
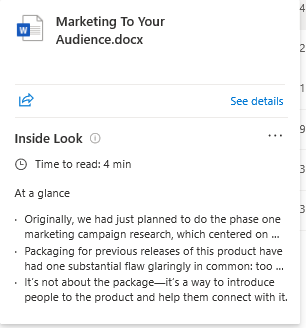
Figure 1: Inside Look preview for a document in Microsoft SharePoint
By Rahul Jha and Payal Bajaj
Knowledge workers spend close to 20% of their time searching for and gathering information (opens in new tab). When using document management systems such as Microsoft OneDrive and SharePoint people find themselves looking at directories full of documents. Interacting with such a list of documents can be time-consuming without a mechanism for previewing the documents.
The Inside Look (opens in new tab) feature in OneDrive and SharePoint helps people get to relevant documents quickly by providing a short summary of documents as previews (Figure 1). These summaries give the people a glimpse of the document content and help them decide quickly whether a document will be useful for their information need without opening the document.
Document summaries are distinguished as being either indicative or informative. Indicative summaries alert a person to the topic of the document and help them decide whether they should open it fully. Informative summaries, on the other hand, attempt to convey all the important points of a document so the person doesn’t need to open the original document [1]. Summaries can also be either extractive or abstractive. Extractive summaries only use original text from the document, while abstractive summaries can contain new text not originally in the document. We’ve formulated our solution of generating document previews for Inside Look as indicative, extractive summarization.
Our initial summarization models identified important sentences by using a set of cues based on the structure of the document, formatting information, as well as bag-of-words signals. We started with a rule-based model, followed by a ranking model [2] trained using data annotated by our hierarchical annotation methodology, Artemis. As shown in Figure 2, judges can use Artemis to build summaries in a bottom-up manner, starting by creating paragraph-level summaries and successively building higher level summaries by reusing sentences selected at earlier levels. We’ve described our annotation process in detail in this paper [3].
For the next iteration of our model, we turned to semantic, transformer-based language representations based on Microsoft Turing model for natural language representation (NLR) (opens in new tab). We experimented with a contextual transformer model based on BertSum [4] for scoring the sentences for Inside Look summaries. This model creates a representation for each sentence in the document based on its surrounding sentences, which is then used to assign a score to each sentence. This score is used as an additional feature in our ranking model, along with cues based on structure and formatting. Using the Microsoft Turing NLR-based large-scale models, we saw a 36% improvement in our offline relevance metrics.
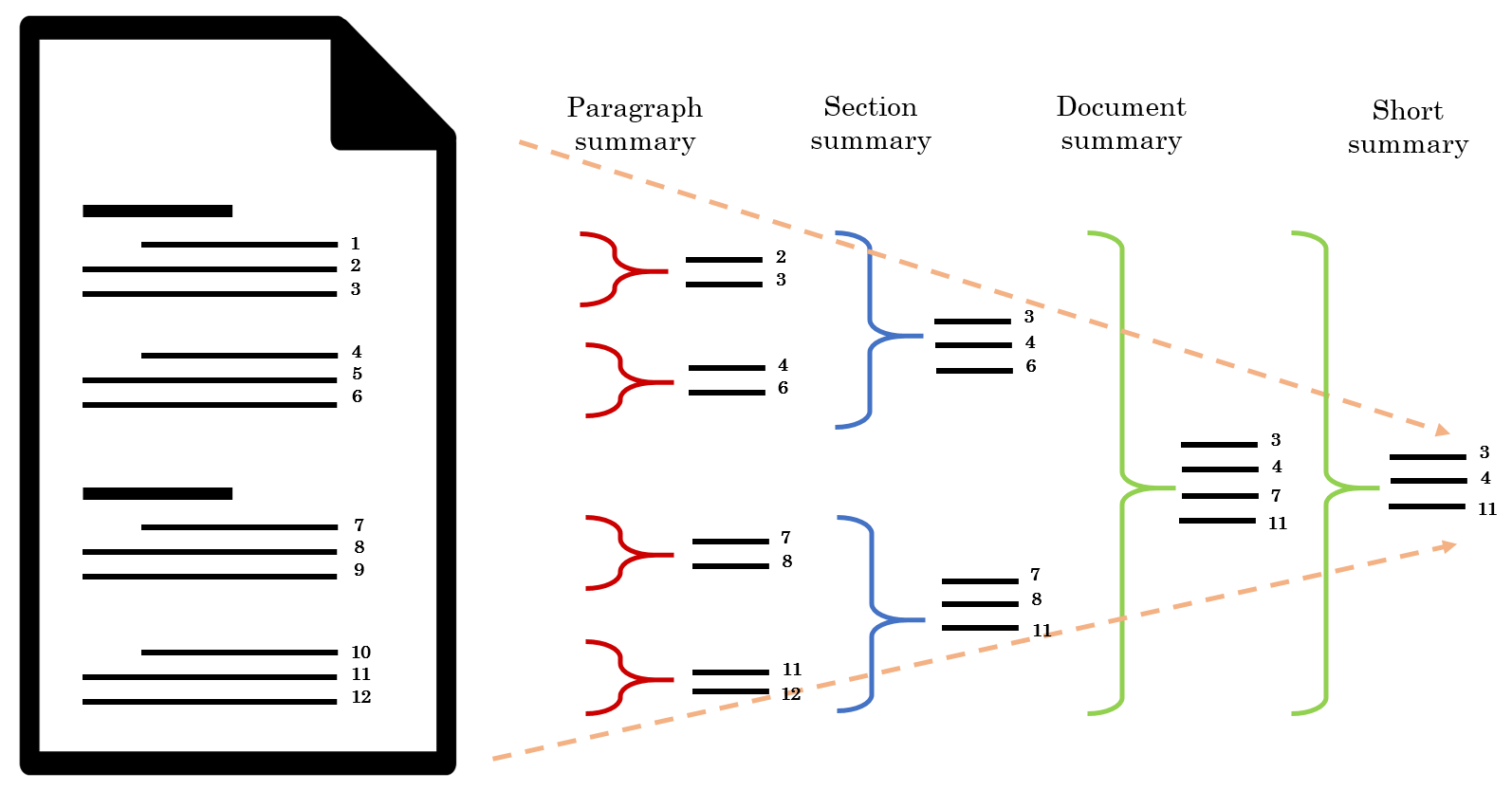
Figure 2: Our hierarchical annotation methodology, Artemis, described in more detail in [3]
After several rounds of model distillation and performance optimizations, we obtained a production-ready model with the desired relevance and performance characteristics. To help make the final ship decision, we conducted side-by-side evaluations where judges were shown summaries from our previous model and the Turing NLR-based model in random order and asked them which summary they preferred. In a side-by-side experiment conducted on more than 150 documents with 5 judges per document, we found that judges preferred Turing NLR based summaries 63% of the time, while they preferred summaries from our previous model only 22% of the time (there was no preference in 15% of the cases). These results were statistically significant. Based on all our evaluations, we shipped the Turing NLR-based models for the Inside Look feature early in 2020.
Qualitatively, summaries from the new model tend to be shorter, more focused, and more readable. For example, the figure below shows two summaries for the same technical document. The one on the left was generated by our earlier model, while the one on right is generated by our Turing NLR-based model. The summary from the earlier model starts with some disclaimer information and then moves to specific details about the topic in question without introducing the topic. The summary from the Turing NLR-based model introduces the main topic (Analysis Services) in the first sentence and provides the goal of the article in the second sentence. It is much more readable than the summary from our earlier model.
| Earlier model | Turing NLR-based model |

|

|
Similarly, the figure below shows summaries generated by the two models for a government document. The summary from our earlier model jumps quickly between topics and mentions VAWA without defining it. The Turing NLR-based summary is more focused and first defines the main topic, VAWA, along with its acronym expansion. It then provides some elaboration on the topic.
| Earlier model | Turing NLR-based model |

|

|
We are excited to see how the Inside Look feature helps people save time and get to the information they need quickly. Going forward, we plan to expand our use of AI at Scale (opens in new tab) to continue improving summary quality for Inside Look.
References
[1] Kan et al. (2002) Using the Annotated Bibliography as a Resource for Indicative Summarization (opens in new tab)
[2] Burges (2010) From RankNet to LambdaRank to LambdaMART: An Overview
[3] Jha et al. (2020) Artemis: A Novel Annotation Methodology for Single Document Indicative Summarization (opens in new tab)
[4] Liu and Lapata (2019) Text Summarization with Pretrained Encoders (opens in new tab)