

We are announcing ClimaX, a flexible and generalizable deep learning model for weather and climate science.
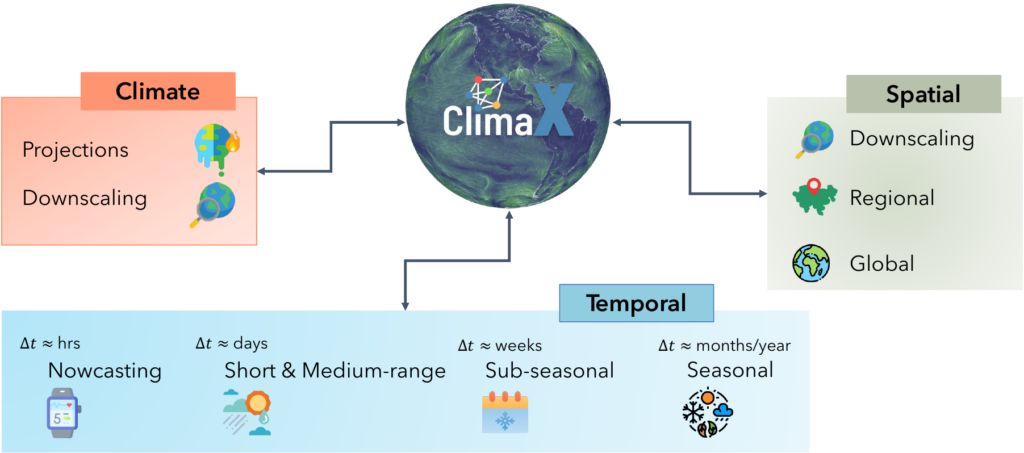
ClimaX is trained using several heterogeneous datasets spanning many weather variables at multiple spatio-temporal resolutions. We show that such a foundational model can be fine-tuned to address a wide variety of climate and weather tasks, including those that involve atmospheric variables and spatio-temporal granularities unseen during pretraining. ClimaX will be made available for academic and research use shortly.
The key insight behind our effort is the realization that all the prediction and modeling tasks in weather and climate science are based on physical phenomena and their interactions with the local and global geography. Consequently, a foundational model that models a multitude of weather and climate variables at many different scales eventually will encode these physical laws and the relevant geographical interactions.
Current state-of-the-art numerical weather and climate models are based on simulations of large systems of differential equations, which relate the flow of energy and matter based on known physics of different Earth systems. Thus, state-of-the-art numerical weather and climate models are usually required to run on large super-computers at high resolutions. Although very successful, these models are known to have weaknesses and limitations both at long- and short-time horizons.
On the other hand, advancements in technology have led to an abundance of data from satellites, radar, and other weather sensors. This data can also provide valuable information for weather and climate modeling, especially at finer temporal and spatial resolutions while potentially accounting for less understood complex physics. However, current large scale numerical weather and climate models have a hard time assimilating this scale of data.
Machine learning (ML) models can provide an alternative tradeoff, benefiting from the scale of both data and compute. Recent attempts at scaling up deep learning systems for short and medium-range weather forecasting have already led to big success, often already matching current state-of-the-art numerical weather models on key variables of interest. However, since most of the ML models are trained for a specific predictive task on specific datasets, they lack the general-purpose utility for Earth system sciences, and are thus not fully grounded in physics.
From a machine learning perspective, the plethora of available data – from direct weather measurements at land, sand, or atmosphere, over multiple decades of re-analyzed weather data at different spatial scales, to physics-informed climate projections for various scenarios – is a fruitful grounding for building fully physics-grounded foundation models for weather and climate modeling. Especially so, since weather and climate data commonly share the same set of equations (although with fairly distinct characteristics).
ClimaX Architecture and Framework
In disciplines such as natural language processing or computer vision, it is well acknowledged that ML models trained to solve a single task using supervised learning are label-hungry during training, and brittle when deployed outside their training distribution. In recent years, pretraining large unsupervised “foundation” models has therefore emerged as a new paradigm, mitigating the supervision bottleneck. Post pretraining, there are many ways to finetune the same model on a shear arbitrary span of tasks with little to none (i.e., zero-shot) additional supervision.
ClimaX follows the pretraining – finetuning paradigm. For pretraining ClimaX, our first key proposal is to go beyond standard homogeneous weather datasets, but rather leverage physics-informed climate simulation datasets, which are abundant due to various climate simulations from multiple groups. By only using a tiny fraction of the available datasets, we show that the heterogeneity in these datasets is already enough to serve as a rich and plentiful pretraining dataset.
But to do so, we need a model architecture that can aptly embrace the heterogeneity of those climate datasets, which are highly multimodal, as observations typically correspond to many different, unbounded variables. Moreover, many observational datasets are irregular in the sense that they differ in their spatiotemporal coverage, corresponding to different subsets of atmospheric variables.
At its core, ClimaX is a multi-dimensional image-to-image translation architecture that is based on Vision Transformers (ViT). ViT-based architectures are especially well suited for modeling weather and climate phenomena since they naturally tokenize the spatial nature of multiscale data akin to different spatial-temporal inputs, and additionally offer the opportunity to extend tokenization towards a wide range of multi-channel features. However, two fundamental changes are needed to repurpose the ViT architecture towards ClimaX: variable tokenization and variable aggregation.
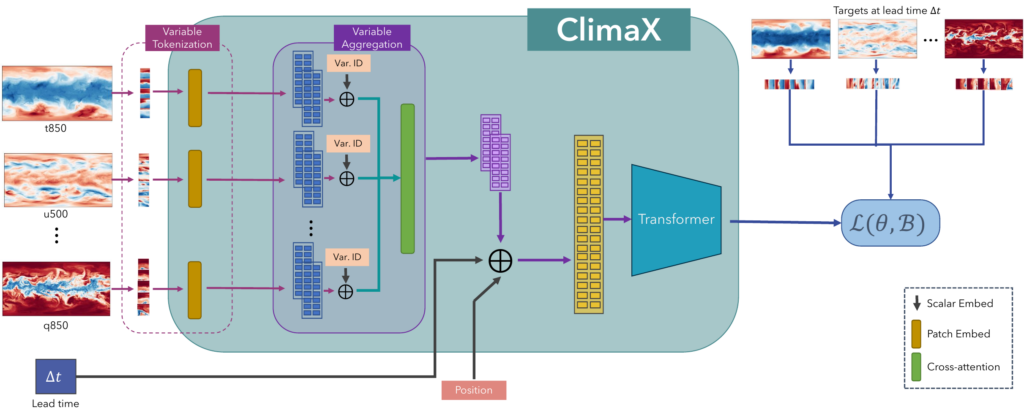
Variable tokenization: The standard ViT tokenization scheme for image data divides the input into equally sized patches and flattens these patches over width, height, and channel dimension into a vector. However, this is not that straight forward for climate and weather data, where the number of physical variables can vary between different datasets. Concretely, in our case each climate pretraining data subset contains simulated data of different models, and thus has different underlying variables. We therefore propose variable tokenization which treats variables as separate modalities to enable more flexible training even with irregular datasets.

Variable aggregation: Variable tokenization comes with two inherent problems. First and foremost, it yields sequences which increase linearly with the number of input variables, which is computationally not feasible as input to self-attention layers of the ViT. Secondly, the input is prone to contain tokens of different variables with very different physics groundings. We therefore propose variable aggregation, a cross-attention operation that outputs an equally sized embedding vector for each spatial location.

Fine-Tuning for various downstream tasks
We highlight the performance of ClimaX on various weather and climate related downstream tasks, which we categorize into weather forecasting (global, regional, sub-seasonal and seasonal), climate projections and climate downscaling. ClimaX is highly flexible due to its four learnable components:
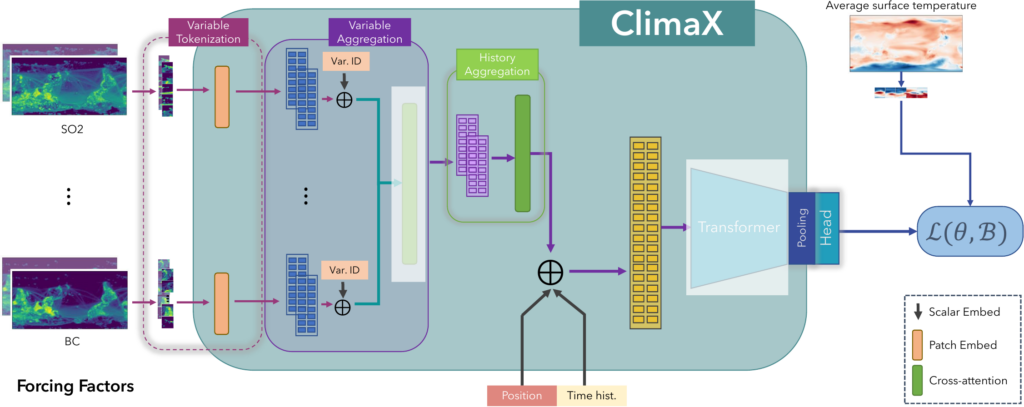
the token embedding layers, the variable aggregation module, the attention blocks, and the prediction head. If downstream variables overlap with pretraining variables, we can finetune the entire model. If variables are unseen during pretraining, we replace the embedding layers and the prediction head with newly initialized networks and either finetune or freeze the other two components.
Results highlights
Global weather forecasting
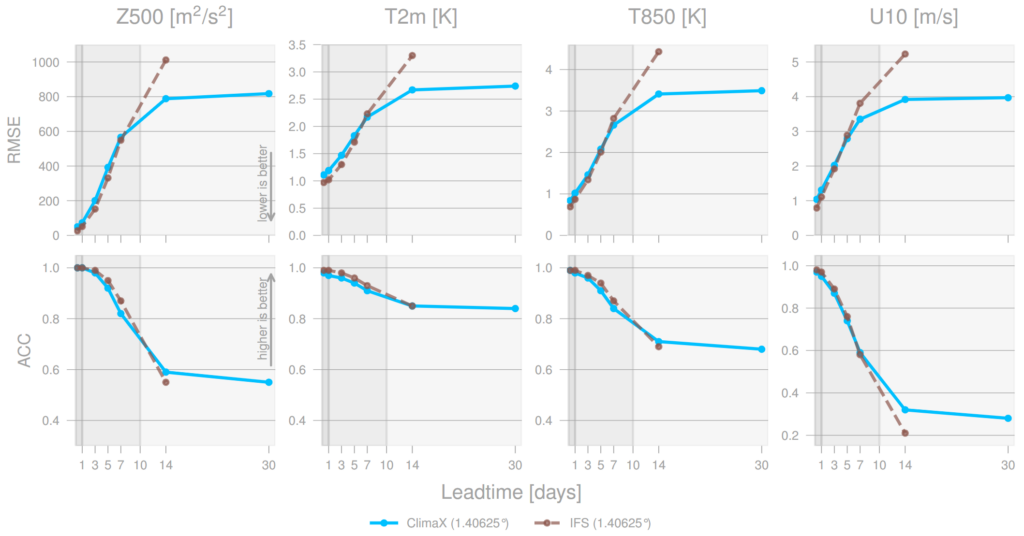
Forecasting the future values of key weather variables at different temporal horizons is critical to ensuring safety of communities and infrastructure around the world. ERA5 reanalysis data from European Center for Medium-range Weather Forecasting (ECMWF) underlies as the key source of data for training and evaluating machine learning models on this task with performance of Operation IFS being the current state-of-the art numerical weather prediction baseline.
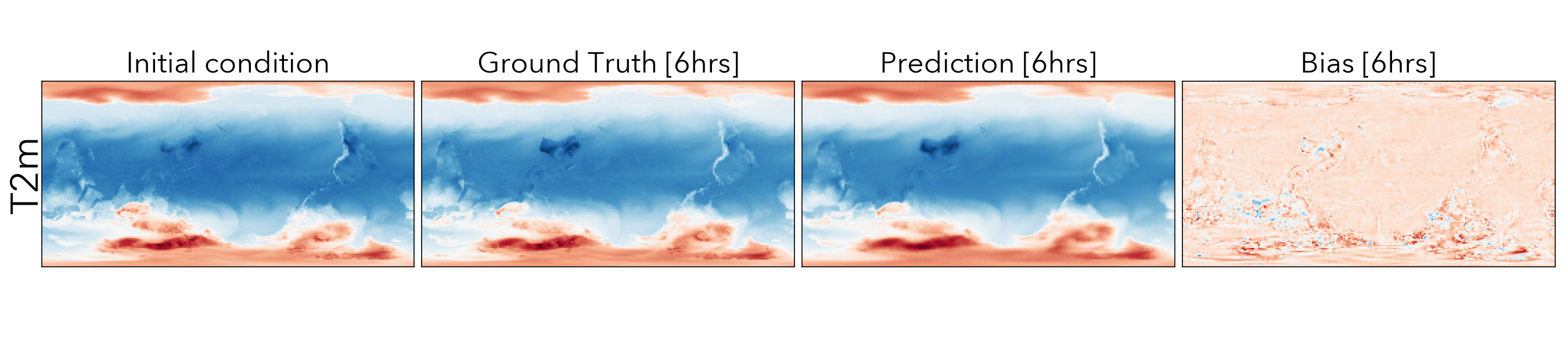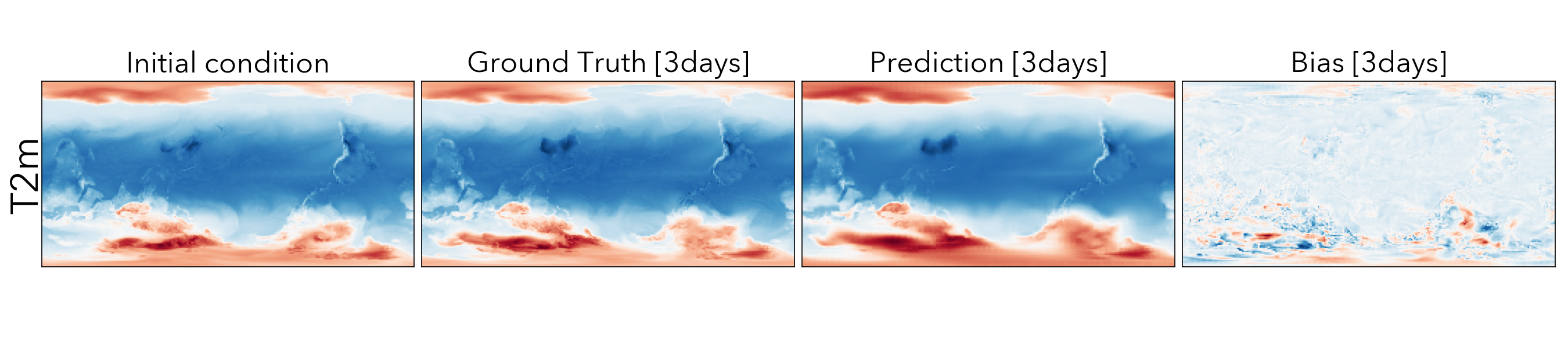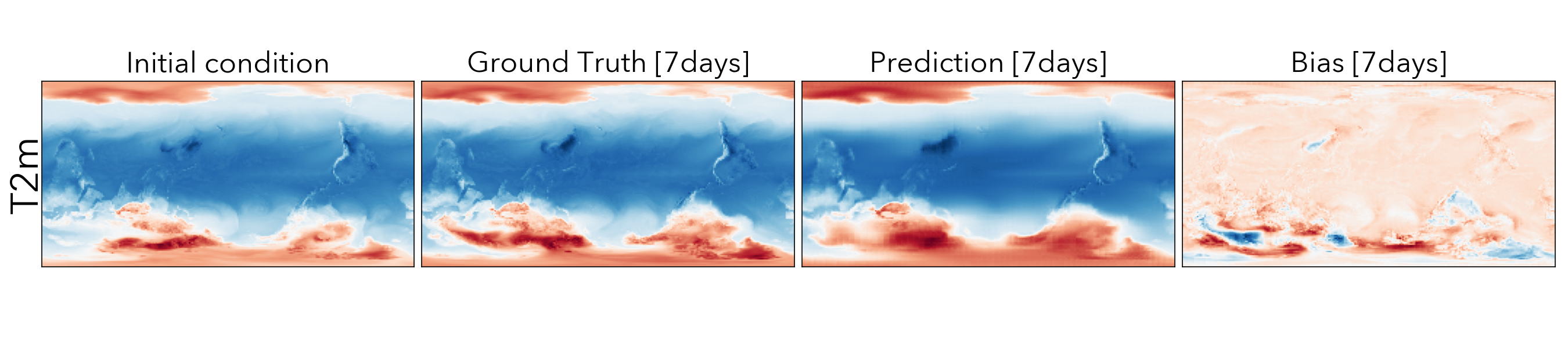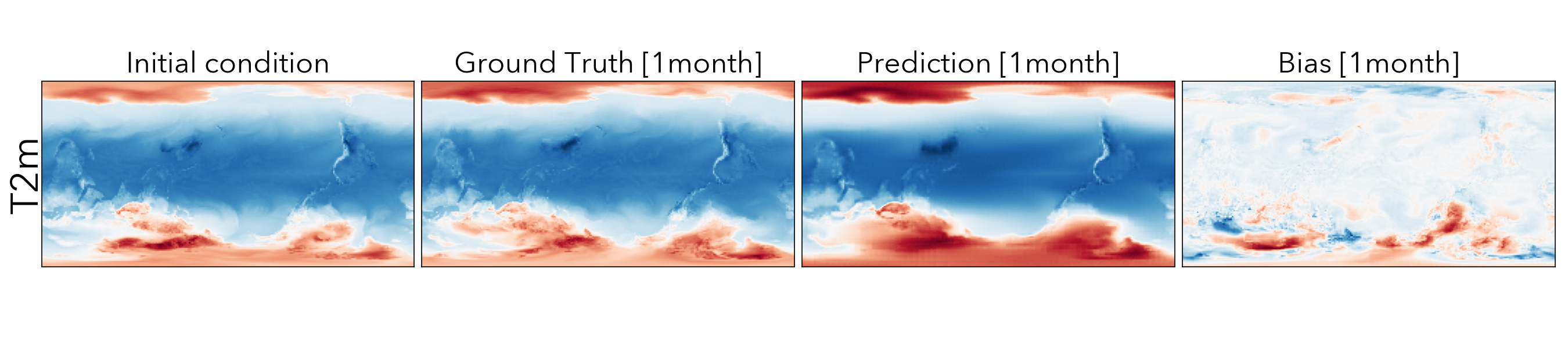
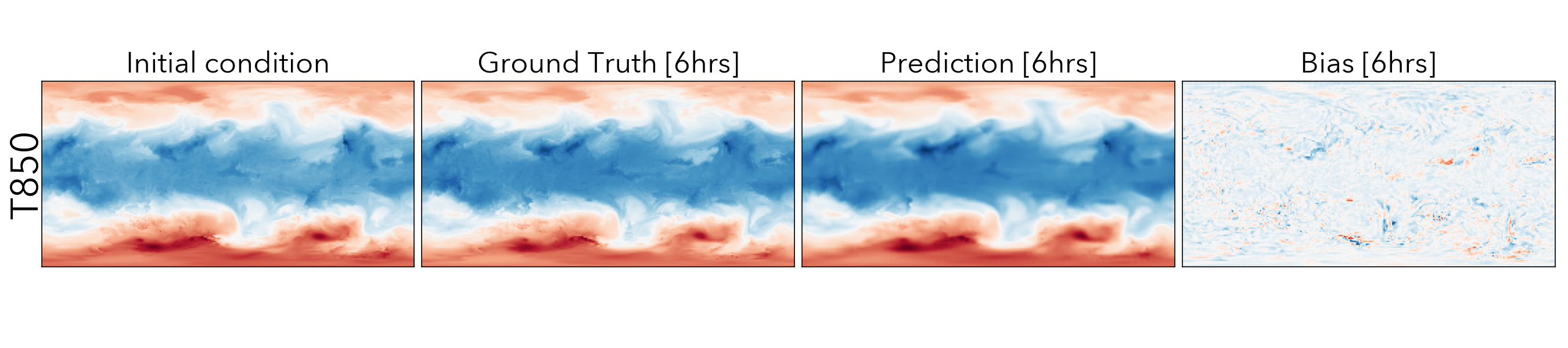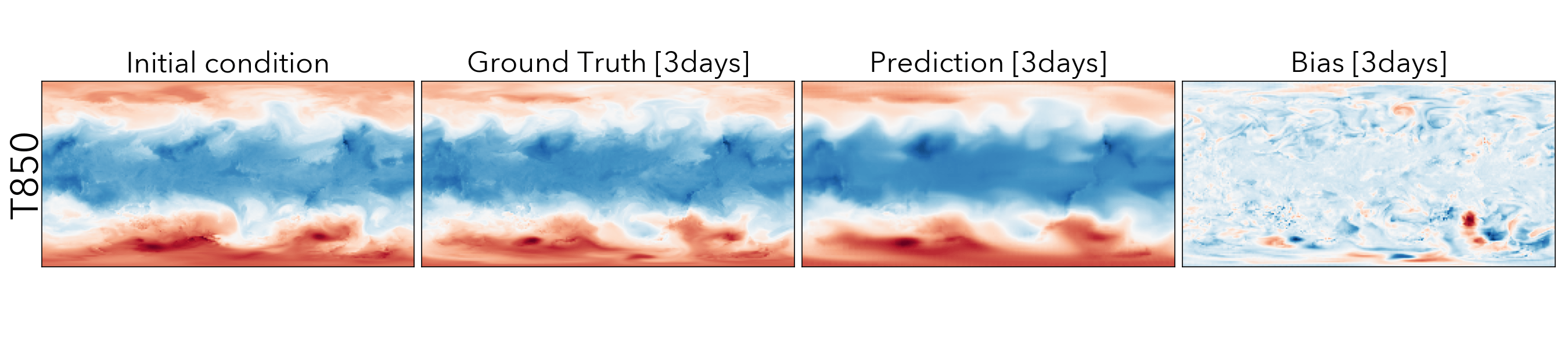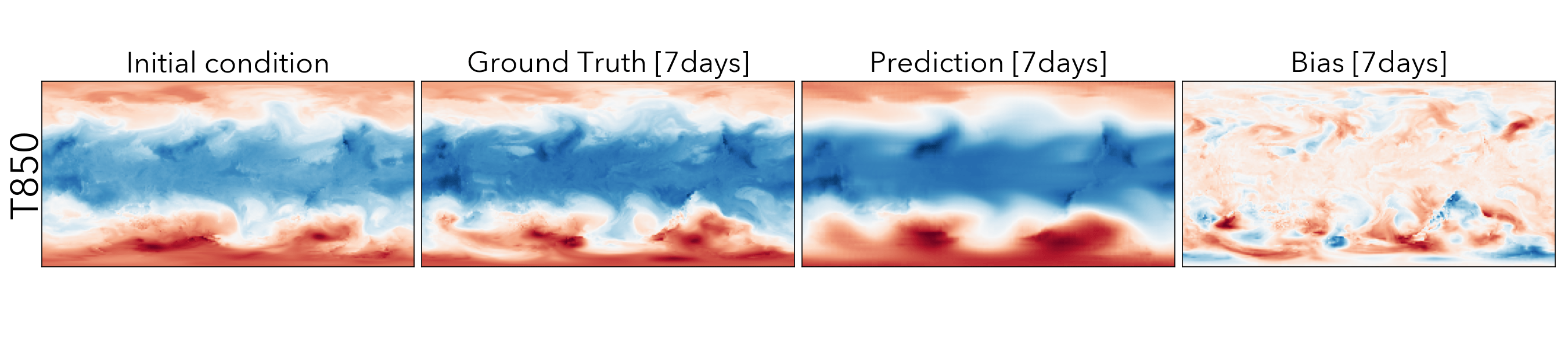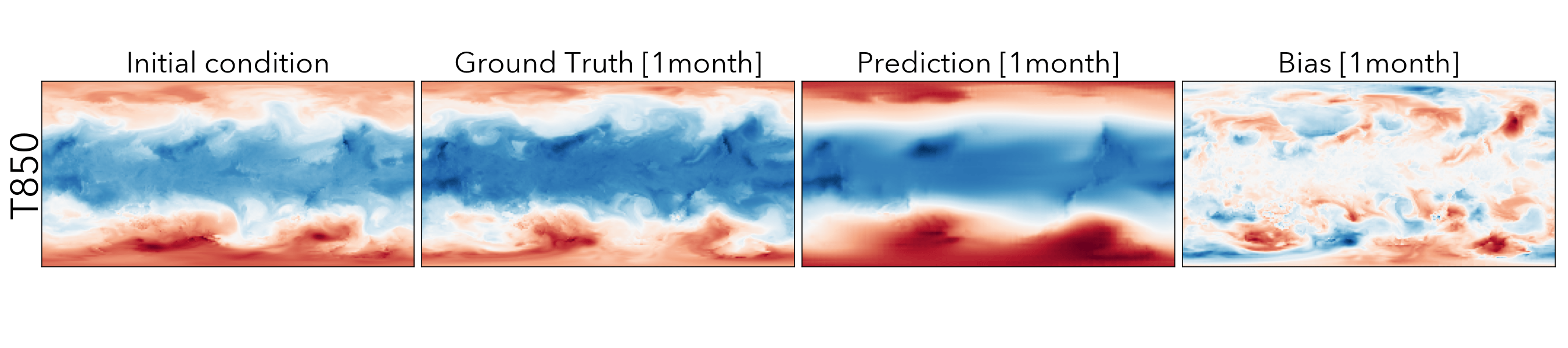
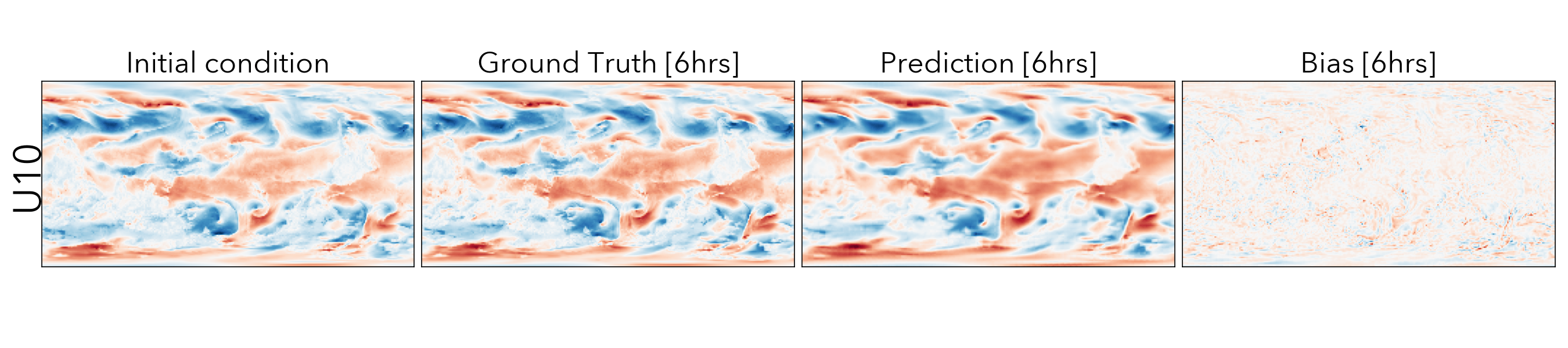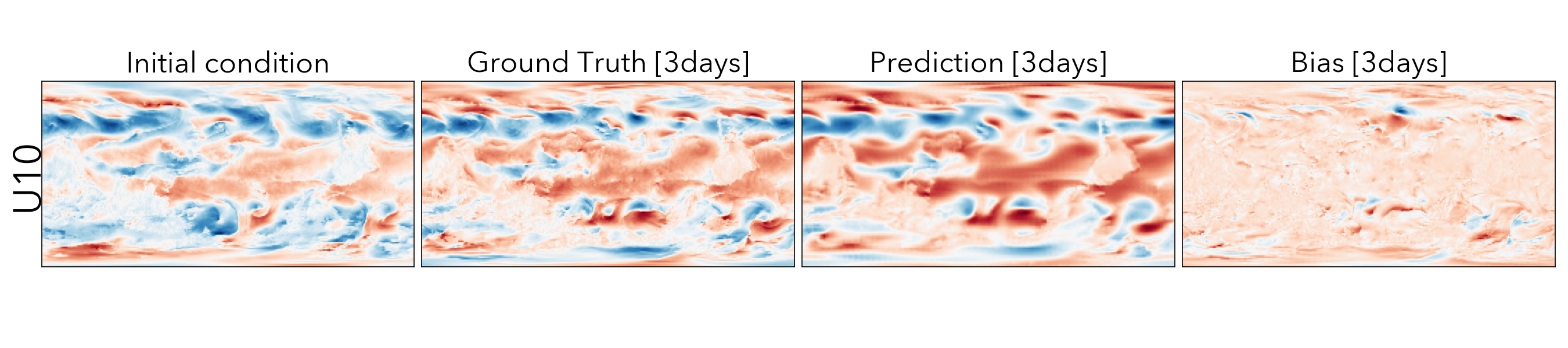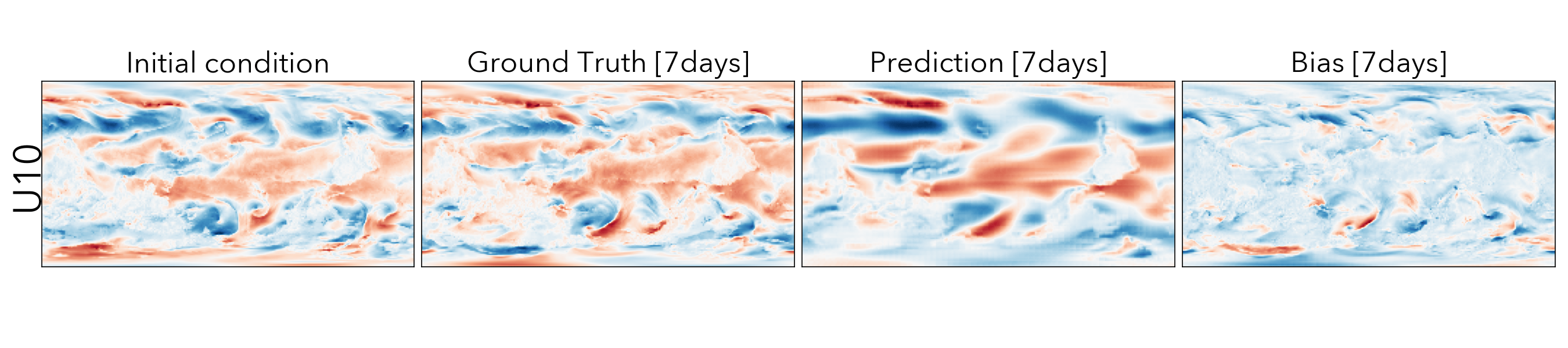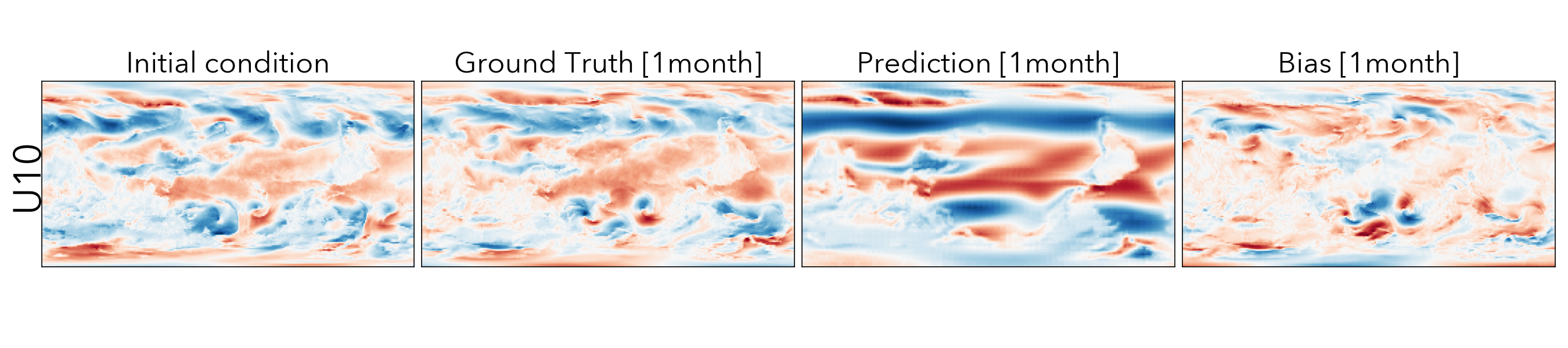
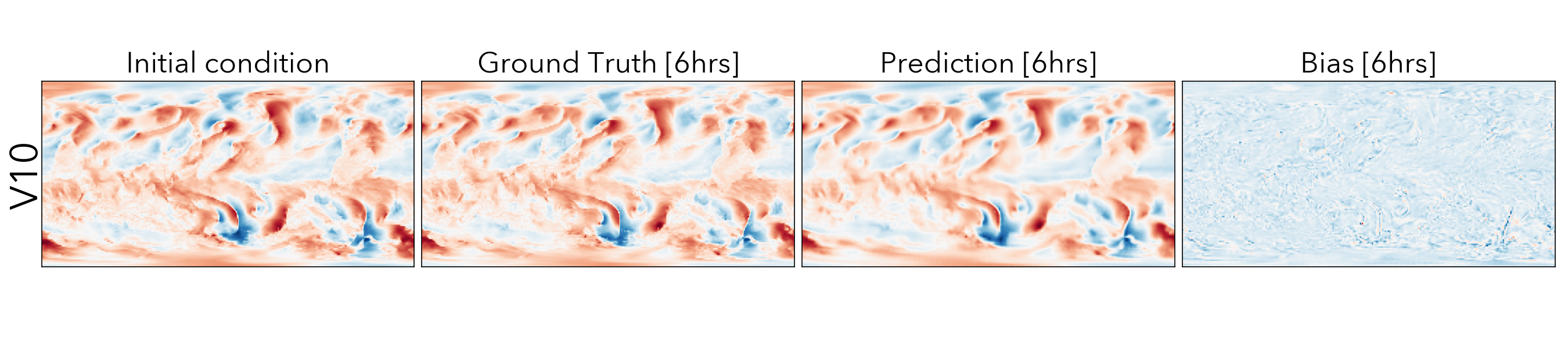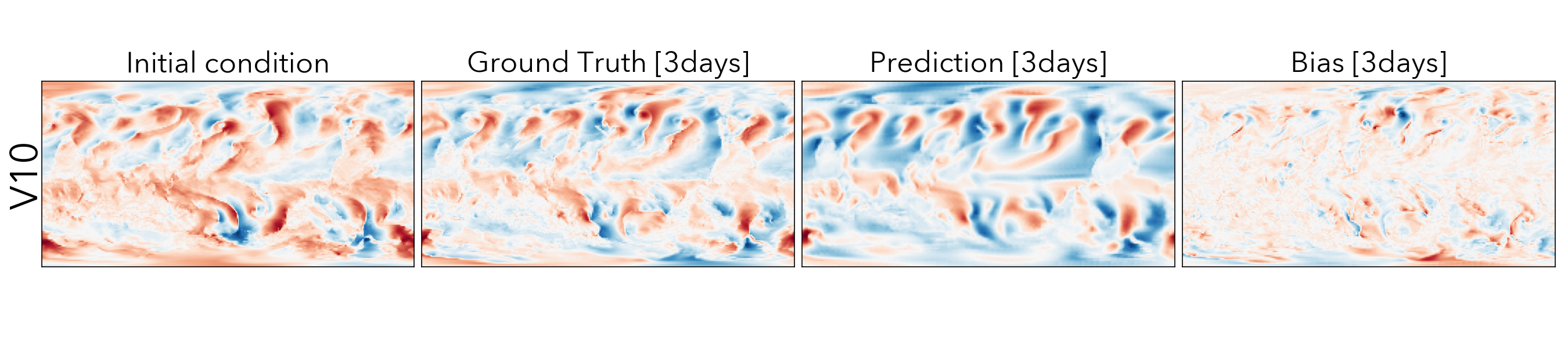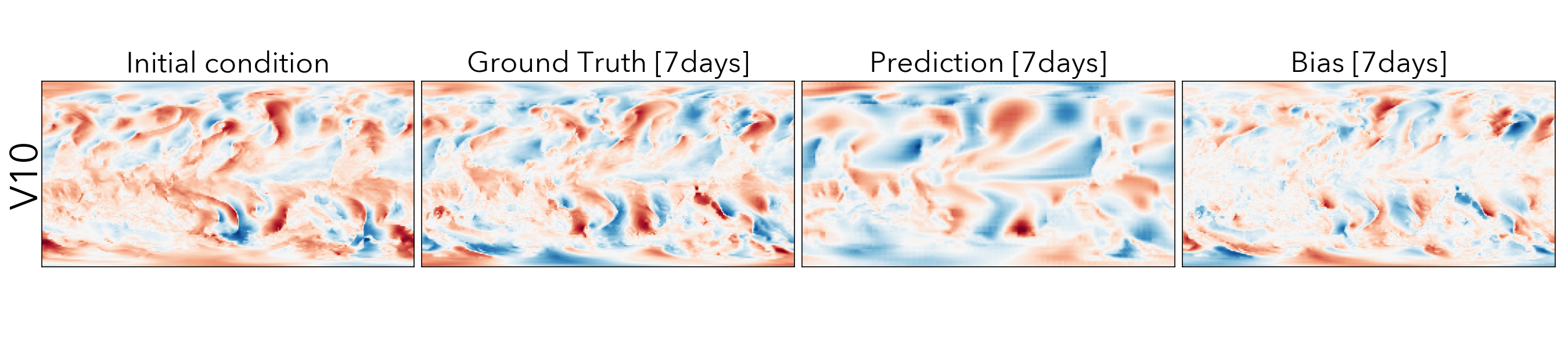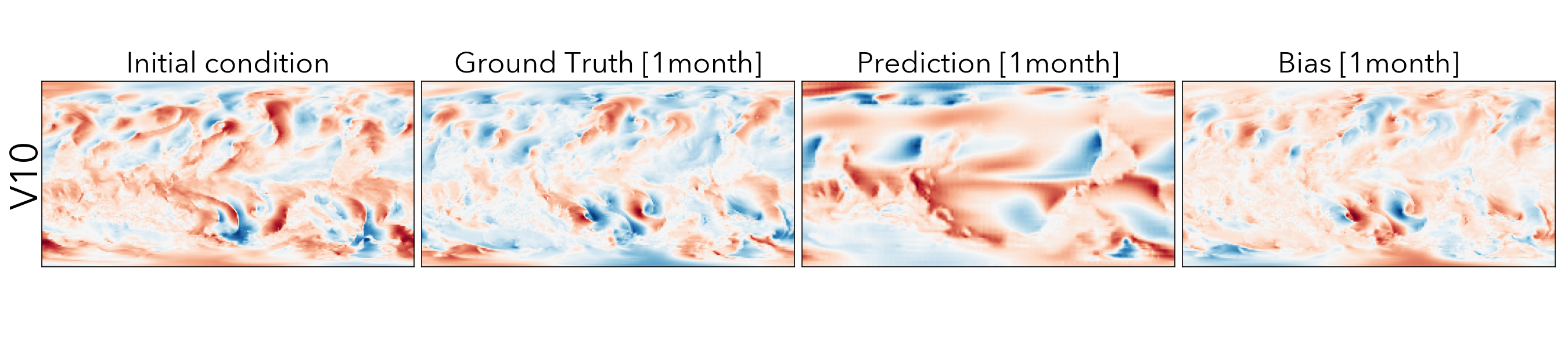
ClimaX when finetuned on the same ERA5 data, even at mediums resolutions (1.40625˚) already performs comparably, if not better than IFS on short and medium-range predictions, while being substantially better at longer horizon predictions.
Climate projections
Climate projections help climate scientists understand the effects of various forcing factors like concentrations of greenhouse gases or aerosol emissions to long term state of the climate. ClimateBench [1] was recently introduced to consistently evaluate machine learning approaches to improve the accuracy of climate projections. This task is noticeably different from the pretraining regime with completely different inputs and outputs than seen during pretraining. Still, transferring over ClimaX attention layers to this task, results in comparable or better performance than the current state-of-the-art baselines in ClimateBench.

Climate model downscaling
Climate models often can’t provide enough detail to analyze regional and local phenomena due to their coarser spatial resolutions. Downscaling can help provide higher-resolution climate projections and reduce the biases from the outputs of these models by relating them to higher resolution local climatological conditions. We evaluate ClimaX on this task by using lower resolution climate model’s projections as the input, and corresponding values in reanalysis weather data (opens in new tab) as the target at higher resolution. We find that ClimaX again compares favorably against other deep learning based baselines on all key metrics.



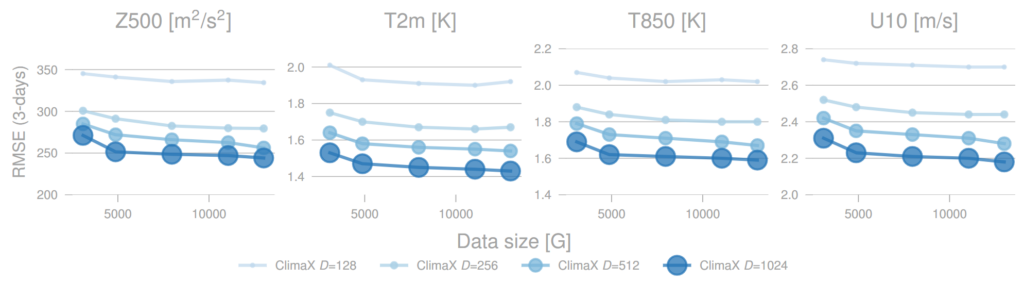
Scaling analysis
Transformer based machine learning architectures have found favorable and predictable scaling properties when given more compute, data, or parameters. We find this true for the ClimaX model as well. We find these trends promising as we have only scaled to fairly small models compared to the currently popular architectures in other domains with billions of parameters. Additionally, there’s a wealth of publicly available weather and climate data that we haven’t yet leveraged for pre-training larger models.
Advancing weather and climate modeling with data-driven methods
We are excited to release ClimaX with the aim of furthering data-driven weather and climate modeling. Our goal is to allow anyone to easily use the latest Machine Learning methods to address multitude of problems, ranging from near-term prediction at a local scale to modeling long-term processes that involve weather and climate variables. ClimaX takes a big step forward towards the idea of a single starting point for a variety of such tasks. We can’t wait to see what the future holds for this emerging field.
References
[1] Watson‐Parris, Duncan, et al. “ClimateBench v1. 0: A Benchmark for Data‐Driven Climate Projections.” Journal of Advances in Modeling Earth Systems 14.10 (2022): e2021MS002954.
[2] Eyring, Veronika, et al. “Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization.” Geoscientific Model Development 9.5 (2016): 1937-1958.
[3] Hersbach, H., et al. “ERA5 hourly data on single levels from 1979 to present.” Copernicus Climate Change Service (C3S) Climate Data Store (CDS) 10 (2018).
This work is being undertaken by members of Microsoft Autonomous Systems and Robotics Research (opens in new tab), Microsoft Research AI4Science (opens in new tab) & UCLA. The researchers behind this project are Tung Nguyen (opens in new tab), Johannes Brandstetter (opens in new tab), Ashish Kapoor (opens in new tab), Jayesh K. Gupta (opens in new tab), and Aditya Grover (opens in new tab).