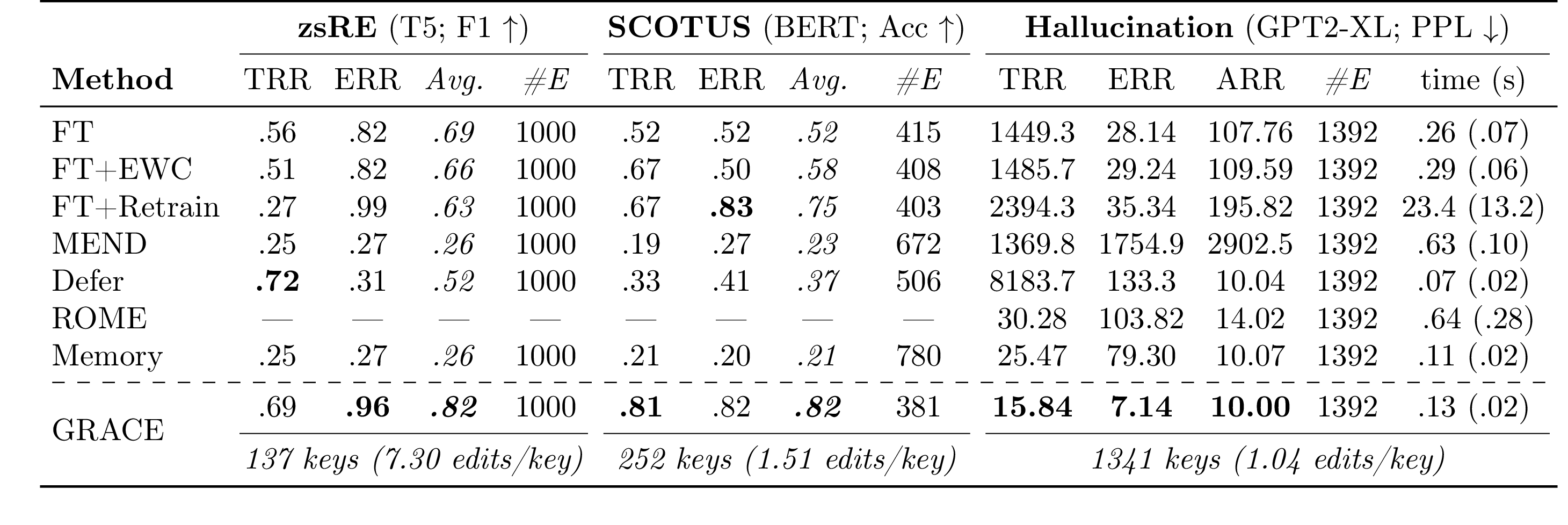
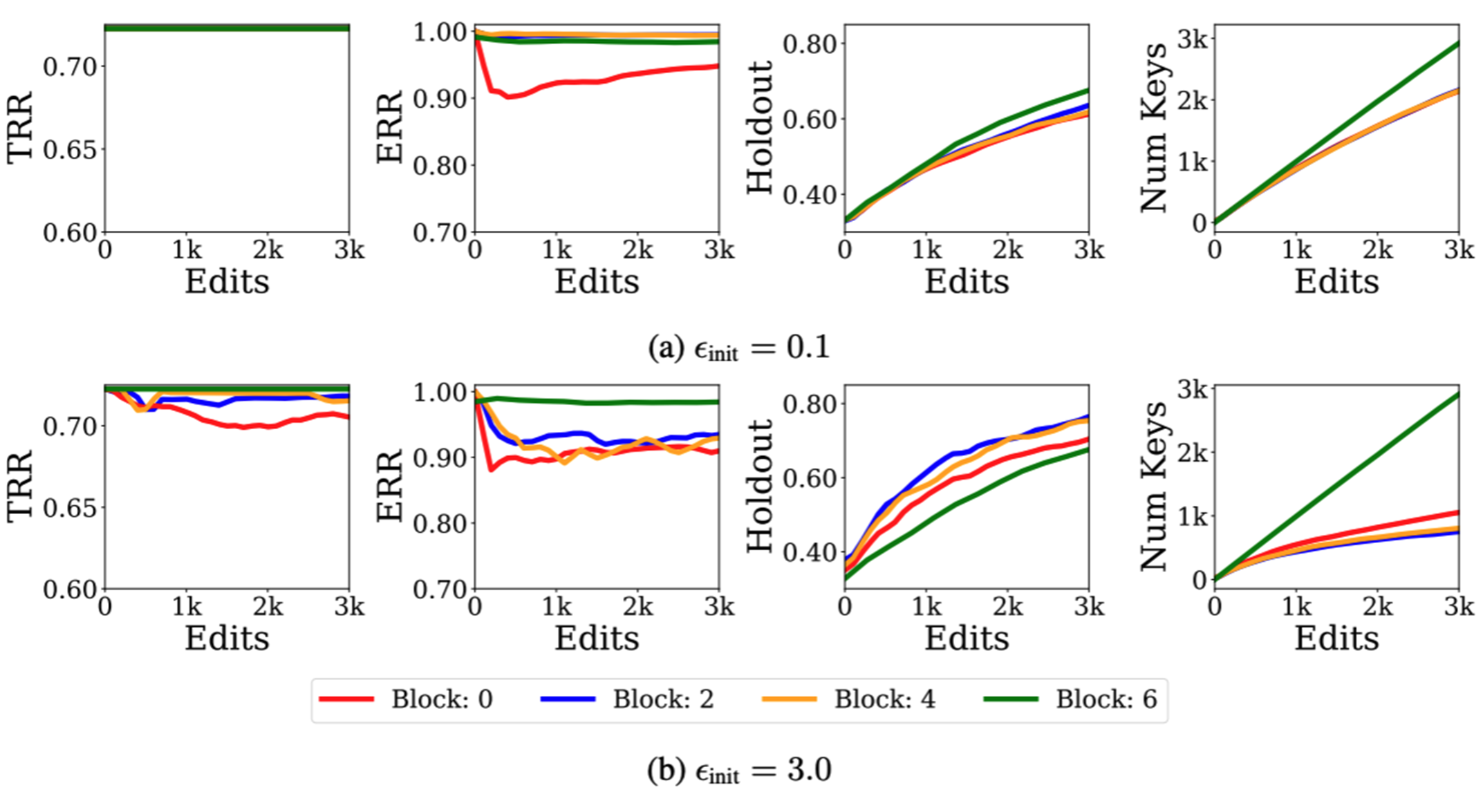
To compare GRACE’s capability with existing methods to make generalizable edits, two bidirectional models (T5 and BERT) and one autoregressive model (GPT2-XL) were used. For question-answering (QA), T5 was used along with a QA dataset (opens in new tab) that includes questions targeted for relation extraction. Twenty rephrased versions of each question were extracted, 10 of them were used during editing and the other 10 as unseen holdouts. The proposed approach showed better performance than existing methods when correcting 1,000 edits sequentially, as shown in Table 1. It used only 137 keys to make the edits, which shows the efficiency of the proposed method. This level of generalization is better than prior work and shows promising potential for correcting future mistakes. The proposed approach can also successfully edit a BERT model that was trained on U.S. Supreme Court documents (opens in new tab) from before 1992 and tested on documents after 1992 for which the label distribution shifted. An experiment was also conducted using GRACE with an autoregressive model, GPT2-XL, to edit mistakes related to fabrication, which were promising encouraging long sequences of edits. For example, when asked to generate a biography of Brian Hughes, GRACE successfully encouraged GPT2-XL to respond: “Brian Hughes (born 1955) is a Canadian guitarist whose work draws from both the smooth jazz and world music genres,” which exactly matches the requested biography using only one cached value. Another interesting observation was that GRACE edits were robust to the choice of edited layer, though later layers were harder to edit. Further, a clear balance was observed between memorization and generalization when choosing ε, as shown in Figure 2. Finally, a key feature of GRACE is that the codebook is detached from the pre-trained model, leaving its weights untouched. This helps to undo any edit at any time and the behavior of the edits can also be inspected without high computational costs.
Summary
GRACE presents a different perspective for model editing, where representations are directly modified and transformations are cached sequentially. Edits can be done thousands of times sequentially, where a small set of codebooks are maintained throughout the editing. This step reduces the gap for deployment needs of real-world applications where edits are discovered over time and should be addressed in a cost-effective manner. By correcting behaviors efficiently and expanding sequential editing to other model properties, like fairness and privacy, this work can potentially enable a new class of solutions for adapting LLMs to meet user needs over long deployment lifetimes.