

At a glance
- Microsoft Research releases PazaBench and Paza automatic speech recognition models, advancing speech technology for low resource languages.
- Human-centered pipeline for low-resource languages: Built for and tested by communities, Paza is an end-to-end, continuous pipeline that elevates historically under-represented languages and makes speech models usable in real-world, low-resource contexts.
- First-of-its-kind ASR leaderboard, starting with African languages: Pazabench is the first automatic speech recognition (ASR) leaderboard for low-resource languages. Launching with 39 African languages and 51 state-of-the-art models, it tracks three key metrics across leading public and community datasets.
- Human-centered Paza ASR models: Minimal data, fine-tuned ASR models grounded in real-world testing with farmers on everyday mobile devices, covering six Kenyan languages: Swahili, Dholuo, Kalenjin, Kikuyu, Maasai, and Somali.
According to the 2025 Microsoft AI Diffusion Report approximately one in six people globally had used a generative AI product. Yet for billions of people, the promise of voice interaction still falls short, and whilst AI is becoming increasingly multilingual, a key question remains: Do these models actually work for all languages and the people who rely on them? This challenge is one we first confronted through Project Gecko—a collaboration between Microsoft Research and Digital Green (opens in new tab), where field teams across Africa and India focused on building usable AI tools for farmers.
Gecko revealed how often speech systems fail in real‑world, low‑resource environments—where many languages go unrecognized and non‑Western accents are frequently misunderstood. Yet speech remains the primary medium of communication globally. For communities across Kenya, Africa, and beyond, this mismatch creates cascading challenges: without foundational data representing their languages and cultures, innovation stalls, and the digital and AI divides widen.
Paza addresses this with a human-centered speech models pipeline. Through PazaBench, it benchmarks low-resource languages using both public and community-sourced data, and through Paza models, it fine-tunes speech models to deliver outsized gains in mid- and low-resource languages, evaluating with community testers using real devices in real contexts. Upcoming playbooks complement this work by sharing practical guidance on dataset creation, fine-tuning approaches with minimal data and evaluation considerations, introducing a continuous pipeline that enables researchers and practitioners to build and evaluate systems grounded in real human use.
How Project Gecko informed Paza’s design
In addition to building cost-effective, adaptable AI systems, the extensive fieldwork on Project Gecko highlighted an important lesson: Building usable speech models in low‑resource settings is not only a data problem, but also a design and evaluation problem. For AI systems to be useful, they must work in local languages, support hands‑free interaction through voice, text, and video, and deliver information in formats that fit real-world environments, that is, on low-bandwidth mobile devices, in noisy settings, and for varying literacy levels.
These insights shaped the design of Paza, from the Swahili phrase paza sauti meaning “to project,” or “to raise your voice.” The name reflects our intent: rather than simply adding more languages to existing systems, Paza is about co-creating speech technologies in partnership with the communities who use them. Guided by this principle, Paza puts human use first, which enables model improvement.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
PazaBench: The first ASR leaderboard for low-resource languages
PazaBench is the first automatic speech recognition (ASR) leaderboard dedicated to low‑resource languages. It launches with initial coverage for 39 African languages and benchmarks 52 state‑of‑the‑art ASR and language models, including newly released Paza ASR models for six Kenyan languages. The platform aggregates leading public and community datasets from diverse styles of speech including conversational, scripted read aloud, unscripted, broadcast news, and domain-specific data—into one easy‑to‑explore platform per language. This makes it easier for researchers, developers, and product teams to easily assess which models perform best across underserved languages and diverse regions, understand trade-offs between speed and accuracy while identifying where gaps persist.
PazaBench tracks three core metrics:
- Character Error Rate (CER) which is important for languages with rich word forms, where meaning is built by combining word parts, therefore errors at the character level can significantly impact meaning
- Word Error Rate (WER) for word-level transcript accuracy
- RTFx (Inverse Real‑Time Factor) which measures how fast transcription runs relative to real‑time audio duration.
More than scores, PazaBench standardizes evaluation to prioritize dataset gaps, identify underperforming languages, and highlight where localized models beat wider coverage ASR models—offering early evidence of the value of African‑centric innovation.
To contribute to the benchmark, request additional language evaluation on the leaderboard.
Paza ASR Models: Built with and for Kenyan languages
The Paza ASR models consist of three fine-tuned ASR models built on top of state‑of‑the‑art model architectures. Each model targets Swahili, a mid-resource language and five low‑resource Kenyan languages; Dholuo, Kalenjin, Kikuyu, Maasai and Somali. The models are fine-tuned on public and curated proprietary datasets.
Fine‑tuning the three models allowed us to explore supportive approaches toward a shared goal: building speech recognition systems that are usable for local contexts starting with the six Kenyan languages and bridging the gaps of multi-lingual and multi-modal video question and answering through the MMCT agent. (opens in new tab)
Early versions of two models in Kikuyu and Swahili were deployed on mobile devices and tested directly with farmers in real‑world settings, enabling the team to observe how the models performed with everyday use. Farmers provided in‑the‑moment feedback on accuracy, usability, and relevance, highlighting where transcripts broke down, which errors were most disruptive, and what improvements would make the models more helpful in practice. This feedback loop directly informed subsequent fine‑tuning, ensuring model improvements were driven not only by benchmark scores, but by the needs and expectations of the communities they are intended to serve.
Here is how Paza models compare to three state-of-the-art ASR models today:


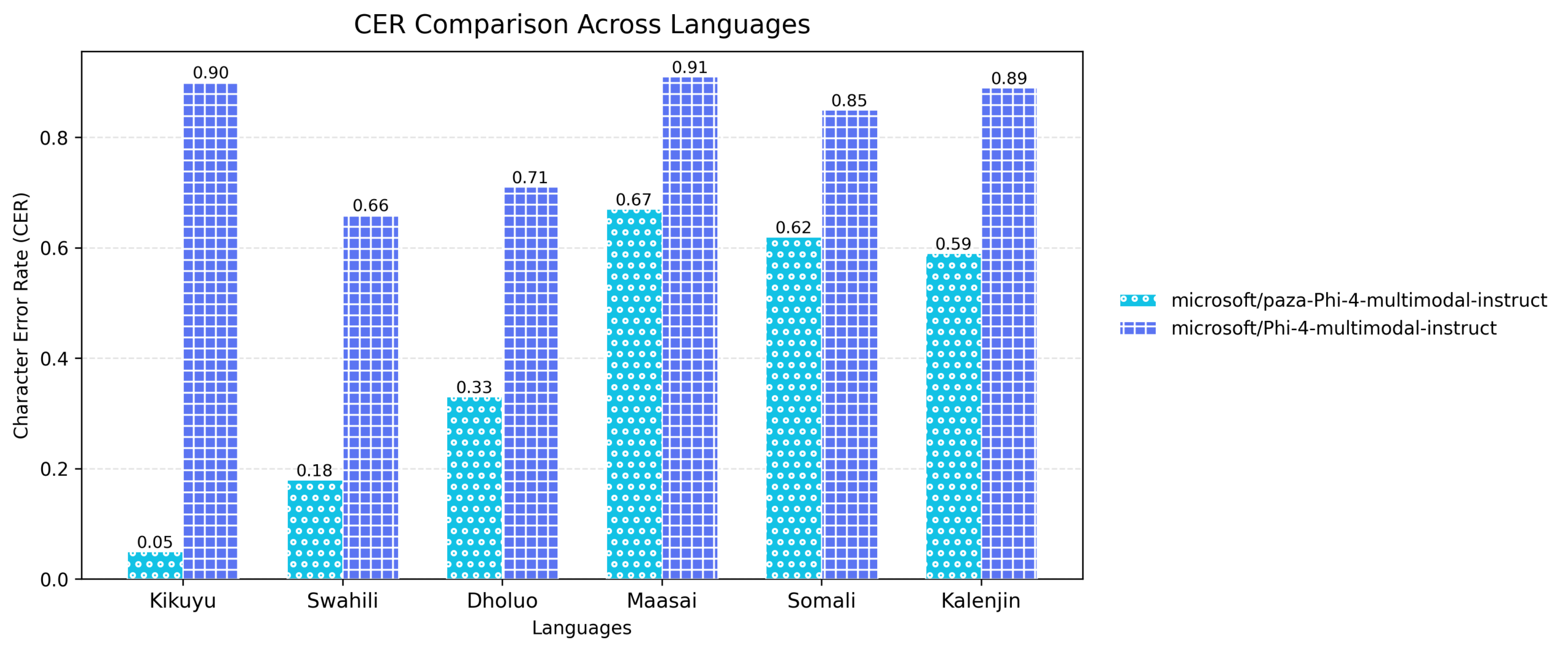
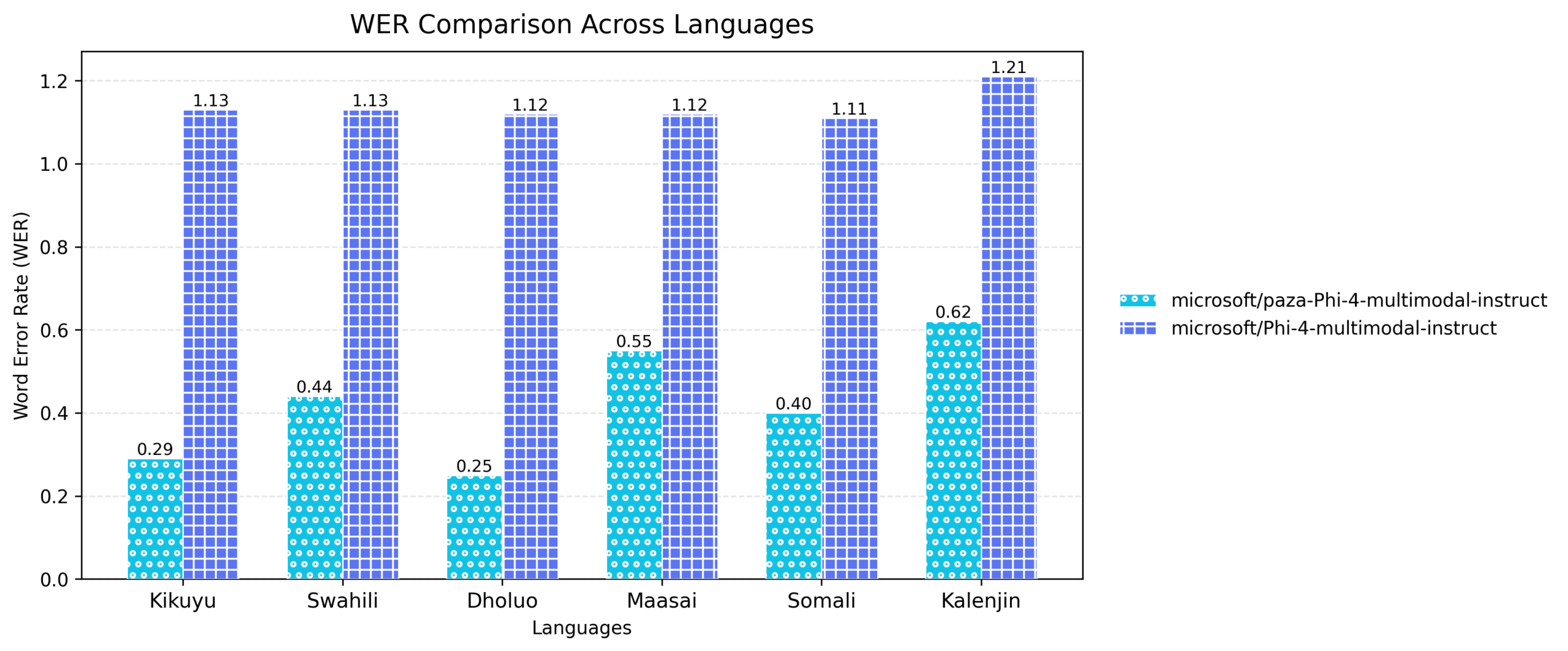
1) Paza‑Phi‑4‑Multimodal‑Instruct
Microsoft’s Phi‑4 multimodal‑instruct (opens in new tab) is a next‑generation small language model built to reason across audio, text, and vision. With Paza, we extend its audio capabilities, adapting a powerful multimodal architecture into a high‑quality automatic speech recognition (ASR) system for low‑resource African languages.
Fine‑tuned on unified multilingual speech datasets, the model was optimized specifically for transcription in the six languages. The model preserves its underlying transformer architecture and multi-modal capabilities, while selectively fine-tuning only the audio‑specific components, enabling strong cross‑lingual generalization.
As the results below show, this model delivers consistent improvements in transcription quality across all six languages.
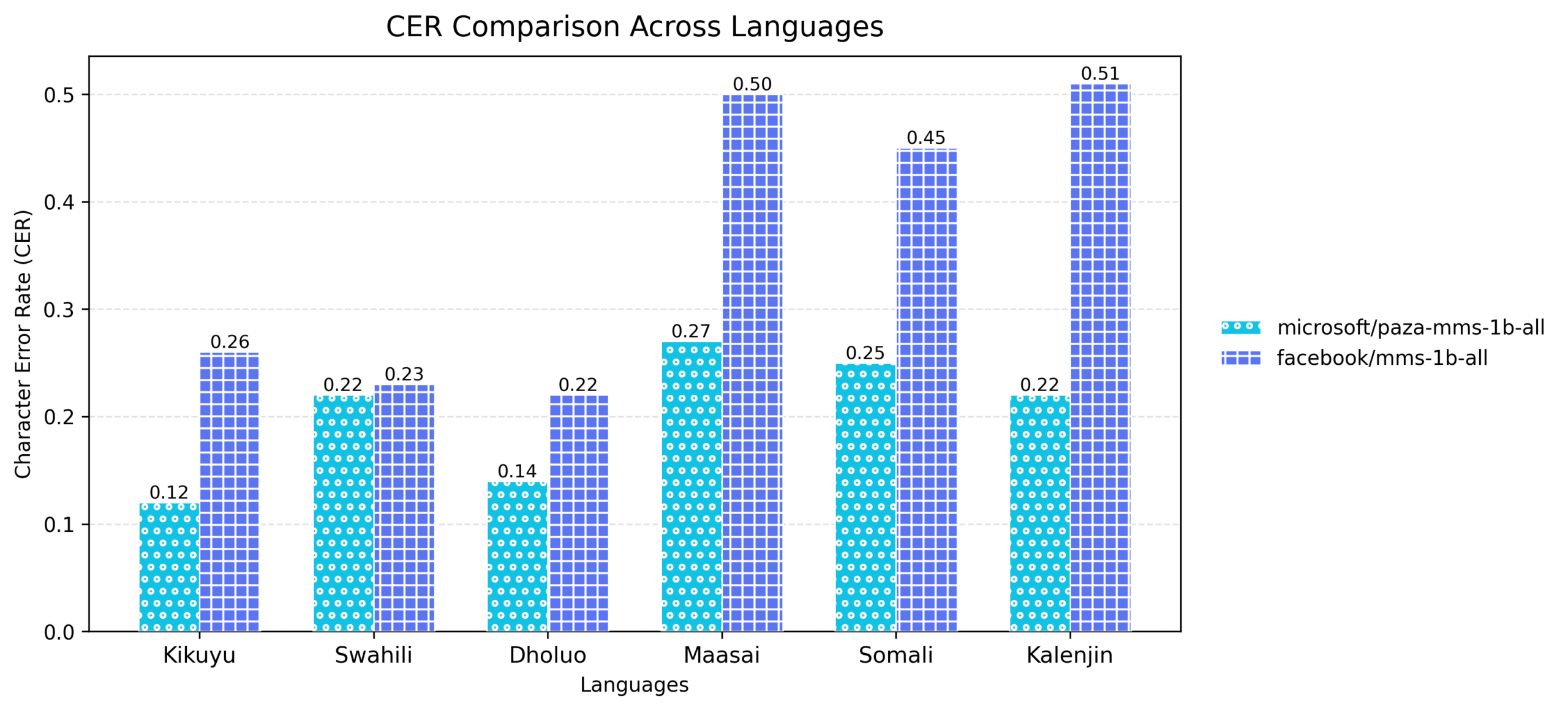
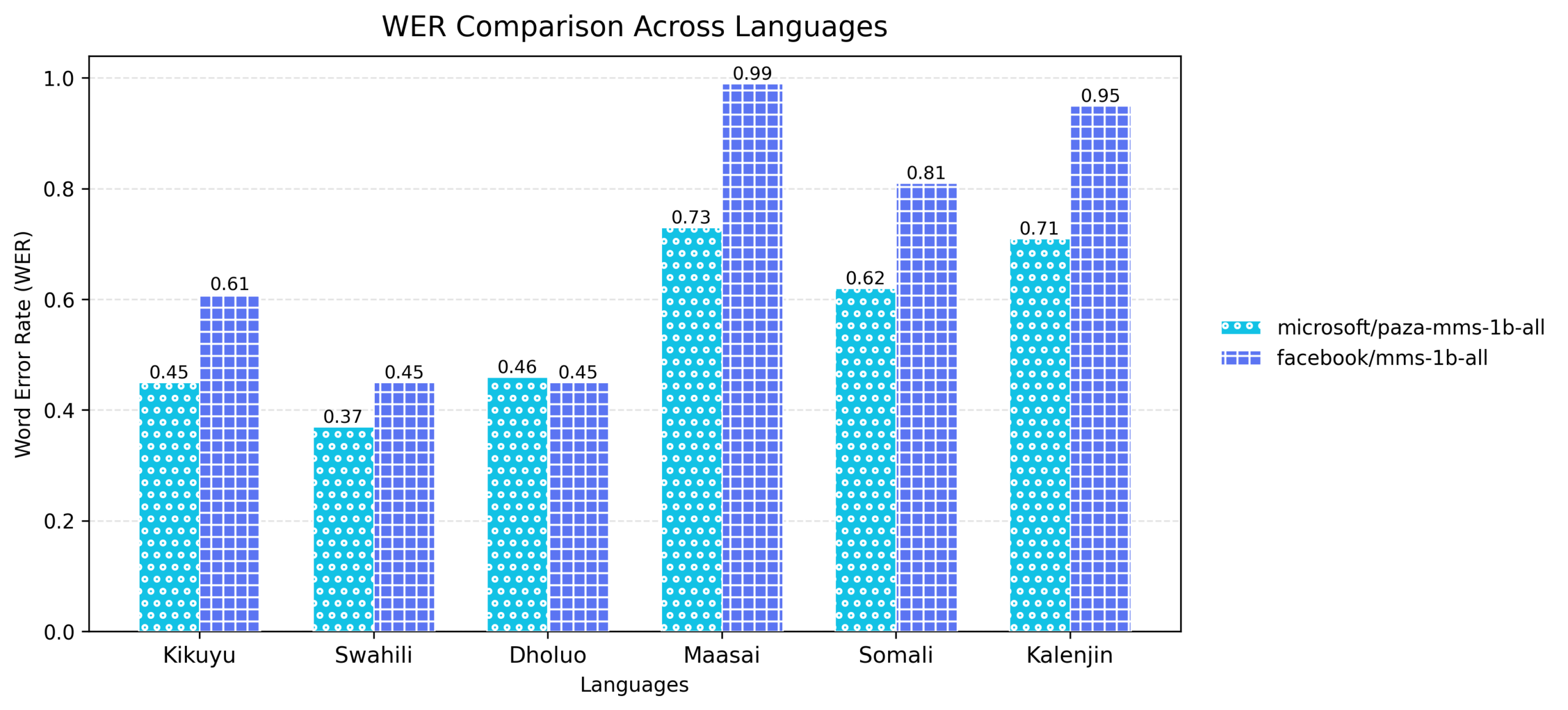
2) Paza‑MMS‑1B‑All
This model is fine-tuned on Meta’s mms-1b-all model, which employs a large-scale Wav2Vec2.0-style encoder with lightweight language-specific adapters to enable efficient multilingual specialization. For this release, each of the six language adapters was fine‑tuned independently on curated low‑resource datasets, allowing targeted adaptation while keeping the shared encoder largely frozen.
As shown in the figures below, this model improves transcription accuracy while maintaining the model’s strong cross‑lingual generalization.
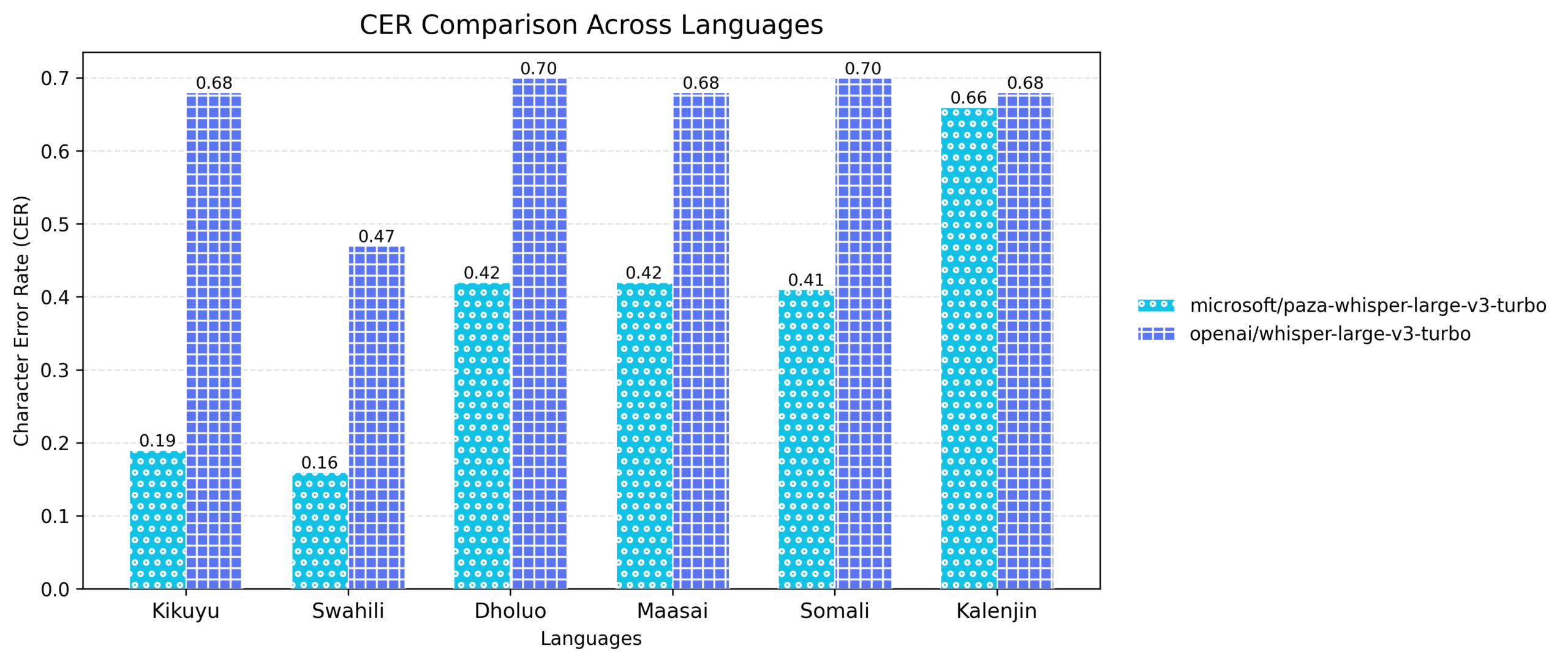
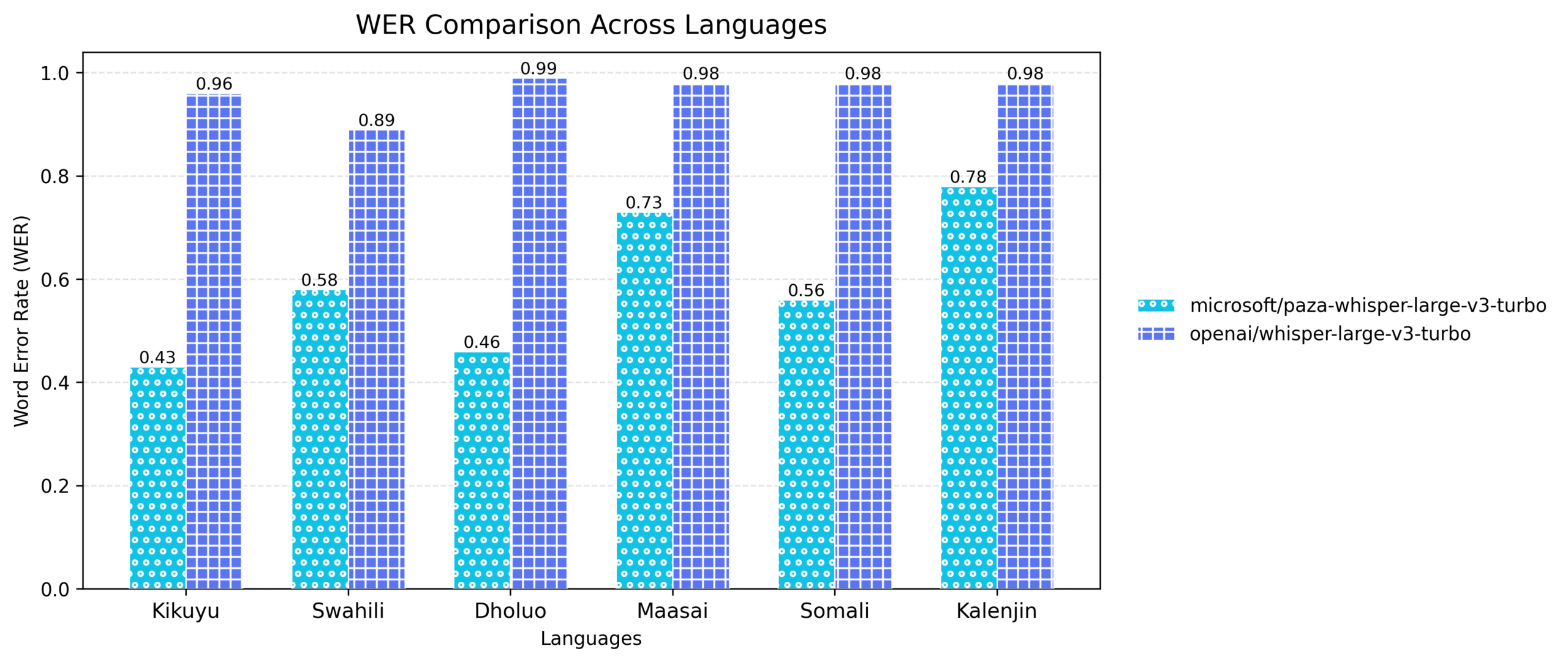
3) Paza‑Whisper‑Large‑v3‑Turbo
This model is finetuned on OpenAI’s whisper-large-v3-turbo base model. Whisper is a transformer-based encoder–decoder model which delivers robust automatic speech recognition (ASR) capabilities. This model was fine‑tuned on the entire unified multilingual ASR dataset, on the mentioned six languages, to encourage cross-lingual generalization. In addition, an extra post‑processing step was applied to address the known Whisper hallucination failure modes, improving transcription reliability.
As shown below, this release achieves improved transcription accuracy while retaining Whisper’s robustness.
Where do we go from here
AI is reshaping how the world communicates. Designing with people, not just for them, means looking beyond the languages that are already well‑served. We plan to expand PazaBench beyond African languages and evaluate state‑of‑the‑art ASR models across more low‑resource languages globally. The Paza ASR models are an early step; truly supporting small and under‑represented languages requires dedicated datasets, strong local partnerships, and rigorous evaluation. Meaningful progress depends on sustained collaboration with the communities who speak these languages, and expanding responsibly means prioritizing depth and quality over broad but shallow coverage.
As we continue this work, we’re distilling our methods into a forthcoming playbook to help the broader ecosystem curate datasets, fine‑tune responsibly, and evaluate models in real‑world conditions. And we’re not stopping at speech—additional playbooks will guide teams building AI tools and applications for multilingual, multicultural contexts, and give them practical recommendations for deploying across diverse communities.
Together, these guides—grounded in technical advances and community‑driven design—share our learnings to help researchers, engineers, and designers build more human‑centered AI systems.
Acknowledgements
The following researchers played an integral role in this work: Najeeb Abdulhamid, Felermino Ali, Liz Ankrah, Kevin Chege, Ogbemi Ekwejunor-Etchie, Ignatius Ezeani, Tanuja Ganu, Antonis Krasakis, Mercy Kwambai, Samuel Maina, Muchai Mercy, Danlami Mohammed, Nick Mumero, Martin Mwiti, Stephanie Nyairo, Millicent Ochieng and Jacki O’Neill.
We would like to thank the Digital Green (opens in new tab) team—Rikin Gandhi, Alex Mwaura, Jacqueline Wang’ombe, Kevin Mugambi, Lorraine Nyambura, Juan Pablo, Nereah Okanga, Ramaskanda R.S, Vineet Singh, Nafhtari Wanjiku, Kista Ogot, Samuel Owinya and the community evaluators in Nyeri and Nandi, Kenya — for their valuable contributions to this work.
We extend our gratitude to the creators, community contributors, and maintainers of African Next Voices Kenya (opens in new tab), African Next Voices South Africa (opens in new tab), ALFFA (opens in new tab), Digigreen (opens in new tab), Google FLEURS (opens in new tab), Mozilla Common Voice (opens in new tab) and Naija Voices (opens in new tab) whose efforts have been invaluable in advancing African languages speech data.





