

One challenge with AI algorithmic fairness is that one usually has to know the potential group(s) that an algorithm might discriminate against in the first place. However, in joint work with Maria De-Arteaga, Nathaniel Swinger, Tom Heffernan, and Max Leiserson, we automatically enumerate groups of people that may be discriminated against alongside potential biases. We do this using word embedding, a popular AI tool for processing language. This proves useful for detecting age, gender, religious, and racial biases. The algorithm is designed to capture intersectional biases and to account for the fact that many forms of discrimination—such as racial discrimination—are linked to social constructs that may vary depending on the context, rather than to categories with a fixed definition. In this blog post, we explain the inputs and outputs of our system.
WARNING: This blog post includes offensive associations found by our algorithm. We feel that it is important for AI researchers and practitioners to be aware of them before using them in systems.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
AI researchers and practitioners are concerned that their algorithms could perpetuate biases in the data they are trained on, and they don’t want their systems to discriminate against groups of people that are already disadvantaged. One question I often hear people struggling with is, “How do I know what groups my system might discriminate against in the first place?” Even with a definition of fairness (right now there are too many definitions of fairness (opens in new tab)) to a sensitive group, one must first figure out who the groups are. Obvious groups include race, ethnicity, age, and gender, to name a few. It is really hard to define many of these groups, such as ethnicity, and it might vary based on who the system users are. In a recent project with several collaborators ranging from high school and graduate students to faculty members, we attempt to understand this in word embeddings.
Backing up for a moment, as you may know, word embeddings are often trained on billions of words from the Web. They are an extremely popular technology used in processing language that functions for computers like a dictionary does for people. One of the things people find coolest about word embeddings is that they would answer analogy questions like man:woman :: king:? with queen. One afternoon in early 2016, sitting in our Microsoft Research office in Cambridge, MA, a group of colleagues and I thought of asking another question: man:woman :: doctor😕 and, to our horror, the computer responded with nurse. We then wrote a simple program to generate as many such man:woman analogies as the computer could find. Sure enough, it spit out numerous sexist stereotypes like man:woman :: computer programmer:homemaker. This is especially concerning in light of the widespread use of this technology in AI applications everywhere. We designed an algorithm that reduced the gender bias, but our NeurIPS paper (opens in new tab) also tried to raise awareness in general, because we knew that our even our new embeddings still had plenty of bias beyond gender.
In the new project (opens in new tab), we show how to identify further groups beyond (binary) gender. In particular, we leverage the geometry of the word embeddings to find parallels between clusters of lower-case words and first names. We recover gender groups but also a number of other biases including religious, ethnic, age, and racial groups emerge. Table 1, below, shows 12 groups of names as clustered by the word embedding, along with certain demographic statistics.
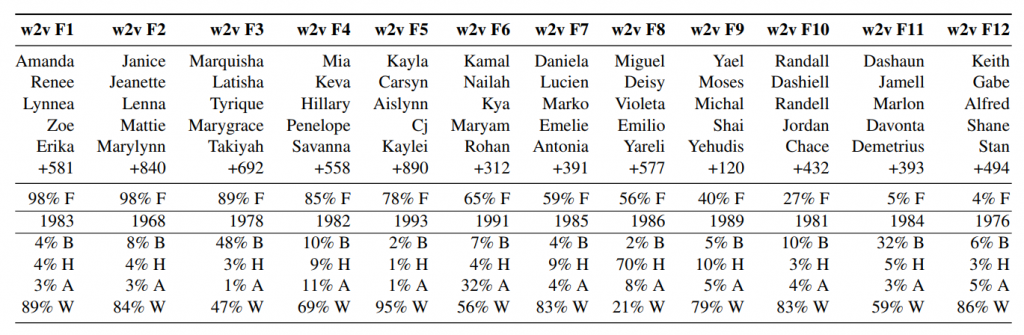
Table 1. A clustering of first names in the Word2Vec embedding trained on Google News (opens in new tab) into 12 groups. Also shown are demographic statistics of names computed (after the fact) from US government sources, including gender (percentage female at birth), birth year, and race (percentage Black, Hispanic, Asian Pacific Islander, and White), showing the groups differ strongly. Personally, although it’s not evident in the percentages, I was surprised to see cluster F9 of clearly Israeli/Jewish names, including several people in my family, simply because there aren’t that many Jewish people out there. Even more concerning are racial groups that are strongly discriminated against in many contexts.
Similar results were found for FastText (opens in new tab) and GloVe (opens in new tab) embeddings. Next, the algorithmic challenge was in identifying statistically significant associations with these name groups. Unfortunately, the algorithm we developed found numerous offensive associations, as seen in Table 2. More specifically, we first found that all common lower-case words naturally clustered into categories of food-related, family-related, and occupation-related words. We then split each word category into the words that had statistically significant associations with one of the name groups. The results are shown in Table 3. For example, in the food category, I saw the stereotypical Israeli food words kosher, hummus, and bagel associated with the Israeli name cluster.

Table 2. The most offensive (as rated by crowdsourcing) associations between groups of names and words that were generated from 3 popular publicly available word embeddings. The associated name groups for w2v can be found in Table 1.
It was appalling how the algorithm produced offensive biases, one after another, against different groups. On the one hand, this is bad news and should cause concern for those haphazardly using Word Embeddings. On the other hand, the silver lining is that it might mean that computers are easier to probe than humans who may feel unbiased. So, in future projects we can hopefully modify word embeddings to reduce and measure the remaining biases.

Table 3. Categories of words (rows—for example, the first row consists of food-related words and the last-row consists of crime-related words) and their associations with the different groups of names from Table 1. Orange cells are biases that were confirmed to be consistent with human stereotypes in a U.S.-based crowdsourcing experiment.
These biases could cause problems in a number of applications. For instance, word embeddings could naively help one match resumes to jobs (just search “resume matching word2vec” on Google Scholar) by noticing things like intelligently matching a “programmer” resume to a job posting for a “software developer”. However, they would also “help” match people to jobs based on their names. And, even more insidiously, we find that even if you remove names from the resumes, the words in the columns in Table 3 are 99% consistent (in some precise sense) without even using the names. For example, the word hostess is closer to volleyball than to cornerback, while cab driver is closer to cornerback than to volleyball in the word2vec embedding. This means that people’s job recommendations might exhibit racial and gender discrimination through proxies that they list on their resumes (for example, sports played in high school).
To learn more, you’re invited to read our paper, “What are the biases in my word embedding?” (opens in new tab) by Nathaniel Swinger, Maria De-Arteaga, Neil Thomas Heffernan IV, Mark DM Leiserson, and Adam Tauman Kalai, featured in the Proceedings of the AIES Conference (opens in new tab), 2019.


