
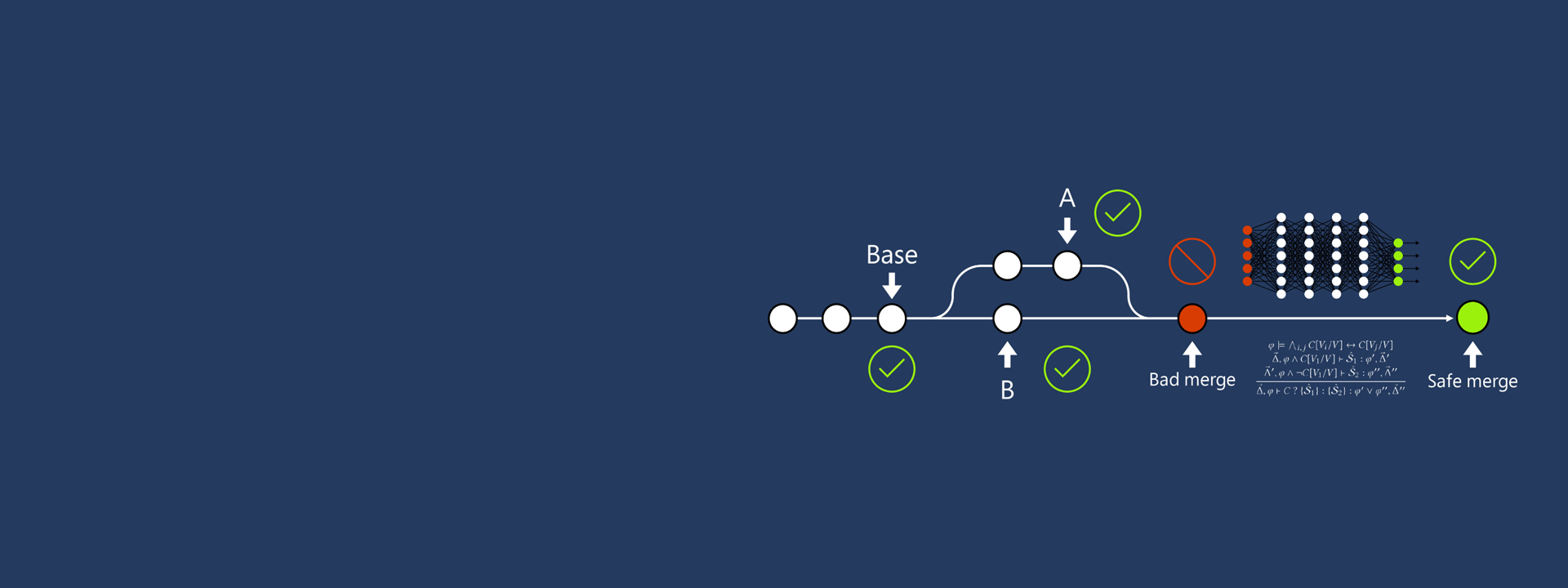
Future of Program Merge
Collaborative software development leveraging version control such as git relies on three-way merge (opens in new tab) as the mechanism for integrating changes from individual contributors. But with so many people independently altering code, it’s unsurprising that updates don’t always synchronize, resulting in bad merges. Bad merges can take a range of forms. For example, textual merge conflicts occur when the changes from two branches can’t be integrated by the default text-based merge algorithms used by version control systems such as Git, Concurrent Versions System (CVS), and Subversion. Most such conflicts are spurious from the perspective of their effect on program execution and often originate from the use of a 40-year-old diff3 algorithm (opens in new tab) for merging text that is unaware of the syntax and semantics of programming languages. Such instances prevent developers from checking in their code, requiring them to manually fix the conflict or, if the solution is ambiguous, to consult with other developers. In other cases, bad program merges can be more subtle and costly, introducing semantic merge conflicts that may either fail the compiler, break a test, or—worse—introduce a regression. Bad merges constitute between 10 percent and 20 percent of all merges for large projects (opens in new tab) and collectively result in stalled pull requests, failed continuous integration runs, or bugs in deployment, including exploitable security vulnerabilities (opens in new tab). Coping with bad merges, which could delay development anywhere from hours to days or impact customer trust in a product, is one of the well-known pain points (opens in new tab) in collaborative software development and, additionally, often discourages less experienced developers from making meaningful contributions to large open-source projects.
In this project we are revisiting the problem of safe program merge and conducting research towards eliminating bad merges (including merge conflicts) of any form by exploring and combining techniques from program verification (for precise formulation of correctness), program synthesis (for automating repeated edits) and machine learning (that includes leveraging pre-trained large language models).