

Over the past decade, machine learning systems have begun to play a key role in many high-stakes decisions: Who is interviewed for a job? Who is approved for a bank loan? Who receives parole? Who is admitted to a school?
Human decision makers are susceptible to many forms of prejudice and bias, such as those rooted in gender and racial stereotypes. One might hope that machines would be able to make decisions more fairly than humans. However, news stories and numerous research studies have found that machine learning systems can inadvertently discriminate against minorities, historically disadvantaged populations and other groups.
In essence, this is because machine learning systems are trained to replicate decisions present in the data with which they are trained and these decisions reflect society’s historical biases.
PODCAST SERIES

AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
Naturally, researchers want to mitigate these biases, but there are several challenges. For example, there are many different definitions of fairness. Should the same number of men and women be interviewed for a job or should the number of men and women interviewed reflect the proportions of men and women in the applicant pool? What about nonbinary applicants? Should machine learning systems even be used in hiring contexts? Answers to questions like these are non-trivial and often depend on societal context. On top of that, re-engineering existing machine learning pipelines to incorporate fairness considerations can be hard. How can you train a boosted-decision-tree classifier to respect specific gender proportions? What about other fairness definitions? What about training a two-layer neural network? Or a residual network? Each of these questions can require many months of research and engineering.
Our work, outlined in a paper titled, “A Reductions Approach to Fair Classification (opens in new tab),” presented this month at the 35th International Conference on Machine Learning (ICML 2018 (opens in new tab)) in Stockholm, Sweden, focuses on some of these challenges, providing a provably and empirically sound method for turning any common classifier into a “fair” classifier according to any of a wide range of fairness definitions.
To understand our method (opens in new tab), consider the process of choosing applicants to interview for a job where it is desirable to have an interview pool that is balanced with respect to gender and race—a fairness definition known as demographic parity. Our method can turn a classifier that predicts who should be interviewed based on previous (potentially biased) hiring decisions into a classifier that predicts who should be interviewed while also respecting demographic parity (or another fairness definition).
Such techniques are called “reductions” because they reduce the problem we wish to solve into a different problem—typically a more standard problem for which many algorithms already exist. Our fair learning reduction is, in fact, a special case of a more general reduction for imposing constraints on classifiers.
Our method operates as a game between the classification algorithm and a “fairness enforcer.” The classification algorithm tries to come up with the most accurate classification rule on possibly-reweighted data, while the fairness enforcer checks the chosen fairness definition. The training data is reweighted based on the output of the fairness enforcer and passed back to the classification algorithm. For instance, applicants of a certain gender or race might be upweighted or downweighted, so that the classification algorithm is better able to find a classification rule that is fair with respect to the desired gender or racial proportions. Eventually, this process yields a classification rule that is fair, according to the fairness definition. Moreover, it is also the most accurate among all fair rules, provided the classification algorithm consistently tries to minimize the error on the reweighted data.
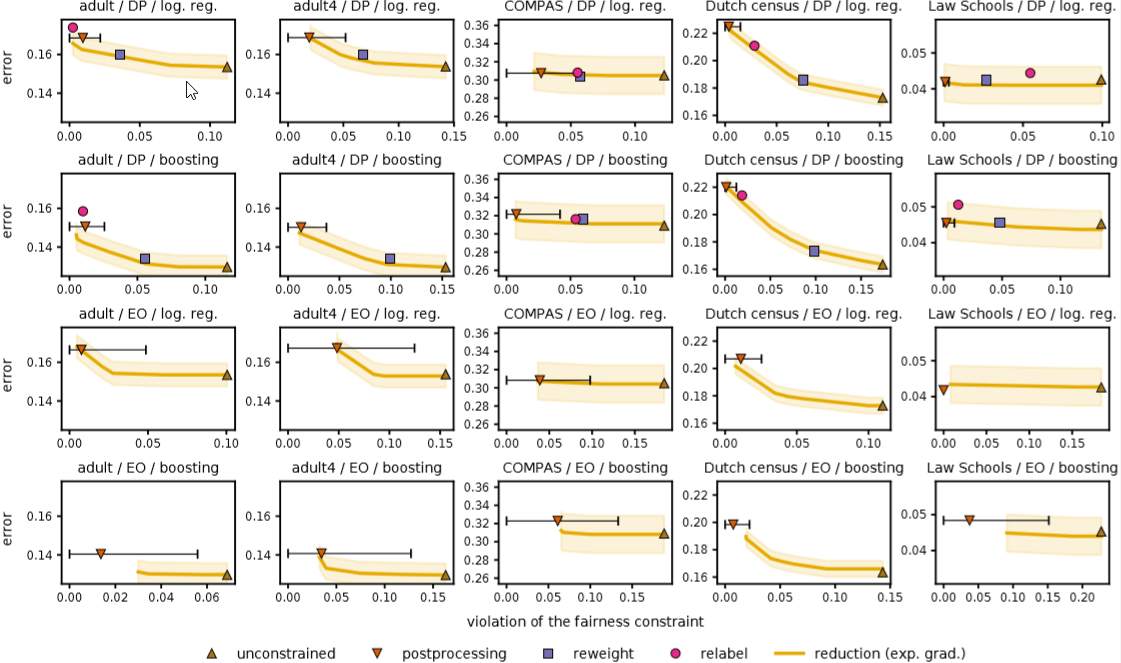
Our algorithm (exp. grad. reduction) matches or outperforms baseline approaches across many data sets, classifier types and fairness measures.
In practice, this process takes about five iterations to yield classification rules that are as good as or better than many previous methods tailored to specific fairness definitions. Our method works with many different definitions of fairness and only needs access to protected attributes, such as gender or race, during training, not when the classifier is deployed in an application. Because our method works as a “wrapper” around any existing classifier, it is easy to incorporate into existing machine learning systems.
Our results contribute to the ongoing conversation about developing “fair” machine learning systems. However, there are many important questions that remain to be addressed. For example, we might not have access to protected attributes at training time or might not want to commit to a single definition of fairness. More fundamentally, in order to effectively mitigate impacts of historical bias, it might be insufficient to impose a quantitative definition of fairness; it might be necessary to systematically collect additional data and monitor the effects of decisions over time, or even avoid the use of machine learning systems in some domains.



