Arista is a data-driven image annotation system, which annotates an image based on large-scale image search. Its assumption is that close similar images share similar semantics. It targets at a practical image annotation engine which is able to automatically annotate images of any popular concepts. Starting from 2006, Arista is now able to perform online tagging based on 2 billion web images leveraging near-duplicate detection technique.
The Key Idea
The key hinder factor of computer vision research such as object recognition, scene recognition, and image search, is the semantic gap between existing low-level visual features and high-level semantic concepts. Previous machine learning and computer vision approaches attempted to directly map visual features to textual keywords. Since these two types of features are heterogeneous, the intrinsic mapping function is totally in the dark.
On the contrary, Arista adopts a search-to-annotation strategy. Its motivation is simple – ideally, if we have all the images in the world as well as their tags on hand, then to annotate a new image, we can just find its duplications and use their tags to annotate this new image.
However, since we cannot have all the images, we can then search for a number of similar images instead, and mine relevant terms from their surrounding texts to tag a new image.
A large-scale intermediate image set (a group of visually close similar images) is the key to build the connections between images and terms. Contrary to the direct mapping strategy, since the retrieved similar images are partly labeled, they provide ground truth knowledge of the mapping between images and textual keywords. Therefore, the annotation problem in Arista is simplified as first to map between visual features, i.e. to measure the visual similarity of a query image against the intermediate dataset, and then to determine which keywords should be propagated to the query image. These are mappings with homogeneous features. Therefore, it greatly reduces the difficulty.
The Theoretical Explanation
Actually, image auto-tagging problem can be formulated as the Bayesian approach below:
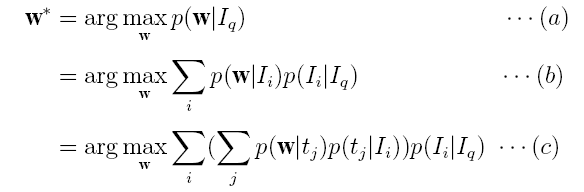
Recall that the goal of image auto-tagging is to select the terms w which have the largest probability of related to an image Iq , which gives Eq.(a). Based on the Bayesian inference, we obtain Eq.(b), which means that w* is jointly voted by the images Ii in the database, i.e. a term w is mostly probably selected to tag Iq if it is highly correlated with the images Ii which are highly relevant to the new image Iq. We further assume that each image has a number of topics tj and one topic is a word distribution. Therefore we obtain Eq.(c), which means that a term w is voted by the topics of those images that are the most relevant to Iq.
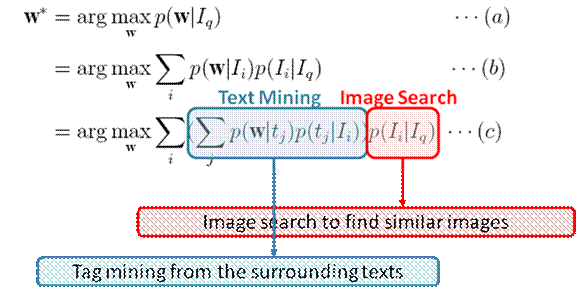
It is now easily see that why Arista adopts the search-to-annotation strategy that first search for close similar images and then mine relevant tags from the search results.
Background, Motivation and Basic Idea
The key hinder factor of computer vision research is the semantic gap between existing low-level visual features and high-level semantic concepts. Traditional image auto-annotation approaches attempted to directly map visual features to textual keywords. However, since these two types of features are heterogeneous, the intrinsic mapping function is totally in the dark.
Arista adopts a search-to-annotation strategy. Its basic idea is that close-similar images share similar semantics. Leveraging a large-scale partly annotated image database, it annotates an image by first search for a number of close-similar images in the content-based image retrieval framework, and then mine relevant terms/phrases from their surrounding texts. In this way, Arista avoids the semantic gap problem to a certain extent by measuring similarities in homogeneous feature spaces( i.e. image against image and text against text).

Background, Motivation and Basic Idea
The key hinder factor of computer vision research is the semantic gap between existing low-level visual features and high-level semantic concepts. Traditional image auto-annotation approaches attempted to directly map visual features to textual keywords. However, since these two types of features are heterogeneous, the intrinsic mapping function is totally in the dark.
Arista adopts a search-to-annotation strategy. Its basic idea is that close-similar images share similar semantics. Leveraging a large-scale partly annotated image database, it annotates an image by first search for a number of close-similar images in the content-based image retrieval framework, and then mine relevant terms/phrases from their surrounding texts. In this way, Arista avoids the semantic gap problem to a certain extent by measuring similarities in homogeneous feature spaces( i.e. image against image and text against text).
Challenges
Arista targets at a practical image annotation engine which is able to handle any images of popular concepts (i.e. we can find at least N images of a concept). To achieve this goal, the following challenges should be addressed:
– How to bridge the semantic gap
– How to select annotation vocabulary and find more meaningful keywords
– How to define a rejection scheme
– How to enable real-time image search on a web-scale image dataset
Research Roadmap
Starting from 2006, we have conducted a series of research work on Arista, addressing the challenges above. The timeline below illustrates our attempts:
– towards the feasibility of Arista (See “Query by Image+Keyword”, “Query by Image Only”). Particularly, in [Wang, CVPR’06], we first proposed Arista as a non-parametric image auto-annotation approach which annotates an image in a two-step fashion, i.e. search and then mining. We implemented a prototype system over 2.4 million images, called AnnoSearch, which requires an additional keyword to speed up the image search process and reduce the semantic gap. Soon after that, we developed the second system which only requires an image query and is capable of searching from 2.4 million images in real time [Li, MM’06].
– towards a better text mining approach, including annotation refinement, annotation vocabulary selection, and annotation rejection (See “Improve Mining” & [Lu, CVPR’07]). It could be advantageous if a dedicated approach could refine the annotation results. Therefore, [Wang, MM’06] proposed an image annotation refinement approach using random walk with restarts. The authors further investigated the same problem in [Wang, CVPR’07] and [Wang, CIVR’08] in which Markov processes were proposed and further improved the annotation performance.
– towards bridging the semantic gap (See “Improve Search”). This line of research investigates ways of improving image search results so that semantically similar images can be retrieved which will definitely improve annotation precision. [Lu, CVPR’07] first divide-and-conquered this problem by developing a lexicon of high-level image concepts with small semantic gaps which is helpful for people to focus for data collection, annotation and modeling. [Wang, SIGIR’08], on the other hand, studied better distance measure on images by reinforcing textual and visual features.
– towards the value of a real web-scale dataset (See “Scale-up Database to 2B Images”). Such nonparametric ways of image annotation as Arista has attracted many research efforts. People have realized the value of a large-scale partial-labeled image dataset on image annotation. Collaborating with the Bing Multimedia Search team, we enabled real-time image annotation on 2 Billion images [Wang, CVPR’10], which is the first time a real web-scale image dataset was used for image annotation. This work attempted to answer following questions: 1) the coverage of image concepts by using the search-to-annotation techniques; 2) the annotation performance; and 3) the maximum scale of dataset so that its further expansion does not necessarily mean better annotation precision. However, due to system issue, this work is based on near-duplicate detection techniques, which means that it only partily answered the questions above and leaves the room for our future work.

Publications
· [Wang, CVPR’10] Xin-Jing Wang, Lei Zhang, Ming Liu, Yi Li, Wei-Ying Ma. ARISTA – Image Search to Annotation on Billions of Web Photos (opens in new tab), IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2010.
· [Lu, T-MM’09] Yijuan Lu, Jiemin Liu, and Qi Tian, and Lei Zhang, LCSS: Lexica of High-Level Concepts with Small Semantic Gaps, accepted by IEEE Transaction on Multimedia, 2009
· [Wang, T-PAMI’08] Xin-Jing Wang, Lei Zhang, Xirong Li, Wei-Ying Ma, Annotating Images by Mining Image Search Results (opens in new tab), IEEE Trans. Pattern Analysis and Machine Intelligence Special Issue (TPAMI), 2008.
· [Wang, SIGIR’08] Changhu Wang, Lei Zhang, Hong-Jiang Zhang. Learning to Reduce the Semantic Gap in Web Image Retrieval and Annotation (opens in new tab), in Proc. of the 31st Annual International ACM SIGIR Conference on Research & Development on Information Retrieval (SIGIR), Singapore, July 2008.
· [Wang, CIVR’08] Changhu Wang, Lei Zhang, Hong-Jiang Zhang. Scalable Markov Model-Based Image Annotation (opens in new tab), in Proc. of ACM International Conference on Image and Video Retrieval (CIVR), Niagara Falls, Canada, July 2008.
· [Wang, MMSJ’08] Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang. Scalabel Search-based Image Annotation (opens in new tab), in Multimedia Systems, June 14, 2008. ISSN: 0942-4962 (Print) 1432-1882 (Online).
· [Lu, CVPR’07] Yijuan Lu, Lei Zhang, Qi Tian, Wei-Ying Ma, What Are the High-Level Concepts with Small Semantic Gaps? (opens in new tab) in Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, USA, June, 2007
· [Li, MM’07] Xirong Li, Xin-Jing Wang, Changhu Wang, Lei Zhang, SBIA: Search-based Image Annotation by Leveraging Web-Scale Images (opens in new tab) (Demo), in Proc. ACM Multimedia, Augsburg, Germany, September, 2007.
· [Wang, CVPR’07] Changhu Wang, Feng Jing, Lei Zhang, and Hong-Jiang Zhang, Content-Based Image Annotation Refinement (opens in new tab), in Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, USA, June, 2007.
· [Wang, MM’06] Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang. Image Annotation Refinement using Random Walk with Restarts (opens in new tab), in Proc. of ACM International Conference on Multimedia (ACM MM), Santa Barbara, USA, October 2006.
· [Li, MM’06] Xirong Li, Le Chen, Lei Zhang, Fuzong Lin, Wei-Ying Ma, Image Annotation by Large-Scale Content-based Image Retrieval (opens in new tab), in Proc. ACM Multimedia, Santa Barbara, USA, October, 2006.
· [Wang, MIR’06] Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang, Scalable Search-Based Image Annotation of Personal Images (opens in new tab), in Proc. ACM SIGMM International Workshop on Multimedia Information Retrieval (MIR), 2006
· [Wang, CVPR’06] Xin-Jing Wang, Lei Zhang, Feng Jing, Wei-Ying Ma, AnnoSearch: Image Auto-Annotation by Search (opens in new tab), in Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), New York, USA, June, 2006
· [Wang, WWW’06] Xin-Jing Wang, Lei Zhang, Feng Jing, Wei-Ying Ma, Image Annotation Using Search and Mining Technologies (opens in new tab), in Proc. The 15th International World Wide Web Conference (WWW), Edinburgh, Scotland, May, 2006 (Best Poster Award (opens in new tab))
· [Zhang, MM’06] Lei Zhang, Le Chen, Feng Jing, Defeng Deng, Wei-Ying Ma, EnjoyPhoto: A Vertical Image Search Engine for Enjoying High-Quality Photos (opens in new tab), in Proc. ACM Multimedia, Santa Barbara, USA, October, 2006
The Framework
The framework of Arista 1.0 is shown in Figure 1. It supports two types of inputs: an image, or an image with a keyword. Figure 2 highlights the modules of the entire process.

Figure 1. Framework of Arista.

Figure 2. Modules of Arista.
– Input is an image
When only an image is the input, we tag it in the following steps:
1) extract a number of visual features such as color, texture, etc.
2) do content-based image search in the 2.4 million image database which output a few visually similar images
3) select the top N image search results
3) mine candidate key phrases from the surrounding texts of the selected image search results, using a label-based clustering method called SRC (Search Result Clustering)
4) score each candidate key phrase
5) reject those candidate key phrases whose score are below a certain threshold and output the rest.
– Input is an image and a keyword
This method is very useful for auto-tagging 1) Web images since they generally have surrounding texts, and 2) desktop images since generally they have a folder name. In this case, we suggest complemental annotations in the following steps:
1) do text-based search on the 2.4M image database, using the input keyword as a query
2) extract a number of visual features from the input image such as color, texture, etc.
3) do content-based re-ranking based on the text-search results
4) select the top N image search results
5) mine candidate key phrases from the surrounding texts of the selected image search results, using a label-based clustering method called SRC (Search Result Clustering)
6) score each candidate key phrase
7) reject those candidate key phrases whose score are below a certain threshold and output the rest.
Example Output
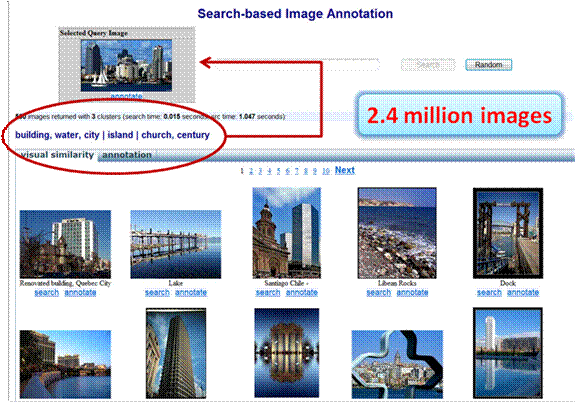
Figure 3. An example of Arista1.0 System UI. The query image is shown in the top-left corner, highlighted with “Selected Query Image”. The suggested tags are “building, water, city | island | church, century”. The bottom shown the visual search result from whose surrounding texts the suggested tags are discovered.
Below shows a few more examples of Arista1.0 output:

Figure 4. Arista 1.0 outputs. A query is an image as well as a keyword; this keyword is related to the image’s semantics but may not indicate the concept of the key object. The query keyword is bold-faced, while terms of normal font are the suggested annotations.
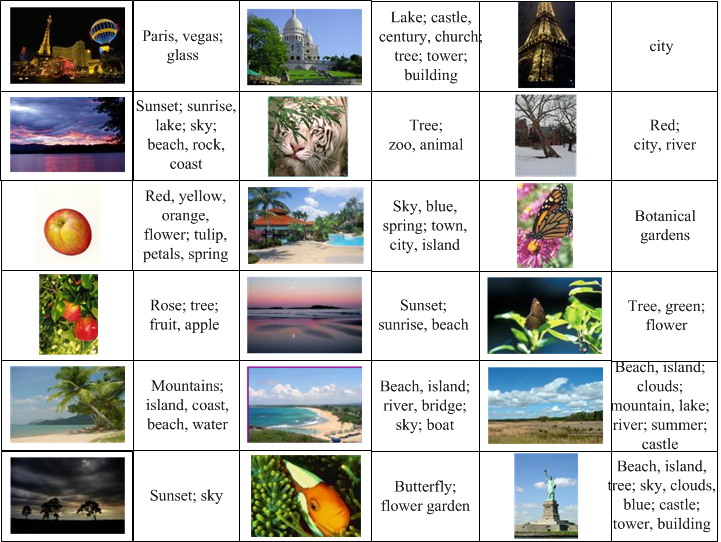
Figure 5. Arista 1.0 outputs. In this case, a query is an image only. Although the semantic gap problem degrades the performance, satisfying results were still achieved.
Related Publications
· Xin-Jing Wang, Lei Zhang, Xirong Li, Wei-Ying Ma, Annotating Images by Mining Image Search Results (opens in new tab), IEEE Trans. Pattern Analysis and Machine Intelligence Special Issue (TPAMI), 2008.
· Changhu Wang, Lei Zhang, Hong-Jiang Zhang. Learning to Reduce the Semantic Gap in Web Image Retrieval and Annotation (opens in new tab), in Proc. of the 31st Annual International ACM SIGIR Conference on Research & Development on Information Retrieval (SIGIR), Singapore, July 2008.
· Changhu Wang, Lei Zhang, Hong-Jiang Zhang. Scalable Markov Model-Based Image Annotation (opens in new tab), in Proc. of ACM International Conference on Image and Video Retrieval (CIVR), Niagara Falls, Canada, July 2008.
· Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang. Scalabel Search-based Image Annotation (opens in new tab), in Multimedia Systems, June 14, 2008. ISSN: 0942-4962 (Print) 1432-1882 (Online).
· Xirong Li, Xin-Jing Wang, Changhu Wang, Lei Zhang, SBIA: Search-based Image Annotation by Leveraging Web-Scale Images (opens in new tab) (Demo), in Proc. ACM Multimedia, Augsburg, Germany, September, 2007.
· Changhu Wang, Feng Jing, Lei Zhang, and Hong-Jiang Zhang, Content-Based Image Annotation Refinement (opens in new tab), in Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, USA, June, 2007.
· Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang. Image Annotation Refinement using Random Walk with Restarts (opens in new tab), in Proc. of ACM International Conference on Multimedia (ACM MM), Santa Barbara, USA, October 2006.
Brief Introduction
Arista 2.0 is a practical image auto-tagging system built upon real web-scale image dataset (2 billion). It targets at online-tagging of images of popular concepts, i.e. images which have near-duplicates.
The reason of tackling duplicated images first is twofold:
Firstly, near-duplicate detection is a well-defined problem and we have techniques of online detection.
Secondly, near-duplicate-based annotation approach can address many difficult concepts, which cannot be effectively handled by traditional object recognition approaches. Examples of such concepts are celebrity, logo, prod-uct, landmark, poster, pattern, etc., which are popular concepts and are more likely to be duplicated.
The future version of Arista will address the rest of images which do not have enough near-duplicates.
The Framework
The framework of Arista 2.0 is illustrated in Figure 1. Given a query image, its near-duplicate images is detected in real-time (We are able to detect one near duplicate in 70 milliseconds on average). Data mining techniques are then applied onto the surrounding texts of the near-duplicates, which identifies the salient terms or phrases as the annotations of the query image.
Figure 1. The framework of Arista2.0, which is based on 2 billion web images and near-duplicate detection technique.
Intuitively, when an image is duplicated in multiple webpages, the author of a webpage will attach his/her own words to the near duplicate. Though different surrounding texts are associated with each near duplicate, the most important (and correct) terms to an image are very likely to be repeated among the majority of its near duplicates, and thus can be detected to annotate this image. Figure 2 shows a few examples.
Since the common terms of near-duplicates are generally semantically specific, Arista 2.0 thus is able to output very specific annotations. This is in contrast to most existing works that tend to generate general terms like sky, city, etc.

Figure 2. Examples showing that surrounding texts of near-duplicates have common terms which hit the semantics of a query image. The tags inside the image blocks are our annotation outputs. The common terms of each near-duplicate are highlighted in bold.
Performance
We found that about 8.1% web images have more than ten near-duplicate and the number increases to 28.5% for top images in search results. Further, based on random samples in the latter case, we observed the precision of 57.9% at the point of the highest recall of 28% on ground truth tags.
Figure 3 shows the curves of average precision and average recall of Arista 2.0 on four query set: top queries obtained from query log, random queries obtained from query log, and animal and landmark queries from some public websites. SRC and majority voting techniques are leveraged separately as the data mining techniques. Details please refer to our CVPR’2010 publication.
Figure 3. The effects of dataset size (2.4million ~ 2 billion). Solid lines show the average precision/recall of using SRC, and dotted lines are of Majority Voting. The average precision performance converges when the DB size increased to 300 million, while average recall is still improving.
A few examples of the query images and their detected tags are shown in Figure 4 along with the increased dataset size. It suggests that 1) Arista 2.0 is able to detect very specific annotations to tag an image, and 2) larger dataset size ensures more accurate tags.
Figure 4. Annotation examples vs. dataset size. Bold-faced tags are perfect terms labeled by human subjects and italic ones are correct terms. Due to space limit, only the top five tags are shown. This figure suggests that larger dataset size ensures more accurate tags.
Publications
Xin-Jing Wang, Lei Zhang, Ming Liu, Yi Li, Wei-Ying Ma. ARISTA – Image Search to Annotation on Billions of Web Photos (opens in new tab), IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2010.
· Xin-Jing Wang, Lei Zhang, Ming Liu, Yi Li, Wei-Ying Ma. ARISTA – Image Search to Annotation on Billions of Web Photos (opens in new tab), IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2010.
· Yijuan Lu, Jiemin Liu, and Qi Tian, and Lei Zhang, LCSS: Lexica of High-Level Concepts with Small Semantic Gaps, accepted by IEEE Transaction on Multimedia, 2009
· Xin-Jing Wang, Lei Zhang, Xirong Li, Wei-Ying Ma, Annotating Images by Mining Image Search Results (opens in new tab), IEEE Trans. Pattern Analysis and Machine Intelligence Special Issue (TPAMI), 2008.
· Changhu Wang, Lei Zhang, Hong-Jiang Zhang. Learning to Reduce the Semantic Gap in Web Image Retrieval and Annotation (opens in new tab), in Proc. of the 31st Annual International ACM SIGIR Conference on Research & Development on Information Retrieval (SIGIR), Singapore, July 2008.
· Changhu Wang, Lei Zhang, Hong-Jiang Zhang. Scalable Markov Model-Based Image Annotation (opens in new tab), in Proc. of ACM International Conference on Image and Video Retrieval (CIVR), Niagara Falls, Canada, July 2008.
· Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang. Scalabel Search-based Image Annotation (opens in new tab), in Multimedia Systems, June 14, 2008. ISSN: 0942-4962 (Print) 1432-1882 (Online).
· Yijuan Lu, Lei Zhang, Qi Tian, Wei-Ying Ma, What Are the High-Level Concepts with Small Semantic Gaps? (opens in new tab) in Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, USA, June, 2007
· Xirong Li, Xin-Jing Wang, Changhu Wang, Lei Zhang, SBIA: Search-based Image Annotation by Leveraging Web-Scale Images (opens in new tab) (Demo), in Proc. ACM Multimedia, Augsburg, Germany, September, 2007.
· Changhu Wang, Feng Jing, Lei Zhang, and Hong-Jiang Zhang, Content-Based Image Annotation Refinement (opens in new tab), in Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, USA, June, 2007.
· Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang. Image Annotation Refinement using Random Walk with Restarts (opens in new tab), in Proc. of ACM International Conference on Multimedia (ACM MM), Santa Barbara, USA, October 2006.
· Xirong Li, Le Chen, Lei Zhang, Fuzong Lin, Wei-Ying Ma, Image Annotation by Large-Scale Content-based Image Retrieval (opens in new tab), in Proc. ACM Multimedia, Santa Barbara, USA, October, 2006.
· Changhu Wang, Feng Jing, Lei Zhang, Hong-Jiang Zhang, Scalable Search-Based Image Annotation of Personal Images (opens in new tab), in Proc. ACM SIGMM International Workshop on Multimedia Information Retrieval (MIR), 2006
· Xin-Jing Wang, Lei Zhang, Feng Jing, Wei-Ying Ma, AnnoSearch: Image Auto-Annotation by Search (opens in new tab), in Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), New York, USA, June, 2006
· Xin-Jing Wang, Lei Zhang, Feng Jing, Wei-Ying Ma, Image Annotation Using Search and Mining Technologies (opens in new tab), in Proc. The 15th International World Wide Web Conference (WWW), Edinburgh, Scotland, May, 2006 (Best Poster Award (opens in new tab))
· Lei Zhang, Le Chen, Feng Jing, Defeng Deng, Wei-Ying Ma, EnjoyPhoto: A Vertical Image Search Engine for Enjoying High-Quality Photos (opens in new tab), in Proc. ACM Multimedia, Santa Barbara, USA, October, 2006
Opens in a new tab
