
At a glance
- Imitation learning becomes easier when an AI agent understands why an action is taken.
- Predictive Inverse Dynamics Models (PIDMs) predict plausible future states, clarifying the direction of behavior during imitation learning.
- Even imperfect predictions reduce ambiguity, making it clearer which action makes sense in the moment.
- This makes PIDMs far more data‑efficient than traditional approaches.
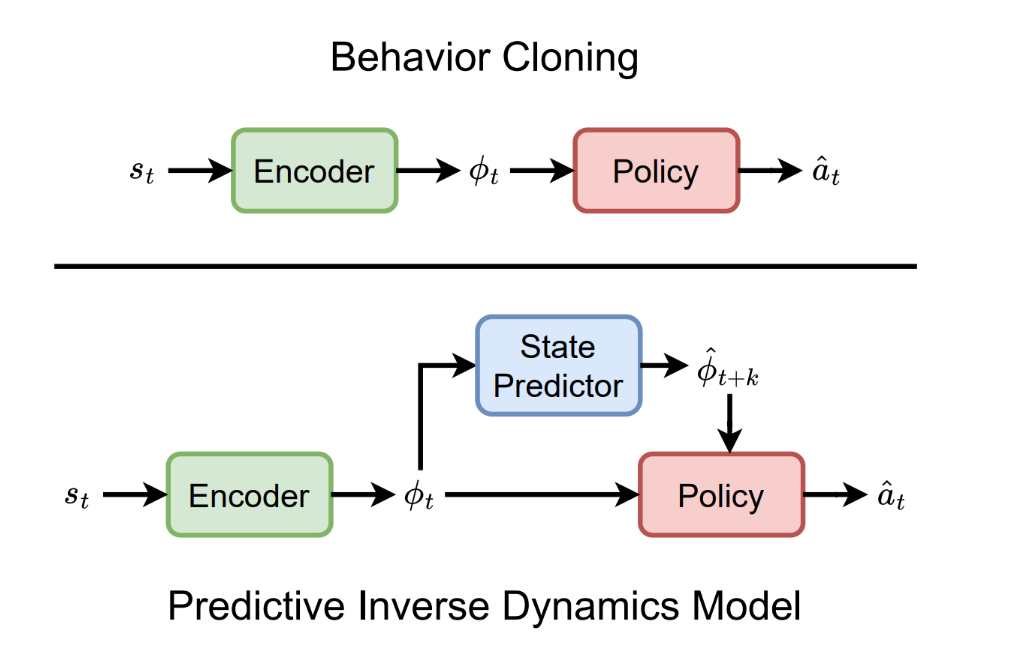
Imitation learning teaches AI agents by example: show the agent recordings of how people perform a task and let it infer what to do. The most common approach, Behavior Cloning (BC), frames this as a simple question: “Given the current state of the environment, what action would an expert take?”
In practice, this is done through supervised learning, where the states serve as inputs and expert actions as outputs. While simple in principle, BC often requires large demonstration datasets to account for the natural variability in human behavior, but collecting such datasets can be costly and difficult in real-world settings.
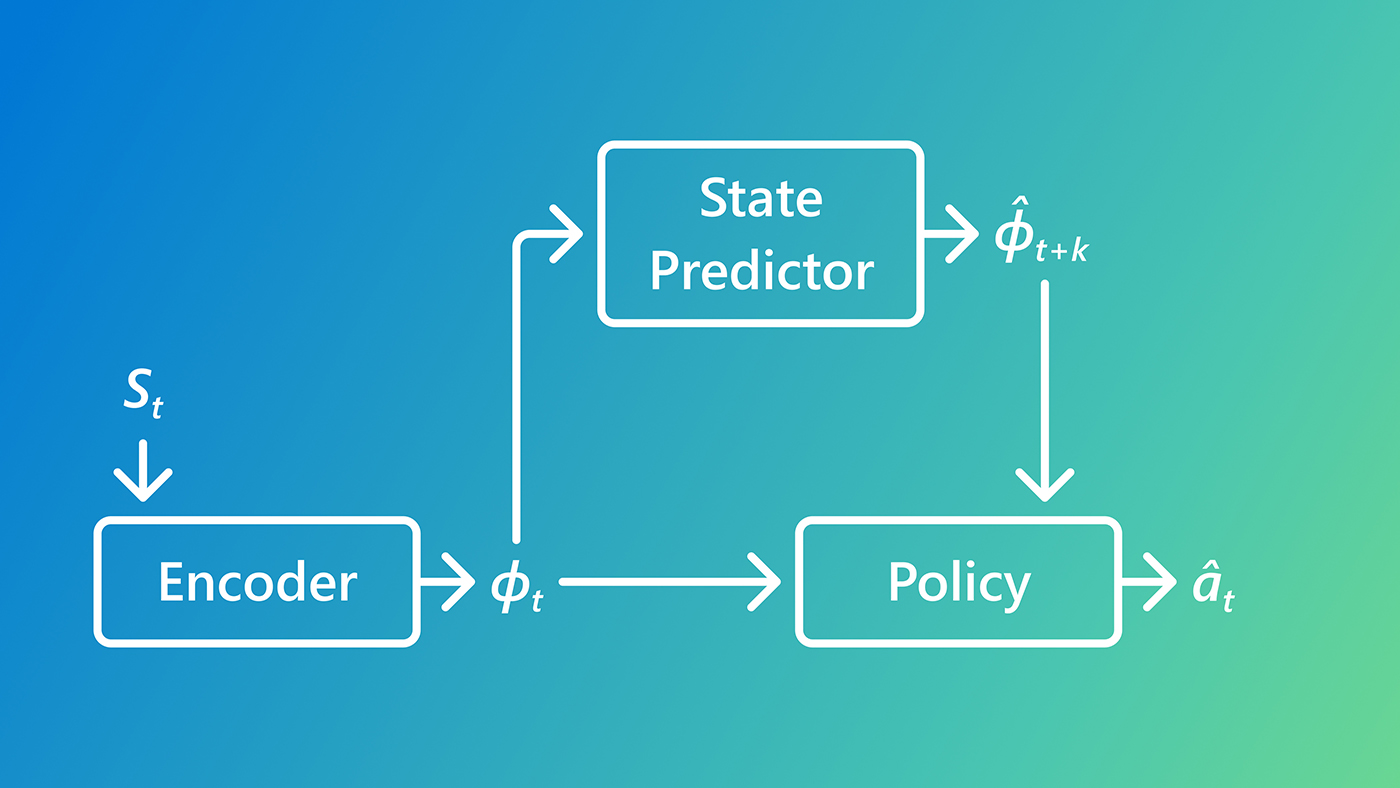
Predictive Inverse Dynamics Models (PIDMs) offer a different take on imitation learning by changing how agents interpret human behavior. Instead of directly mapping states to actions, PIDMs break down the problem into two subproblems: predicting what should happen next and inferring an appropriate action to go from the current state to the predicted future state. While PIDMs often outperform BC, it has not been clear why they work so well, motivating a closer look at the mechanisms behind their performance.
In the paper, “When does predictive inverse dynamics outperform behavior cloning?” we show how this two-stage approach enables PIDMs to learn effective policies from far fewer demonstrations than BC. By grounding the selection process in a plausible future, PIDMs provide a clearer basis for choosing an action during inference. In practice, this can mean achieving comparable performance with as few as one-fifth the demonstrations required by BC, even when predictions are imperfect.
How PIDMs rethink imitation
PIDMs’ approach to imitation learning consists of two core elements: a model that forecasts plausible future states, and an inverse dynamics model (IDM) that predicts the action needed to move from the present state toward that future. Instead of asking, “What action would an expert take?” PIDMs effectively ask, “What would an expert try to achieve, and what action would lead to it?” This shift turns the information in the current observation (e.g., video frame) into a coherent sense of direction, reducing ambiguity about intent and making action prediction easier.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Real-world validation in a 3D gameplay environment
To evaluate PIDMs under realistic conditions, we trained agents on human gameplay demonstrations in a visually rich video game. These conditions include operating directly from raw video input, interacting with a complex 3D environment in real time at 30 frames per second, and handling visual artifacts and unpredictable system delays.
The agents ran from beginning to end, taking video frames as input and continuously deciding which buttons to press and how to move the joysticks. Instead of relying on a hand-coded set of game variables and rules, the model worked directly from visual input, using past examples to predict what comes next and choosing actions that moved play in that direction.
We ran all experiments on a cloud gaming platform, which introduced additional delays and visual distortions. Despite these challenges, the PIDM agents consistently matched human patterns of play and achieved high success rates across tasks, as shown in Video 1 below and Videos 2 and 3 in the appendix.
Why and when PIDMs outperform BC
Of course, AI agents do not have access to future outcomes. They can only generate predictions based on available data, and those predictions are sometimes wrong. This creates a central trade‑off for PIDMs.
On one hand, anticipating where the agent should be heading can clarify what action makes sense in the present. Knowing the intended direction helps narrow an otherwise ambiguous choice. On the other hand, inaccurate predictions can occasionally steer the model toward the wrong action.
The key insight is that these effects are not symmetric. While prediction errors introduce some risk, reducing ambiguity in the present often matters more. Our theoretical analysis shows that even with imperfect predictions, PIDMs outperform BC as long as the prediction error remains modest. If future states were known perfectly, PIDMs would outperform BC outright.
In practice, this means that clarifying intent often matters more than accurately predicting the future. That advantage is most evident in the situations where BC struggles: where human behavior varies and actions are driven by underlying goals rather than by what is immediately visible on the screen.
BC requires many demonstrations because each example is noisy and open to multiple interpretations. PIDMs, by contrast, sharpen each demonstration by linking actions to the future states they aim to reach. As a result, PIDMs can learn effective action strategies from far fewer examples.
Evaluation
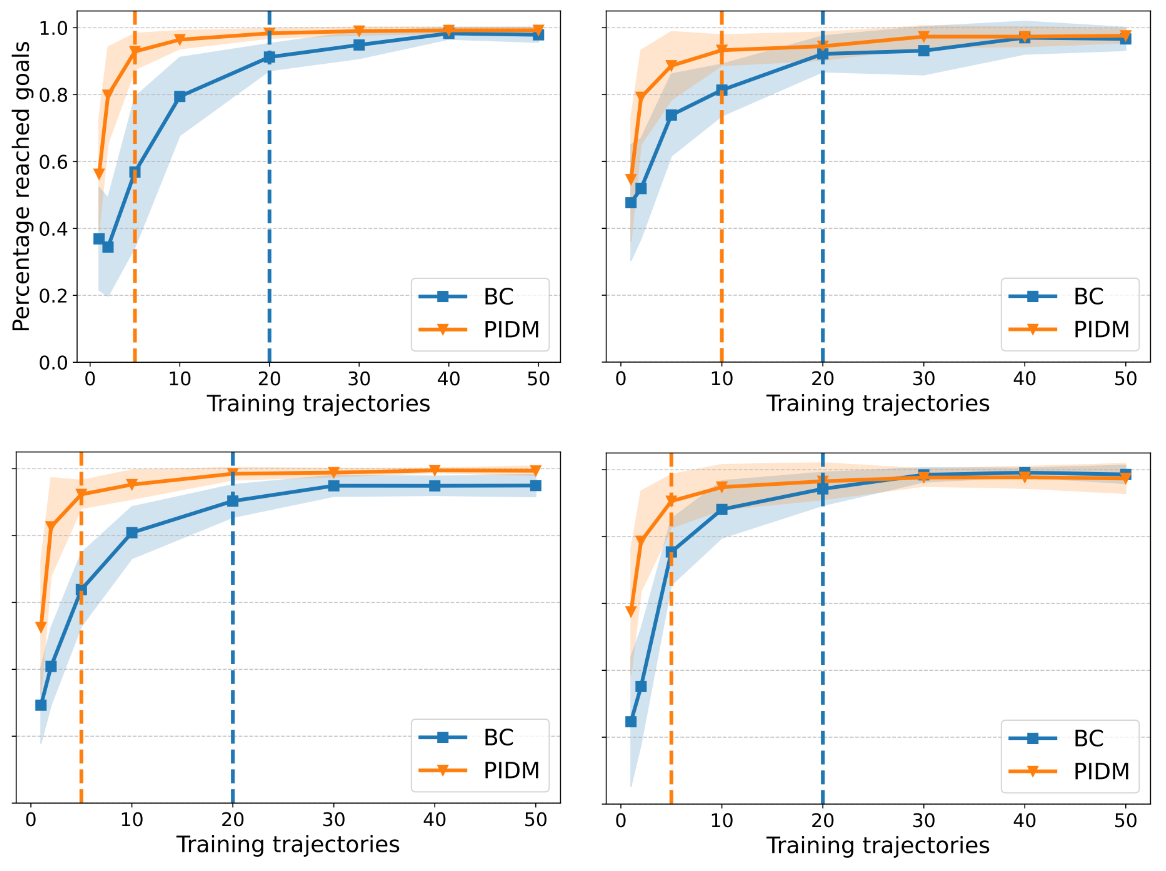
To test these ideas under realistic conditions, we designed a sequence of experiments that begins with a simple, interpretable 2D environment (Video 4 in the appendix) and culminates in a complex 3D video game. We trained both BC and PIDM on very small datasets, ranging from one to fifty demonstrations in the 2D environment and from five to thirty for the 3D video game. Across all tasks, PIDM reached high success rates with far fewer demonstrations than BC.
In the 2D setting, BC needed two to five times more data to match PIDM’s performance (Figure 2). In the 3D game, BC needed 66% more data to achieve comparable results (Video 5 in the appendix).
Takeaway: Intent matters in imitation learning
The main message of our investigation is simple: imitation becomes easier when intent is made explicit. Predicting a plausible future, even an imperfect one, helps resolve ambiguity about which action makes sense right now, much like driving more confidently in the fog when the driver already knows where the road is headed. PIDM shifts imitation learning from pure copying toward goal-oriented action.
This approach has limits. If predictions of future states become too unreliable, they can mislead the model about the intended next move. In those cases, the added uncertainty can outweigh the benefit of reduced ambiguity, causing PIDM to underperform BC.
But when predictions are reasonably accurate, reframing action prediction as “How do I get there from here?” helps explain why learning from small, messy human datasets can be surprisingly effective. In settings where data is expensive and demonstrations are limited, that shift in perspective can make a meaningful difference.